The Oracle Has Spoken: A Multi-Aspect Evaluation of Dialogue in Pythia
作者: Zixun Chen, Petr Babkin, Akshat Gupta, Gopala Anumanchipalli, Xiaomo Liu
分类: cs.CL, cs.AI
发布日期: 2025-09-20
💡 一句话要点
通过多维度评估Pythia模型对话能力,揭示模型规模与微调的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话评估 大语言模型 Pythia模型 多维度指标 监督微调 模型性能分析 语言学理论 会话数据集
📋 核心要点
- 现有研究缺乏对大语言模型对话能力细粒度要素的区分,难以深入理解模型行为。
- 论文提出一套基于模型的指标,从语言学理论出发,多维度评估对话能力。
- 实验表明,模型大小影响有限,微调迅速饱和性能,并质疑了部分指标的可靠性。
📝 摘要(中文)
对话是大语言模型(LLMs)的标志性能力之一。尽管其应用广泛,但很少有研究真正区分后训练过程中对话行为的特定要素。我们采用一套全面的基于模型的指标,每个指标都针对对话的不同细粒度方面,并受语言理论的驱动。我们评估了预训练的Pythia模型在这些维度上的性能如何随模型大小的变化而变化,以及在会话数据集上进行监督微调的结果。我们观察到原始模型大小对大多数指标的影响很小,而微调迅速饱和了除最小模型之外的所有模型的得分。与我们的预期相反,许多指标显示出非常相似的趋势,特别是如果它们都基于相同的评估器模型,这引发了它们在衡量特定维度时的可靠性的问题。为此,我们对分数分布、指标相关性和生成响应中的术语频率进行了额外的分析,以帮助解释我们的观察结果。
🔬 方法详解
问题定义:论文旨在解决如何更细致地评估大型语言模型(LLMs)的对话能力的问题。现有方法通常关注整体性能,缺乏对对话行为中不同方面的深入理解和量化分析。这使得我们难以理解模型在哪些方面表现良好,哪些方面存在不足,以及如何有针对性地改进模型。
核心思路:论文的核心思路是采用一套全面的、基于模型的评估指标,这些指标分别针对对话的不同细粒度方面,例如连贯性、相关性、流畅性等。这些指标的设计灵感来源于语言学理论,旨在更准确地捕捉对话行为的各个方面。通过分析模型在这些指标上的表现,可以更深入地了解模型的对话能力。
技术框架:论文的技术框架主要包括以下几个步骤:1)选择预训练的Pythia模型作为研究对象;2)构建一套基于模型的评估指标,这些指标涵盖对话的多个方面;3)在会话数据集上对Pythia模型进行监督微调;4)使用评估指标评估模型在不同阶段(预训练、微调)的性能;5)分析评估结果,包括指标之间的相关性、分数分布以及生成响应中的术语频率,以解释观察到的现象。
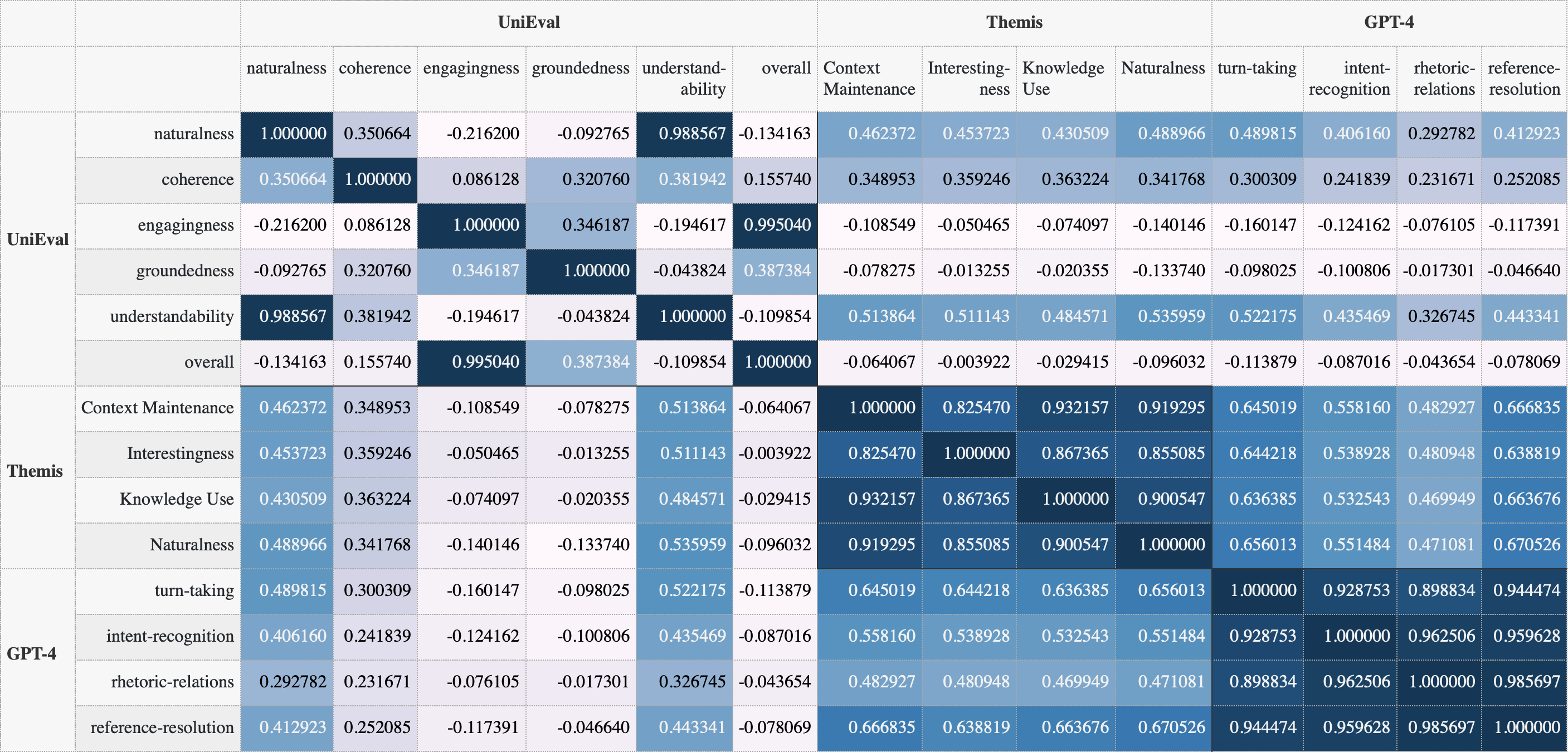
关键创新:论文的关键创新在于提出了一套多维度的对话评估指标,这些指标能够更细粒度地评估模型的对话能力。与传统的整体评估方法相比,这些指标能够更准确地捕捉对话行为的各个方面,从而更深入地了解模型的优势和不足。此外,论文还对评估指标的可靠性进行了分析,并提出了改进建议。
关键设计:论文的关键设计包括:1)评估指标的选择:论文选择了一系列基于模型的指标,这些指标能够自动评估对话的多个方面;2)实验设置:论文在不同大小的Pythia模型上进行了实验,并比较了预训练和微调后的性能;3)分析方法:论文采用了多种分析方法,包括指标相关性分析、分数分布分析以及术语频率分析,以解释观察到的现象。
