AIPsychoBench: Understanding the Psychometric Differences between LLMs and Humans
作者: Wei Xie, Shuoyoucheng Ma, Zhenhua Wang, Enze Wang, Kai Chen, Xiaobing Sun, Baosheng Wang
分类: cs.CL, cs.AI
发布日期: 2025-09-20
备注: Thank you for your attention. This paper was accepted by the CogSci 2025 conference in April and published in August. The location in the proceedings is: https://escholarship.org/uc/item/39k8f46q
💡 一句话要点
AIPsychoBench:构建评估LLM心理特性的专用基准,揭示语言影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 心理测量 基准测试 角色扮演提示 多语言评估
📋 核心要点
- 现有方法直接复用人类心理学量表评估LLM,忽略了LLM与人类的本质区别,导致评估效果不佳,且缺乏跨语言支持。
- AIPsychoBench通过轻量级角色扮演提示绕过LLM对齐,提高响应率并降低偏差,从而更有效地评估LLM的心理特性。
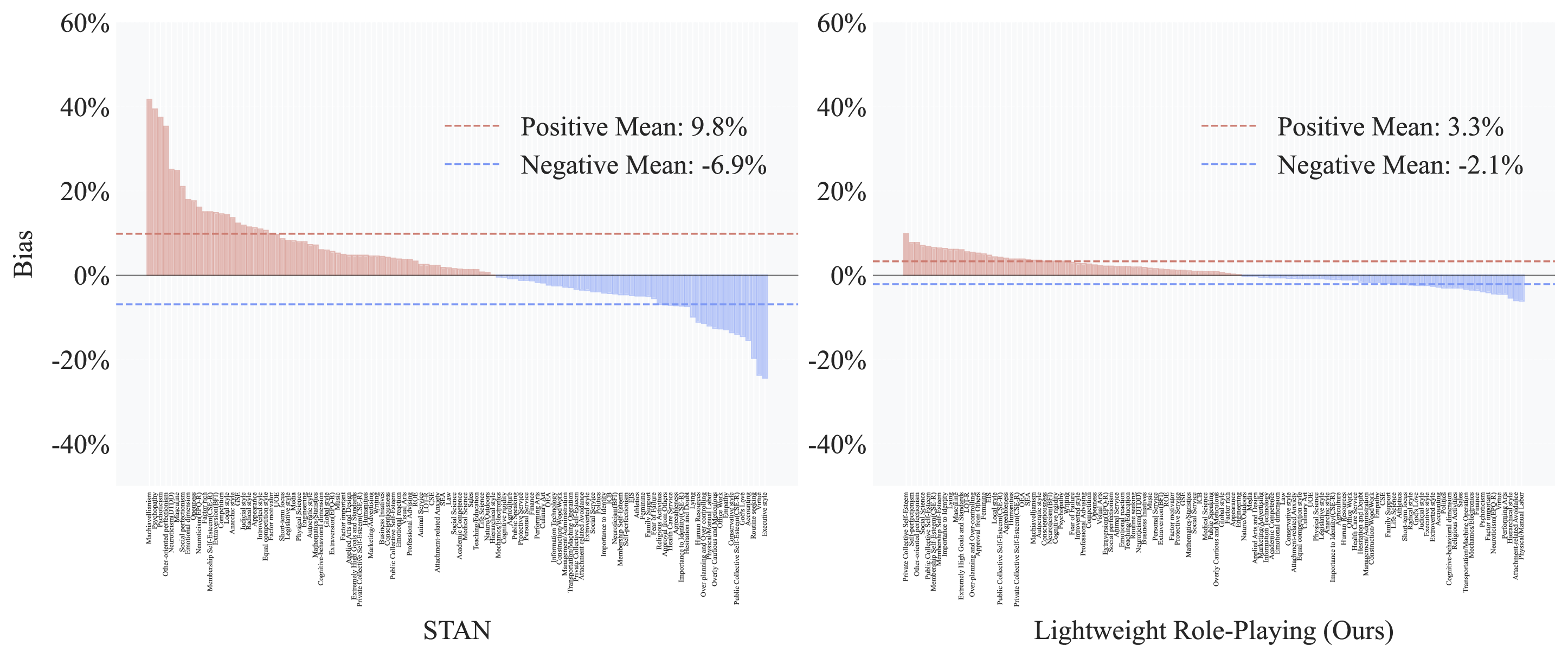
- 实验结果表明,AIPsychoBench显著提高了LLM的响应率,降低了偏差,并首次揭示了语言对LLM心理测量特性的影响。
📝 摘要(中文)
大型语言模型(LLM)通过学习海量互联网数据展现出类人智能。然而,大规模神经网络的不可解释性引发了对LLM可靠性的担忧。现有研究尝试借鉴人类心理学的概念来评估LLM的心理特性,以增强其可解释性,但未能充分考虑LLM与人类之间的根本差异,导致直接重用人类量表时拒绝率很高,且不支持测量LLM在不同语言中的心理特性变化。本文提出了AIPsychoBench,这是一个专门为评估LLM心理特性而定制的基准。它使用轻量级的角色扮演提示来绕过LLM对齐,将平均有效响应率从70.12%提高到90.40%。同时,平均偏差仅为3.3%(正向)和2.1%(负向),远低于传统越狱提示导致的9.8%和6.9%的偏差。此外,在总共112个心理测量子类别中,七种语言相对于英语的分数偏差在43个子类别中介于5%到20.2%之间,首次提供了语言对LLM心理测量影响的全面证据。
🔬 方法详解
问题定义:现有方法在评估大型语言模型(LLM)的心理特性时,主要面临两个痛点:一是直接套用人类心理学量表,忽略了LLM与人类在认知和行为模式上的根本差异,导致评估结果偏差较大,有效性不足;二是缺乏对LLM在不同语言环境下心理特性差异的评估能力,无法全面了解LLM的跨语言行为。
核心思路:本文的核心思路是构建一个专门针对LLM心理特性评估的基准AIPsychoBench。该基准通过设计轻量级的角色扮演提示,引导LLM进入特定情境,从而绕过LLM的对齐机制,提高响应率并降低偏差。同时,AIPsychoBench支持多种语言,能够评估LLM在不同语言环境下的心理特性差异。
技术框架:AIPsychoBench主要包含以下几个关键模块: 1. 角色扮演提示生成器:生成轻量级的角色扮演提示,用于引导LLM进入特定情境。 2. 多语言心理测量量表:包含多种语言的心理测量量表,用于评估LLM的心理特性。 3. 响应收集与分析模块:收集LLM的响应,并进行统计分析,评估LLM的心理特性。 4. 偏差评估模块:评估角色扮演提示引入的偏差。
关键创新:AIPsychoBench的关键创新在于: 1. 提出了轻量级的角色扮演提示,有效绕过LLM的对齐机制,提高了响应率并降低了偏差。 2. 构建了多语言心理测量量表,支持评估LLM在不同语言环境下的心理特性差异。 3. 首次提供了语言对LLM心理测量影响的全面证据。
关键设计:在角色扮演提示的设计上,采用了简洁明了的指令,避免使用可能触发LLM安全机制的敏感词汇。在心理测量量表的选择上,选取了经典的、经过验证的量表,并进行了多语言翻译和校对。在偏差评估上,采用了多种指标,包括正向偏差和负向偏差,以全面评估角色扮演提示的影响。
