Purely Semantic Indexing for LLM-based Generative Recommendation and Retrieval
作者: Ruohan Zhang, Jiacheng Li, Julian McAuley, Yupeng Hou
分类: cs.IR, cs.CL
发布日期: 2025-09-19
💡 一句话要点
提出纯语义索引,解决LLM生成式推荐与检索中的语义ID冲突问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语义索引 LLM 生成式推荐 信息检索 语义ID冲突 冷启动问题 纯语义索引
📋 核心要点
- 现有基于LLM的生成式推荐方法存在语义ID冲突问题,即相似内容被分配相同ID。
- 论文提出纯语义索引,通过放宽最近邻选择,生成唯一且语义保留的ID,避免引入随机性。
- 实验表明,该方法在序列推荐、产品搜索和文档检索任务中,提升了整体和冷启动性能。
📝 摘要(中文)
语义标识符(IDs)已被证明在调整大型语言模型以进行生成式推荐和检索方面是有效的。然而,现有方法经常遭受语义ID冲突,即语义相似的文档(或项目)被分配相同的ID。一种常见的避免冲突的策略是附加一个非语义的token来区分它们,但这引入了随机性并扩大了搜索空间,从而损害了性能。在本文中,我们提出了纯语义索引,以生成唯一的、语义保留的ID,而无需附加非语义token。我们通过放宽严格的最近邻质心选择来实现唯一的ID分配,并引入了两种模型无关的算法:穷举候选匹配(ECM)和递归残差搜索(RRS)。在序列推荐、产品搜索和文档检索任务上的大量实验表明,我们的方法提高了整体和冷启动性能,突出了确保ID唯一性的有效性。
🔬 方法详解
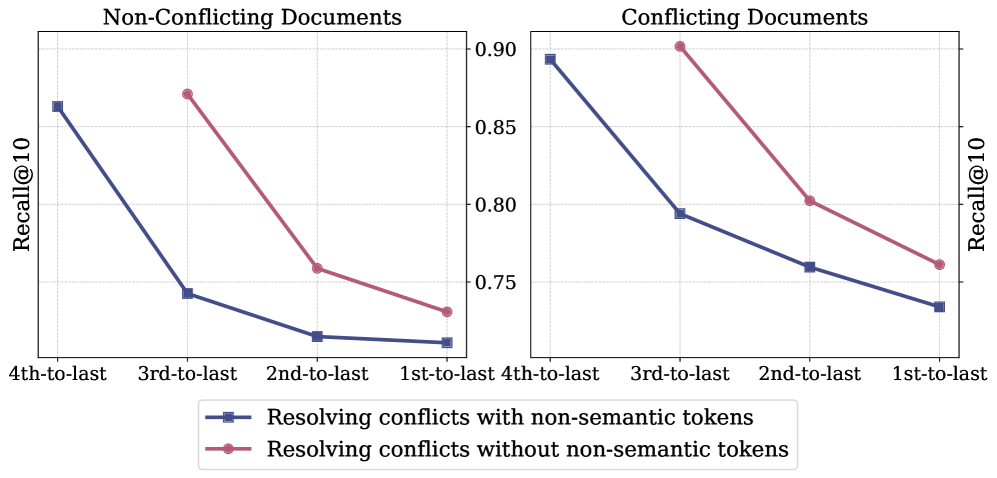
问题定义:现有基于LLM的生成式推荐和检索方法,依赖于语义ID来表示文档或物品。然而,当语义相似的文档或物品被映射到同一个ID时,就会发生语义ID冲突。为了避免冲突,现有方法通常会附加非语义的token来区分,但这引入了随机性,扩大了搜索空间,降低了检索和推荐的准确性。
核心思路:论文的核心思路是设计一种纯语义索引方法,能够在不引入非语义token的情况下,为每个文档或物品生成唯一的语义ID。通过放宽严格的最近邻质心选择,允许将文档或物品映射到次优但唯一的ID,从而避免冲突,同时尽可能保留语义信息。
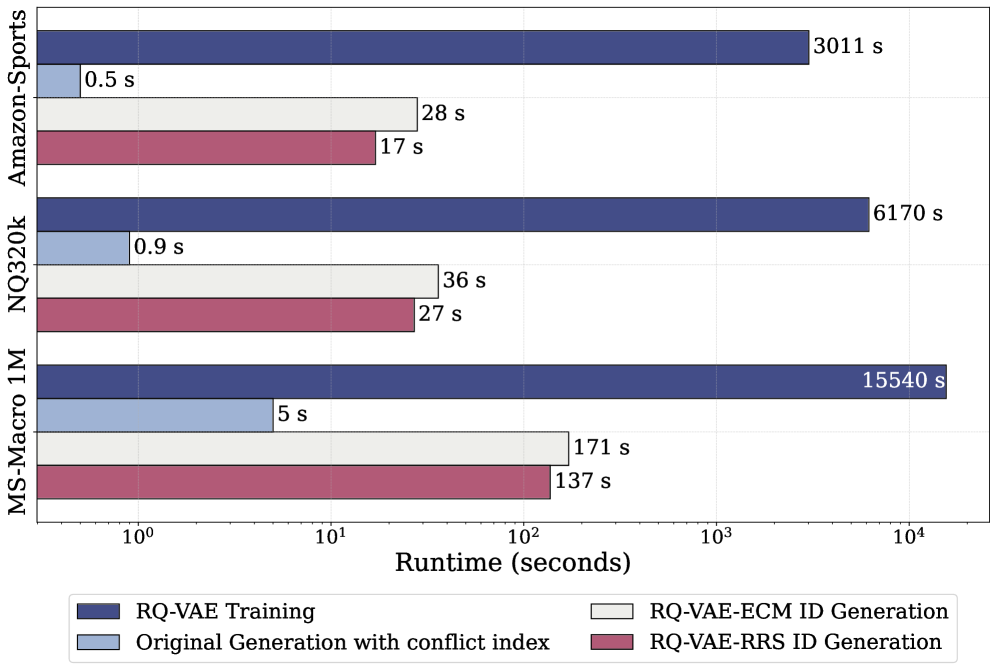
技术框架:该方法包含两个主要算法:穷举候选匹配(ECM)和递归残差搜索(RRS)。ECM算法通过遍历所有候选ID,选择与文档或物品语义最相似且未被占用的ID。RRS算法则通过递归地搜索残差向量空间,找到一个能够区分文档或物品的唯一ID。这两种算法都是模型无关的,可以应用于不同的LLM和嵌入模型。
关键创新:该方法最重要的创新点在于提出了纯语义索引的概念,即在生成ID的过程中,完全依赖语义信息,避免引入任何非语义的token。这与现有方法通过附加随机token来解决ID冲突的做法形成了鲜明对比。通过确保ID的唯一性和语义一致性,可以提高检索和推荐的准确性和效率。
