Pipeline Parallelism is All You Need for Optimized Early-Exit Based Self-Speculative Decoding
作者: Ruanjun Li, Ziheng Liu, Yuanming Shi, Jiawei Shao, Chi Zhang, Xuelong Li
分类: cs.CL, cs.AI
发布日期: 2025-09-19
备注: 17 pages, 7 figures
💡 一句话要点
提出PPSD:通过流水线并行优化基于早退出的自推测解码,加速LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自推测解码 早退出 流水线并行 模型推理加速
📋 核心要点
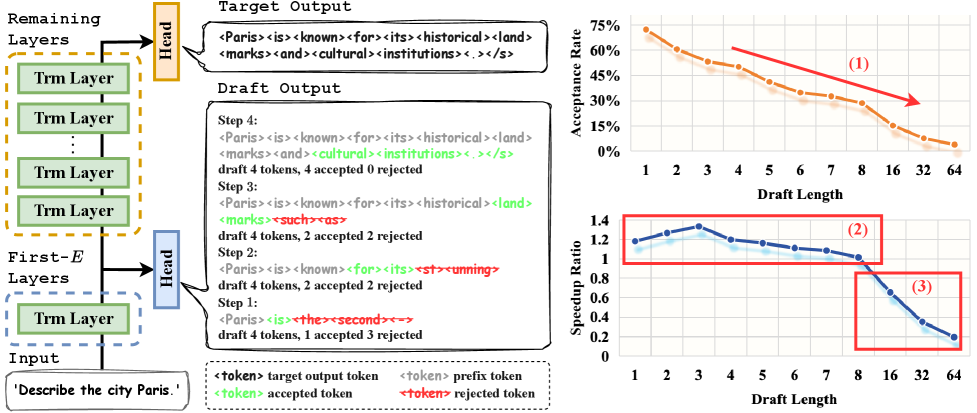
- 现有基于早退出的自推测解码方法,在token接受率不高时,draft成本会抵消加速效果,导致负加速。
- PPSD通过流水线并行处理draft和验证过程,使两者重叠进行,从而避免浪费计算资源在未被接受的token上。
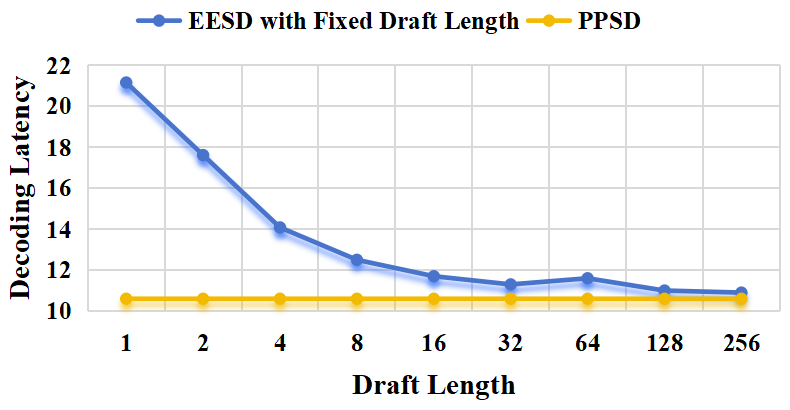
- 实验结果表明,PPSD在多种基准测试中实现了2.01x~3.81x的加速比,接近固定接受率下的最优加速。
📝 摘要(中文)
大型语言模型(LLM)具有出色的生成质量,但由于每个输出token都需要通过所有模型层自回归生成,因此推理成本非常高。基于早退出的自推测解码(EESD)旨在降低这一成本。然而,在实践中,即使使用良好对齐的早退出头和选择的退出位置,许多方法也难以在这种draft-then-verify范式中实现预期的加速。我们的分析表明,只有当绝大多数draft token被LLM接受时,EESD才能获得收益。否则,draft成本可能会超过加速增益,导致负加速。为了缓解这个问题,我们提出了流水线并行自推测解码(PPSD),它完全流水线化draft和验证工作,从而避免在失败的预测上浪费精力。它有两项关键创新。我们将模型层配置为流水线,其中早退出(draft)计算和剩余层(验证)计算重叠。我们交错每个token的draft和验证。当LLM在其最后几层中验证当前token时,早退出路径同时draft下一个token。这种verify-while-draft方案使所有单元保持忙碌,并类似于流水线化推测和验证阶段,从而动态验证token。经验结果证实,PPSD在自推测LLM推理中实现了最先进的加速。在不同的基准测试中,PPSD实现了2.01x~3.81x范围内的加速比,在固定的接受率和退出位置上获得了几乎最佳的加速,展示了其在提供高效自推测方面的进步。
🔬 方法详解
问题定义:论文旨在解决大型语言模型推理速度慢的问题,特别是基于早退出的自推测解码方法在实际应用中加速效果不佳的问题。现有方法的痛点在于,如果draft阶段生成的token被验证阶段拒绝的比例过高,那么draft阶段的计算就变成了无效计算,反而会降低整体的推理速度。
核心思路:论文的核心思路是将draft阶段和验证阶段进行流水线并行处理。具体来说,在验证当前token的同时,并行地draft下一个token。这样,即使draft的token最终被拒绝,验证过程也在进行中,不会浪费计算资源。通过这种方式,最大化利用计算资源,提高整体推理速度。
技术框架:PPSD的技术框架主要包括以下几个部分:首先,将LLM的各个层配置成一个流水线。然后,对于每一个token,先通过早退出路径进行draft,生成一个候选token。同时,LLM的剩余层对前一个token进行验证。这种draft和验证的交错进行,使得整个系统能够高效地利用计算资源。
关键创新:PPSD最重要的技术创新点在于其流水线并行的draft和验证机制。与传统的自推测解码方法不同,PPSD不是先完整地draft一批token,然后再进行验证,而是将draft和验证过程交错进行,从而避免了无效计算的浪费。这种设计使得PPSD能够在较低的token接受率下仍然保持较高的加速效果。
关键设计:PPSD的关键设计在于如何将LLM的各个层配置成一个高效的流水线,以及如何控制draft和验证的同步。具体的参数设置和网络结构细节可能依赖于具体的LLM架构,但核心思想是确保draft和验证过程能够尽可能地并行进行,并且能够快速地处理被拒绝的token。
🖼️ 关键图片

📊 实验亮点