🖼️ 关键图片


📊 实验亮点
实验结果表明,原始模型大小对大多数对话指标的影响有限,而微调能够迅速提升模型性能,但同时也存在性能饱和现象。此外,研究发现,基于相同评估器模型的指标之间存在高度相关性,这引发了对这些指标在衡量特定维度时可靠性的质疑。例如,连贯性和相关性指标可能高度相关,难以区分。
🎯 应用场景
该研究成果可应用于大语言模型的评估和改进,帮助开发者更全面地了解模型的对话能力,并有针对性地进行优化。此外,该研究提出的评估指标也可用于比较不同模型的对话性能,为用户选择合适的模型提供参考。未来,该研究可扩展到其他类型的对话模型,并与其他评估方法相结合,构建更完善的对话评估体系。
📄 摘要(原文)
Dialogue is one of the landmark abilities of large language models (LLMs). Despite its ubiquity, few studies actually distinguish specific ingredients underpinning dialogue behavior emerging during post-training. We employ a comprehensive suite of model-based metrics, each targeting a distinct fine-grained aspect of dialogue, motivated by linguistic theory. We evaluate how the performance of pre-trained Pythia models changes with respect to each of those dimensions, depending on model size and as a result of supervised fine-tuning on conversational datasets. We observe only a mild impact of raw model size on most metrics, whereas fine-tuning quickly saturates the scores for all but the smallest models tested. Somewhat contrary to our expectations, many metrics show very similar trends, especially if they are all rooted in the same evaluator model, which raises the question of their reliability in measuring a specific dimension. To that end, we conduct additional analyses of score distributions, metric correlations, and term frequencies in generated responses to help explain our observations.