LLMsPark: A Benchmark for Evaluating Large Language Models in Strategic Gaming Contexts
作者: Junhao Chen, Jingbo Sun, Xiang Li, Haidong Xin, Yuhao Xue, Yibin Xu, Hao Zhao
分类: cs.CL
发布日期: 2025-09-20
备注: Accepted by EMNLP 2025 Findings
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
LLMsPark:一个在策略游戏环境中评估大型语言模型的新基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 博弈论 多智能体 战略决策 评估基准
📋 核心要点
- 现有LLM评估缺乏对交互式和战略性行为的全面考察,难以衡量其在复杂环境中的决策能力。
- LLMsPark通过博弈论环境模拟,评估LLM在策略游戏中的决策、推理和社会行为,从而衡量其战略智能。
- 该基准对15个主流LLM进行了评估,揭示了不同模型在战略能力上的差异,并提供了公开的排行榜和评分机制。
📝 摘要(中文)
随着大型语言模型(LLMs)在各种任务中不断进步,超越单一指标的全面评估变得越来越重要。为了充分评估LLM的智能,检验其交互动态和战略行为至关重要。我们提出了LLMsPark,一个基于博弈论的评估平台,用于衡量LLM在经典博弈论环境中的决策策略和社会行为,提供了一个多智能体环境来探索战略深度。我们的系统使用排行榜排名和评分机制对15个领先的LLM(包括商业和开源模型)进行交叉评估。更高的分数反映了更强的推理和战略能力,揭示了不同模型之间独特的行为模式和性能差异。这项工作为评估LLM的战略智能引入了一个新的视角,丰富了现有的基准,并扩展了它们在交互式博弈论场景中的评估。
🔬 方法详解
问题定义:现有的大型语言模型评估基准主要集中在单轮任务或静态数据集上,缺乏对LLM在动态交互环境中的战略决策能力的评估。现有方法难以衡量LLM在需要长期规划、推理和适应对手策略的复杂场景下的表现。因此,需要一个能够模拟多智能体交互,并评估LLM战略智能的基准。
