Reinforcement Learning Meets Large Language Models: A Survey of Advancements and Applications Across the LLM Lifecycle
作者: Keliang Liu, Dingkang Yang, Ziyun Qian, Weijie Yin, Yuchi Wang, Hongsheng Li, Jun Liu, Peng Zhai, Yang Liu, Lihua Zhang
分类: cs.CL
发布日期: 2025-09-20
备注: A Survey of Reinforcement Learning for Large Language Models
💡 一句话要点
综述:强化学习赋能大语言模型全生命周期,提升推理与对齐性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 对齐微调 强化推理 奖励函数
📋 核心要点
- 现有关于强化学习增强大语言模型的综述缺乏对LLM全生命周期的覆盖,未能系统性地阐述RL在各个阶段的作用。
- 本文全面回顾了RL在LLM预训练、对齐微调和强化推理等阶段的应用策略,重点关注RL在提升模型推理能力方面的作用。
- 本文整理了RL微调所需的数据集、评估基准、开源工具和训练框架,并分析了未来挑战和趋势,为研究人员提供参考。
📝 摘要(中文)
近年来,以强化学习(RL)为中心的训练方法显著增强了大语言模型(LLM)的推理和对齐性能,特别是在理解人类意图、遵循用户指令和增强推理能力方面。虽然现有的综述提供了关于RL增强LLM的概述,但它们的范围通常有限,未能全面总结RL如何在LLM的整个生命周期中运作。本文系统地回顾了RL赋能LLM的理论和实践进展,特别是具有可验证奖励的强化学习(RLVR)。首先,简要介绍了RL的基本理论。其次,详细阐述了RL在LLM生命周期的各个阶段的应用策略,包括预训练、对齐微调和强化推理。特别强调,强化推理阶段的RL方法是推动模型推理能力达到极限的关键驱动力。接下来,整理了目前用于RL微调的现有数据集和评估基准,涵盖人工标注数据集、AI辅助偏好数据和程序验证风格的语料库。随后,回顾了主流的开源工具和训练框架,为后续研究提供清晰的实践参考。最后,分析了RL增强LLM领域未来的挑战和趋势。本综述旨在向研究人员和从业人员介绍RL和LLM交叉领域的最新进展和前沿趋势,目标是促进更智能、更通用和更安全的大语言模型的发展。
🔬 方法详解
问题定义:现有的大语言模型综述通常只关注强化学习在特定阶段(如对齐微调)的应用,缺乏对整个LLM生命周期的系统性分析。这使得研究人员难以全面了解RL如何赋能LLM,以及如何在不同阶段选择合适的RL方法。此外,现有方法在提升LLM推理能力方面仍有局限性,需要更有效的RL策略来推动模型推理能力达到极限。
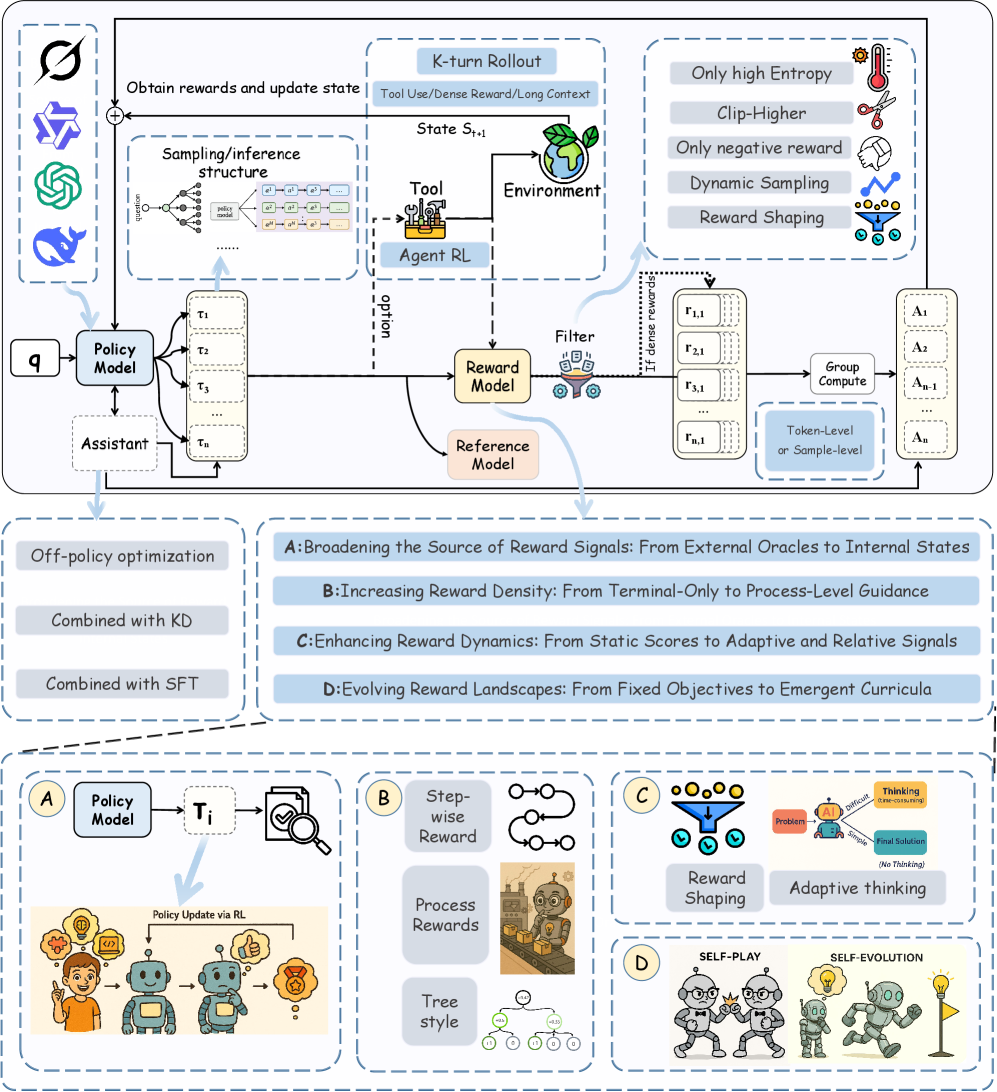
