Evaluating the Effectiveness and Scalability of LLM-Based Data Augmentation for Retrieval
作者: Pranjal A. Chitale, Bishal Santra, Yashoteja Prabhu, Amit Sharma
分类: cs.IR, cs.CL
发布日期: 2025-09-19
备注: EMNLP 2025 (MAIN Conference)
💡 一句话要点
研究LLM数据增强在检索中的有效性和可扩展性,揭示最优增强策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息检索 数据增强 大型语言模型 双编码器 预训练模型 可扩展性 分布外泛化 检索模型
📋 核心要点
- 现有紧凑型双编码器检索模型因知识有限,性能不如大型语言模型(LLM)检索模型。
- 论文研究LLM数据增强在检索中的有效性和可扩展性,旨在找到最优的增强策略。
- 实验表明,增强效果随规模增大而递减,小LLM增强可媲美大LLM,且对未充分预训练的模型提升最大。
📝 摘要(中文)
紧凑型双编码器模型因其效率和可扩展性而被广泛用于检索。然而,与基于大型语言模型(LLM)的检索模型相比,此类模型的性能通常较差,这可能是由于其世界知识有限。虽然基于LLM的数据增强已被提出作为弥合这种性能差距的策略,但对其有效性和可扩展性在实际检索问题中的理解尚不充分。现有的研究没有系统地探索关键因素,例如最佳增强规模、使用大型增强模型的必要性,以及多样化的增强是否能提高泛化能力,尤其是在分布外(OOD)设置中。本研究对LLM增强在检索中的有效性进行了全面研究,包括检索模型、增强模型和增强策略的100多个不同的实验设置。我们发现,虽然增强可以提高检索性能,但其益处会超过一定的增强规模而减小,即使采用多样化的增强策略也是如此。令人惊讶的是,我们观察到使用较小的LLM进行增强可以达到与较大的增强模型相媲美的性能。此外,我们研究了增强效果如何随检索模型预训练的变化而变化,发现增强对未经过良好预训练的模型最有益。我们的见解为更明智和高效的增强策略铺平了道路,从而能够做出明智的决策并最大限度地提高检索性能,同时更具成本效益。代码和增强数据集可在https://aka.ms/DAGR公开获取。
🔬 方法详解
问题定义:论文旨在解决紧凑型双编码器模型在检索任务中,因缺乏足够的世界知识而导致性能受限的问题。现有方法依赖于大型语言模型进行检索,但计算成本高昂。数据增强是一种潜在的解决方案,但如何有效地利用LLM进行数据增强,以及增强的规模、模型选择等因素对性能的影响尚不明确。
核心思路:论文的核心思路是通过系统性地评估不同规模的LLM、不同的增强策略以及不同的检索模型预训练程度,来探究LLM数据增强在检索任务中的有效性和可扩展性。通过实验分析,找到最优的增强策略,从而在保证检索性能的同时,降低计算成本。
技术框架:论文构建了一个包含多个模块的实验框架。首先,选择不同的检索模型(例如双编码器模型),并使用不同的预训练策略。然后,使用不同规模的LLM(包括大型和小型LLM)生成增强数据,并采用不同的增强策略(例如多样化增强)。最后,在不同的数据集上评估检索模型的性能,并分析增强效果与增强规模、LLM规模以及检索模型预训练程度之间的关系。
关键创新:论文的关键创新在于对LLM数据增强在检索任务中的有效性和可扩展性进行了全面的实验研究。通过大量的实验,揭示了增强效果与增强规模、LLM规模以及检索模型预训练程度之间的复杂关系。此外,论文还发现,使用较小的LLM进行增强可以达到与较大的LLM相媲美的性能,这为降低计算成本提供了新的思路。
关键设计:论文的关键设计包括:1) 系统性地评估不同规模的LLM(例如,不同参数量的LLM)作为增强模型的效果;2) 探索不同的增强策略,例如多样化增强,以提高数据的泛化能力;3) 分析增强效果与检索模型预训练程度之间的关系,从而确定哪些模型最能受益于数据增强;4) 使用多种数据集进行评估,以验证结论的普适性。
🖼️ 关键图片

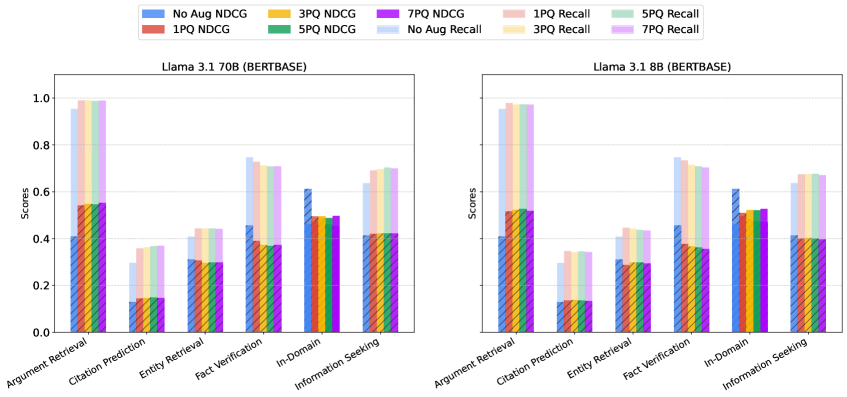
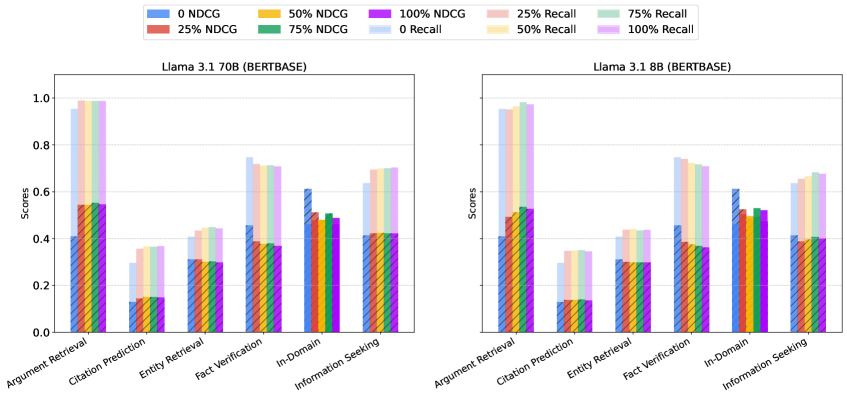
📊 实验亮点
实验结果表明,LLM数据增强可以有效提升检索性能,但存在一个最优的增强规模,超过该规模后,性能提升会减缓。令人惊讶的是,使用较小的LLM进行增强可以达到与较大的LLM相媲美的性能。此外,增强对未经过良好预训练的检索模型提升最为显著。这些发现为设计更高效、更经济的数据增强策略提供了重要指导。