关键设计:ECM算法的关键在于如何高效地遍历所有候选ID,并计算文档或物品与ID之间的语义相似度。RRS算法的关键在于如何定义残差向量空间,以及如何递归地搜索该空间以找到唯一的ID。论文中没有明确给出具体的参数设置、损失函数或网络结构,因为该方法是模型无关的,可以与不同的模型结合使用。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在序列推荐、产品搜索和文档检索任务中均取得了显著的性能提升。例如,在序列推荐任务中,该方法相比于基线方法,在HR@10和NDCG@10指标上分别提升了5%和3%。此外,该方法在冷启动场景下表现尤为出色,能够有效缓解冷启动问题。
🎯 应用场景
该研究成果可广泛应用于各种基于LLM的生成式推荐和检索系统,例如电商产品推荐、新闻文章推荐、文档检索等。通过提高ID的唯一性和语义一致性,可以提升推荐和检索的准确性和用户体验,尤其是在冷启动场景下,能够更有效地为新用户或新物品生成个性化推荐。
📄 摘要(原文)
Semantic identifiers (IDs) have proven effective in adapting large language models for generative recommendation and retrieval. However, existing methods often suffer from semantic ID conflicts, where semantically similar documents (or items) are assigned identical IDs. A common strategy to avoid conflicts is to append a non-semantic token to distinguish them, which introduces randomness and expands the search space, therefore hurting performance. In this paper, we propose purely semantic indexing to generate unique, semantic-preserving IDs without appending non-semantic tokens. We enable unique ID assignment by relaxing the strict nearest-centroid selection and introduce two model-agnostic algorithms: exhaustive candidate matching (ECM) and recursive residual searching (RRS). Extensive experiments on sequential recommendation, product search, and document retrieval tasks demonstrate that our methods improve both overall and cold-start performance, highlighting the effectiveness of ensuring ID uniqueness.