🖼️ 关键图片


📊 实验亮点
AIPsychoBench通过轻量级角色扮演提示,将LLM的平均有效响应率从70.12%提高到90.40%,同时将平均偏差降低至3.3%(正向)和2.1%(负向),远低于传统越狱提示的9.8%和6.9%。此外,研究发现,在112个心理测量子类别中,七种语言相对于英语的分数偏差在43个子类别中介于5%到20.2%之间,揭示了语言对LLM心理测量特性的显著影响。
🎯 应用场景
AIPsychoBench的研究成果可应用于多个领域。例如,可以用于评估和比较不同LLM的心理特性,帮助开发者选择更适合特定任务的LLM。此外,还可以用于研究LLM的偏见和价值观,促进LLM的公平性和透明度。未来,该研究可以扩展到其他类型的AI系统,例如机器人和智能体,以更好地理解和控制AI的行为。
📄 摘要(原文)
Large Language Models (LLMs) with hundreds of billions of parameters have exhibited human-like intelligence by learning from vast amounts of internet-scale data. However, the uninterpretability of large-scale neural networks raises concerns about the reliability of LLM. Studies have attempted to assess the psychometric properties of LLMs by borrowing concepts from human psychology to enhance their interpretability, but they fail to account for the fundamental differences between LLMs and humans. This results in high rejection rates when human scales are reused directly. Furthermore, these scales do not support the measurement of LLM psychological property variations in different languages. This paper introduces AIPsychoBench, a specialized benchmark tailored to assess the psychological properties of LLM. It uses a lightweight role-playing prompt to bypass LLM alignment, improving the average effective response rate from 70.12% to 90.40%. Meanwhile, the average biases are only 3.3% (positive) and 2.1% (negative), which are significantly lower than the biases of 9.8% and 6.9%, respectively, caused by traditional jailbreak prompts. Furthermore, among the total of 112 psychometric subcategories, the score deviations for seven languages compared to English ranged from 5% to 20.2% in 43 subcategories, providing the first comprehensive evidence of the linguistic impact on the psychometrics of LLM.