CFDLLMBench: A Benchmark Suite for Evaluating Large Language Models in Computational Fluid Dynamics
作者: Nithin Somasekharan, Ling Yue, Yadi Cao, Weichao Li, Patrick Emami, Pochinapeddi Sai Bhargav, Anurag Acharya, Xingyu Xie, Shaowu Pan
分类: cs.CL, cs.AI
发布日期: 2025-09-19 (更新: 2025-10-10)
🔗 代码/项目: GITHUB
💡 一句话要点
CFDLLMBench:用于评估大语言模型在计算流体动力学中应用能力的基准套件
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 计算流体动力学 大语言模型 基准测试 数值模拟 自动化实验
📋 核心要点
- 现有方法难以自动化复杂物理系统的数值实验,尤其是在计算流体动力学(CFD)领域,该领域对LLM的科学能力提出了挑战。
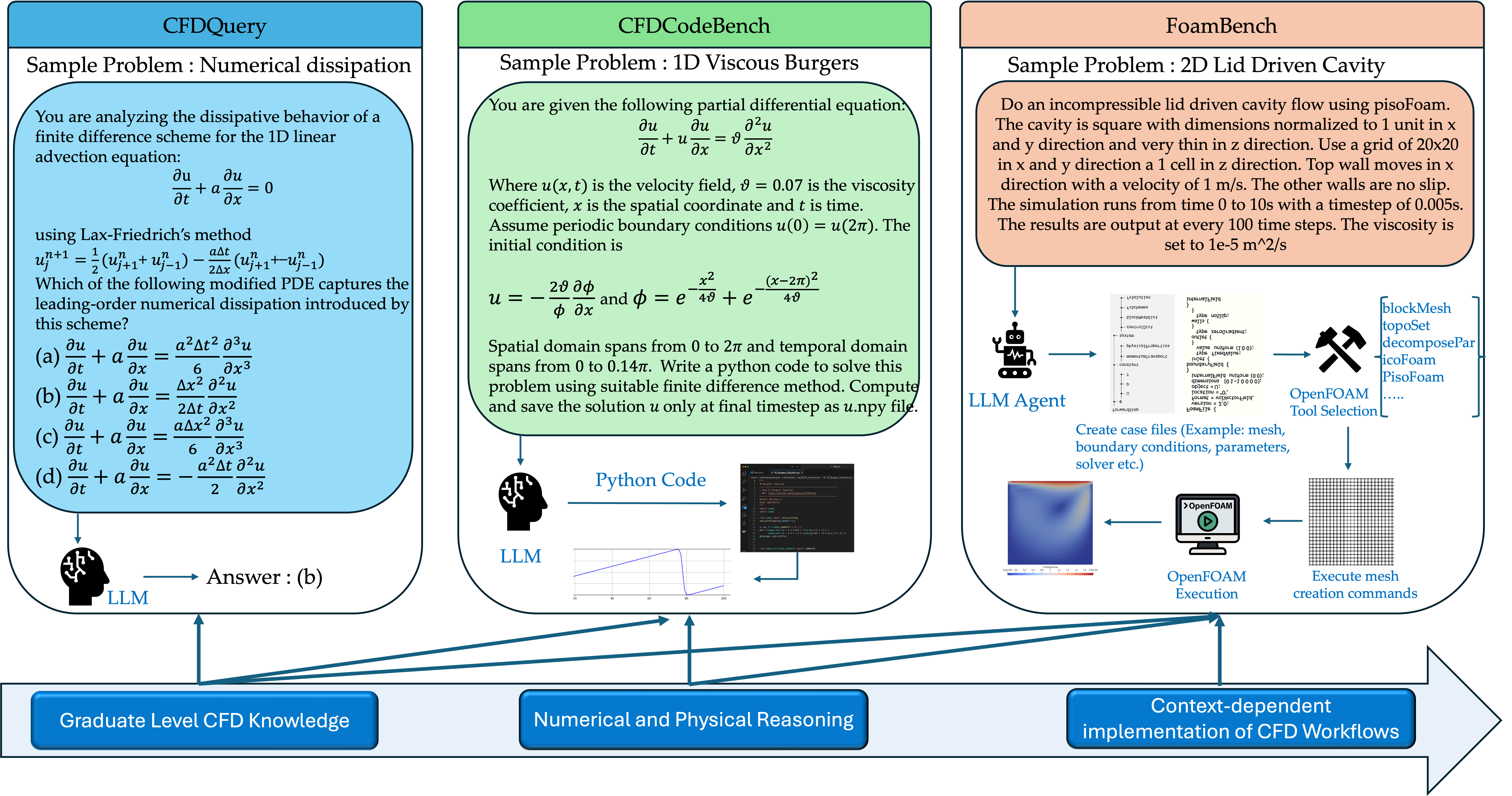
- CFDLLMBench通过三个互补组件(CFDQuery、CFDCodeBench、FoamBench)全面评估LLM在CFD知识、数值推理和工作流程实现方面的能力。
- 该基准套件基于真实CFD实践,结合任务分类和严格评估,量化LLM在代码执行、精度和收敛性方面的性能,提供可重复的结果。
📝 摘要(中文)
大语言模型(LLMs)在通用自然语言处理任务中表现出强大的性能,但它们在自动化复杂物理系统数值实验中的效用——这是一个关键且劳动密集型的环节——仍未被充分探索。作为过去几十年计算科学的主要工具,计算流体动力学(CFD)为评估LLMs的科学能力提供了一个独特的、具有挑战性的试验平台。我们推出了CFDLLMBench,这是一个包含三个互补组件的基准套件——CFDQuery、CFDCodeBench和FoamBench——旨在全面评估LLM在三个关键能力方面的性能:研究生水平的CFD知识、CFD的数值和物理推理,以及CFD工作流程的上下文相关实现。我们的基准基于真实的CFD实践,结合了详细的任务分类法和严格的评估框架,以提供可重复的结果,并量化LLM在代码可执行性、解决方案准确性和数值收敛行为方面的性能。CFDLLMBench为开发和评估LLM驱动的复杂物理系统数值实验自动化奠定了坚实的基础。代码和数据可在https://github.com/NREL-Theseus/cfdllmbench/获取。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在计算流体动力学(CFD)领域应用能力评估的问题。现有方法缺乏针对CFD的专门基准,无法有效评估LLM在CFD知识、数值推理和工作流程实现方面的能力。现有方法难以自动化复杂物理系统的数值实验,CFD领域尤其如此,需要耗费大量人力。
核心思路:论文的核心思路是构建一个全面的基准套件CFDLLMBench,该套件包含三个互补组件,分别评估LLM在CFD不同方面的能力。通过结合详细的任务分类法和严格的评估框架,量化LLM在代码可执行性、解决方案准确性和数值收敛行为方面的性能。这样设计可以更全面、更深入地了解LLM在CFD领域的潜力。
技术框架:CFDLLMBench包含三个主要组件:CFDQuery、CFDCodeBench和FoamBench。CFDQuery评估LLM的研究生水平CFD知识;CFDCodeBench评估LLM的数值和物理推理能力;FoamBench评估LLM在CFD工作流程的上下文相关实现能力。整个框架旨在模拟真实的CFD实践,并提供可重复的结果。
关键创新:该论文最重要的技术创新点在于构建了一个专门针对CFD领域的LLM评估基准。与通用NLP基准不同,CFDLLMBench专注于评估LLM在CFD知识、数值推理和工作流程实现方面的能力。这种针对性使得评估结果更具参考价值,并能更好地指导LLM在CFD领域的应用。