核心思路:本文的核心思路是系统性地梳理RL在LLM全生命周期中的应用,包括预训练、对齐微调和强化推理三个关键阶段。通过分析每个阶段的特点和需求,探讨如何利用RL来提升LLM的性能,特别是推理能力。此外,本文还关注具有可验证奖励的强化学习(RLVR),旨在提高RL训练的稳定性和可靠性。
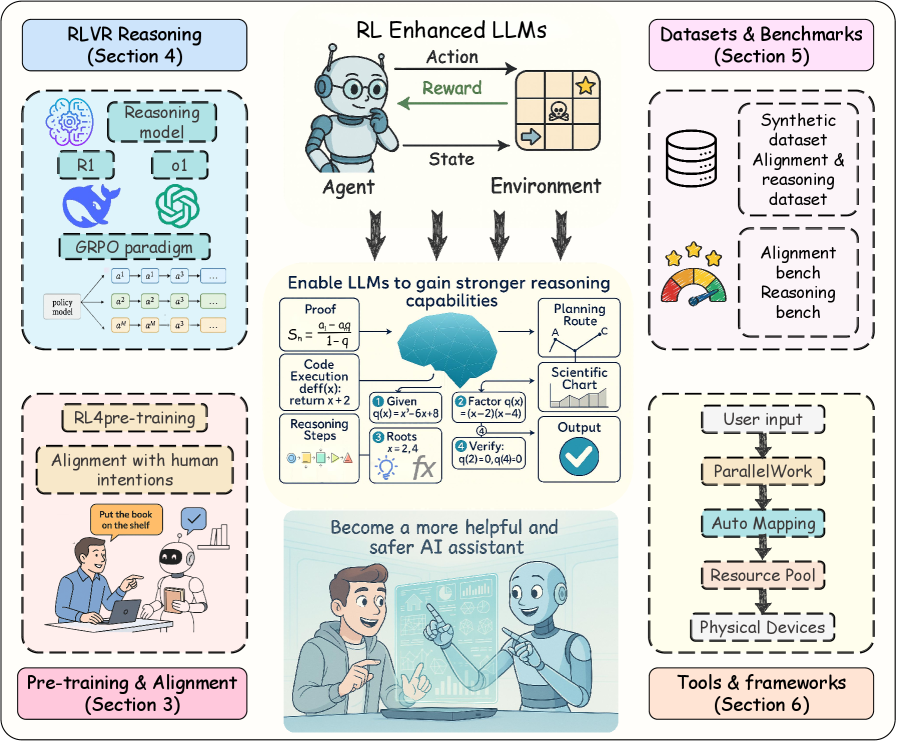
技术框架:本文的框架主要包括以下几个部分:首先,简要介绍RL的基本理论。然后,详细阐述RL在LLM生命周期的各个阶段的应用策略,包括预训练、对齐微调和强化推理。接下来,整理了目前用于RL微调的现有数据集和评估基准。随后,回顾了主流的开源工具和训练框架。最后,分析了RL增强LLM领域未来的挑战和趋势。
关键创新:本文的创新之处在于其全面性和系统性。它不仅涵盖了RL在LLM各个阶段的应用,还关注了RLVR等新兴技术。此外,本文还整理了大量的数据集、评估基准和开源工具,为研究人员提供了宝贵的资源。与现有综述相比,本文的范围更广,内容更深入,更具实用价值。
关键设计:本文没有提出新的算法或模型,而是一个综述性的工作。因此,没有具体的参数设置、损失函数或网络结构需要描述。但是,本文对现有RL算法在LLM各个阶段的应用进行了详细的分析,并指出了未来研究的方向,例如如何设计更有效的奖励函数,如何提高RL训练的稳定性和可靠性等。
🖼️ 关键图片
📊 实验亮点
本文系统地回顾了RL在LLM全生命周期中的应用,并整理了大量的数据集、评估基准和开源工具。特别强调了强化推理阶段的RL方法是推动模型推理能力达到极限的关键驱动力。该综述为研究人员和从业人员提供了宝贵的参考,有助于推动RL和LLM交叉领域的发展。
🎯 应用场景
该研究的潜在应用领域包括智能对话系统、自动问答系统、机器翻译、代码生成等。通过强化学习的赋能,LLM可以更好地理解人类意图,生成更符合用户需求的文本,从而提高用户体验和工作效率。未来,RL增强的LLM有望在各个领域发挥更大的作用,例如智能客服、教育辅助、医疗诊断等。
📄 摘要(原文)
In recent years, training methods centered on Reinforcement Learning (RL) have markedly enhanced the reasoning and alignment performance of Large Language Models (LLMs), particularly in understanding human intents, following user instructions, and bolstering inferential strength. Although existing surveys offer overviews of RL augmented LLMs, their scope is often limited, failing to provide a comprehensive summary of how RL operates across the full lifecycle of LLMs. We systematically review the theoretical and practical advancements whereby RL empowers LLMs, especially Reinforcement Learning with Verifiable Rewards (RLVR). First, we briefly introduce the basic theory of RL. Second, we thoroughly detail application strategies for RL across various phases of the LLM lifecycle, including pre-training, alignment fine-tuning, and reinforced reasoning. In particular, we emphasize that RL methods in the reinforced reasoning phase serve as a pivotal driving force for advancing model reasoning to its limits. Next, we collate existing datasets and evaluation benchmarks currently used for RL fine-tuning, spanning human-annotated datasets, AI-assisted preference data, and program-verification-style corpora. Subsequently, we review the mainstream open-source tools and training frameworks available, providing clear practical references for subsequent research. Finally, we analyse the future challenges and trends in the field of RL-enhanced LLMs. This survey aims to present researchers and practitioners with the latest developments and frontier trends at the intersection of RL and LLMs, with the goal of fostering the evolution of LLMs that are more intelligent, generalizable, and secure.