核心思路:LLMsPark的核心思路是利用经典的博弈论模型,构建一个多智能体环境,让LLM扮演不同的角色,通过与其他LLM或人类玩家进行博弈,来评估其战略决策能力。通过分析LLM在博弈中的行为模式、胜率和得分,可以深入了解其推理、规划和适应能力。
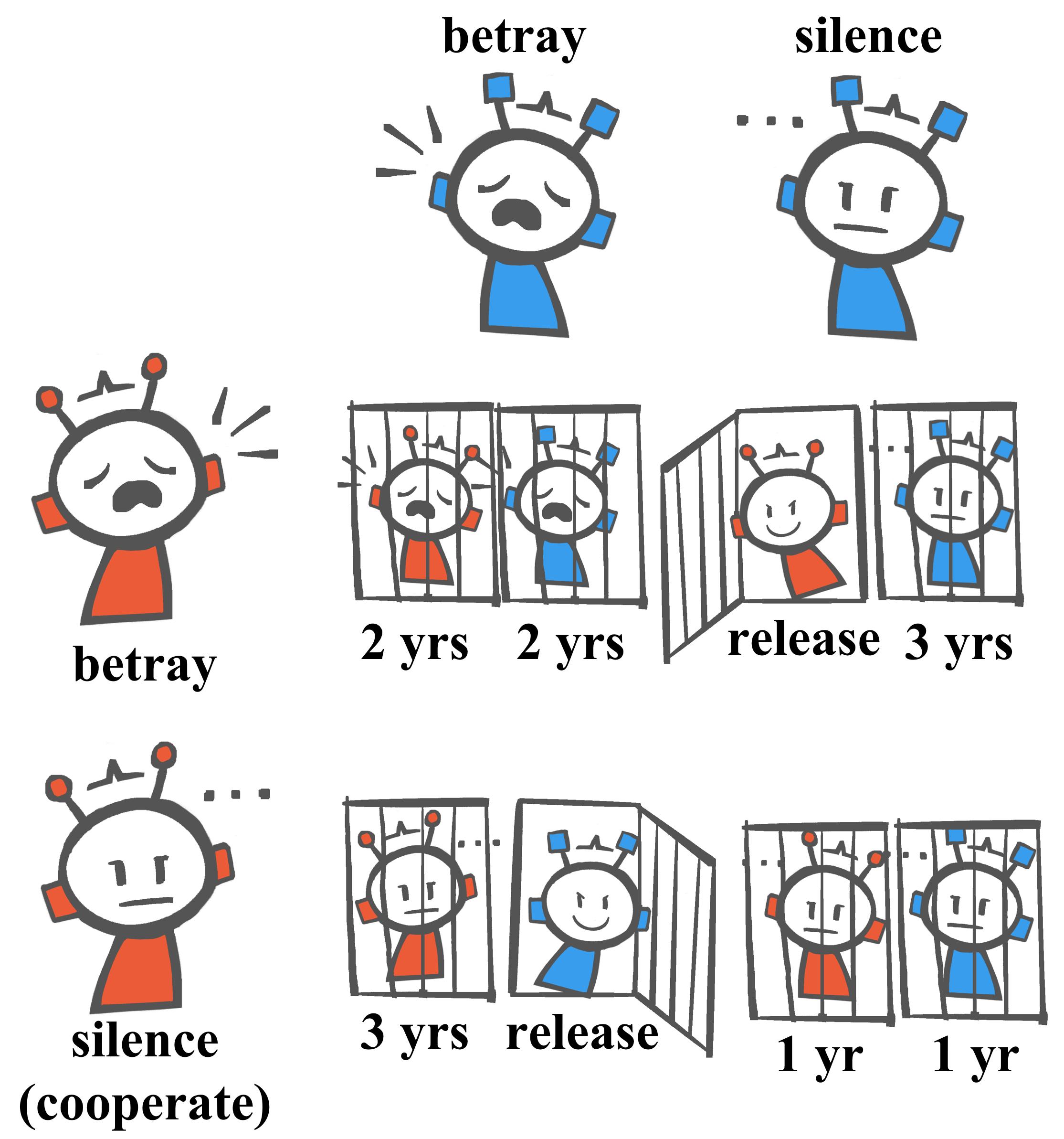
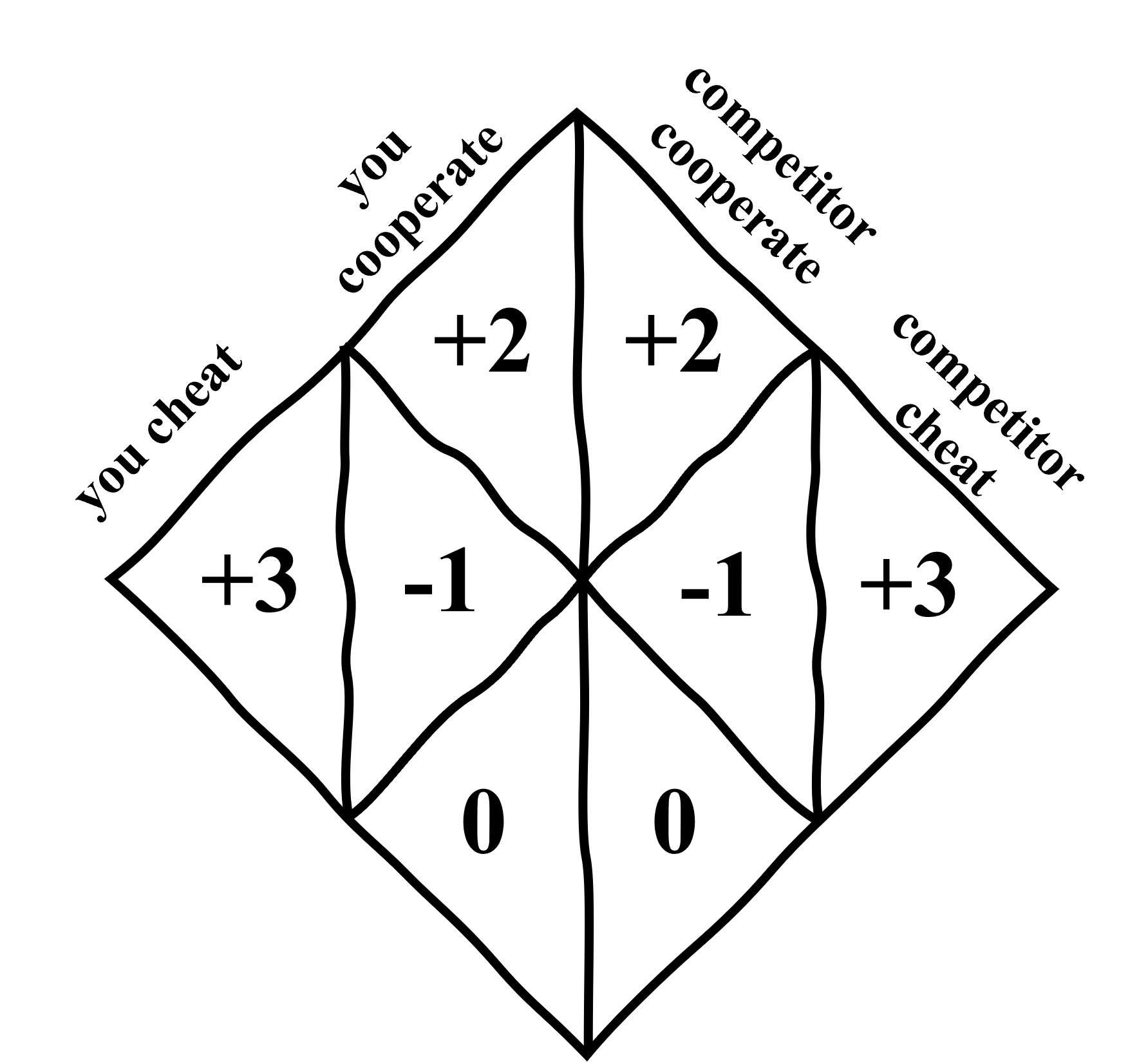
技术框架:LLMsPark的整体框架包括以下几个主要模块:1) 博弈环境:选择或设计经典的博弈论游戏,例如囚徒困境、蜈蚣博弈等。2) LLM智能体:将LLM嵌入到博弈环境中,使其能够观察游戏状态、做出决策并执行动作。3) 评估指标:设计合理的评估指标,例如胜率、平均得分、策略复杂度等,用于衡量LLM的战略能力。4) 排行榜:建立一个公开的排行榜,展示不同LLM在LLMsPark上的表现,促进LLM的战略智能研究。
关键创新:LLMsPark的关键创新在于它提供了一个基于博弈论的、可交互的LLM评估平台。与传统的静态评估基准相比,LLMsPark能够更全面地评估LLM的战略智能,包括其推理、规划、适应和合作能力。此外,LLMsPark还提供了一个多智能体环境,可以用于研究LLM之间的交互行为和涌现现象。
关键设计:LLMsPark的关键设计包括:1) 博弈环境的选择:选择具有代表性的博弈论游戏,例如囚徒困境、蜈蚣博弈等,这些游戏能够考察LLM在不同策略场景下的决策能力。2) 提示工程:设计合适的提示语,引导LLM理解游戏规则、角色设定和目标。3) 奖励函数:设计合理的奖励函数,激励LLM学习有效的策略。4) 评估指标:选择能够反映LLM战略能力的评估指标,例如胜率、平均得分、策略复杂度等。
🖼️ 关键图片

📊 实验亮点
LLMsPark对15个领先的LLM进行了评估,结果显示不同模型在战略能力上存在显著差异。例如,某些模型在囚徒困境中倾向于合作,而另一些模型则更倾向于背叛。排行榜显示,商业LLM通常在战略能力上优于开源LLM,但也有一些开源模型表现出色。这些结果为LLM的战略智能研究提供了有价值的参考。
🎯 应用场景
LLMsPark可应用于评估和提升LLM在需要战略决策的复杂任务中的表现,例如自动驾驶、金融交易、资源管理和智能博弈等领域。通过LLMsPark的评估,可以发现LLM在战略智能方面的不足,并针对性地进行改进,从而提高LLM在实际应用中的可靠性和效率。此外,LLMsPark还可以用于研究LLM之间的合作与竞争,探索多智能体系统的涌现行为。
📄 摘要(原文)
As large language models (LLMs) advance across diverse tasks, the need for comprehensive evaluation beyond single metrics becomes increasingly important. To fully assess LLM intelligence, it is crucial to examine their interactive dynamics and strategic behaviors. We present LLMsPark, a game theory-based evaluation platform that measures LLMs' decision-making strategies and social behaviors in classic game-theoretic settings, providing a multi-agent environment to explore strategic depth. Our system cross-evaluates 15 leading LLMs (both commercial and open-source) using leaderboard rankings and scoring mechanisms. Higher scores reflect stronger reasoning and strategic capabilities, revealing distinct behavioral patterns and performance differences across models. This work introduces a novel perspective for evaluating LLMs' strategic intelligence, enriching existing benchmarks and broadening their assessment in interactive, game-theoretic scenarios. The benchmark and rankings are publicly available at https://llmsparks.github.io/.