关键设计:CFDLLMBench的关键设计包括任务分类法、评估指标和数据集。任务分类法将CFD任务分解为不同的类别,例如CFD知识问答、代码生成和工作流程实现。评估指标包括代码可执行性、解决方案准确性和数值收敛行为。数据集包含各种CFD问题和案例,用于评估LLM的性能。具体参数设置、损失函数和网络结构等技术细节取决于所使用的LLM模型。
🖼️ 关键图片


📊 实验亮点
CFDLLMBench提供了一个全面的评估框架,可以量化LLM在CFD领域的性能。实验结果表明,不同的LLM在不同的CFD任务中表现出不同的优势和劣势。该基准套件为开发和评估LLM驱动的CFD自动化提供了坚实的基础,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于自动化CFD数值实验,减少人工干预,提高科研效率。潜在应用领域包括航空航天、汽车工程、能源等。通过LLM驱动的自动化,可以加速新设计方案的验证和优化,降低研发成本,并推动相关领域的创新。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated strong performance across general NLP tasks, but their utility in automating numerical experiments of complex physical system -- a critical and labor-intensive component -- remains underexplored. As the major workhorse of computational science over the past decades, Computational Fluid Dynamics (CFD) offers a uniquely challenging testbed for evaluating the scientific capabilities of LLMs. We introduce CFDLLMBench, a benchmark suite comprising three complementary components -- CFDQuery, CFDCodeBench, and FoamBench -- designed to holistically evaluate LLM performance across three key competencies: graduate-level CFD knowledge, numerical and physical reasoning of CFD, and context-dependent implementation of CFD workflows. Grounded in real-world CFD practices, our benchmark combines a detailed task taxonomy with a rigorous evaluation framework to deliver reproducible results and quantify LLM performance across code executability, solution accuracy, and numerical convergence behavior. CFDLLMBench establishes a solid foundation for the development and evaluation of LLM-driven automation of numerical experiments for complex physical systems. Code and data are available at https://github.com/NREL-Theseus/cfdllmbench/.