🎯 应用场景
该研究成果可应用于各种信息检索场景,例如搜索引擎、问答系统、推荐系统等。通过采用更高效的LLM数据增强策略,可以提升检索系统的性能,同时降低计算成本,使得在资源受限的环境下也能部署高性能的检索系统。研究结果有助于优化数据增强流程,提升模型泛化能力。
📄 摘要(原文)
Compact dual-encoder models are widely used for retrieval owing to their efficiency and scalability. However, such models often underperform compared to their Large Language Model (LLM)-based retrieval counterparts, likely due to their limited world knowledge. While LLM-based data augmentation has been proposed as a strategy to bridge this performance gap, there is insufficient understanding of its effectiveness and scalability to real-world retrieval problems. Existing research does not systematically explore key factors such as the optimal augmentation scale, the necessity of using large augmentation models, and whether diverse augmentations improve generalization, particularly in out-of-distribution (OOD) settings. This work presents a comprehensive study of the effectiveness of LLM augmentation for retrieval, comprising over 100 distinct experimental settings of retrieval models, augmentation models and augmentation strategies. We find that, while augmentation enhances retrieval performance, its benefits diminish beyond a certain augmentation scale, even with diverse augmentation strategies. Surprisingly, we observe that augmentation with smaller LLMs can achieve performance competitive with larger augmentation models. Moreover, we examine how augmentation effectiveness varies with retrieval model pre-training, revealing that augmentation provides the most benefit to models which are not well pre-trained. Our insights pave the way for more judicious and efficient augmentation strategies, thus enabling informed decisions and maximizing retrieval performance while being more cost-effective. Code and augmented datasets accompanying this work are publicly available at https://aka.ms/DAGR.