PPSD在多种基准测试中取得了显著的加速效果,实现了2.01x~3.81x的加速比。该加速比接近在固定接受率和退出位置下的最优加速,表明PPSD能够有效地利用计算资源,提高LLM的推理效率。实验结果证明了PPSD在自推测LLM推理方面的先进性。
🎯 应用场景
PPSD具有广泛的应用前景,可以应用于各种需要快速LLM推理的场景,例如在线对话系统、实时翻译、内容生成等。通过提高LLM的推理速度,可以降低计算成本,提高用户体验,并促进LLM在更多领域的应用。
📄 摘要(原文)
Large language models (LLMs) deliver impressive generation quality, but incur very high inference cost because each output token is generated auto-regressively through all model layers. Early-exit based self-speculative decoding (EESD) has emerged to mitigate this cost. However, in practice, many approaches struggle to achieve the expected acceleration in such draft-then-verify paradigm even with a well-aligned early-exit head and selected exit position. Our analysis reveals that EESD only pays off when the vast majority of draft tokens are accepted by the LLM. Otherwise, the draft cost may overcome the acceleration gain and lead to a negative speedup. To mitigate this, we propose Pipeline-Parallel Self-Speculative Decoding (PPSD) that fully pipelines the draft and verification work so that no effort is wasted on failed predictions. It has two key innovations. We configure the model layers as a pipeline in which early-exit (draft) computations and remaining-layer (verification) computations overlap. We interleave drafting and verification per token. While the LLM is verifying the current token in its final layers, the early-exit path simultaneously drafts the next token. Such a verify-while-draft scheme keeps all units busy and validates tokens on-the-fly analogous to pipelining the speculation and verification stages. Empirical results confirm that PPSD achieves state-of-the-art acceleration in self-speculative LLM inference. On diverse benchmarks, PPSD achieves speedup ratios in the range of 2.01x~3.81x, which gains almost the optimal acceleration at the fixed acceptance rate and exit position, showcasing its advancement in providing efficient self-speculation.