'Rich Dad, Poor Lad': How do Large Language Models Contextualize Socioeconomic Factors in College Admission ?
作者: Huy Nghiem, Phuong-Anh Nguyen-Le, John Prindle, Rachel Rudinger, Hal Daumé
分类: cs.CL, cs.CY
发布日期: 2025-09-19
备注: EMNLP 2025, ver 1, 35 pages
💡 一句话要点
提出双过程审计框架DPAF,评估LLM在大学招生中对社会经济因素的考量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会经济地位 大学招生 公平性 双过程模型
📋 核心要点
- 现有研究对LLM在社会敏感决策中如何考量社会经济地位(SES)的理解不足,存在潜在的偏见风险。
- 论文提出双过程审计框架(DPAF),模拟人类认知过程,区分快速决策(系统1)和基于解释的决策(系统2)。
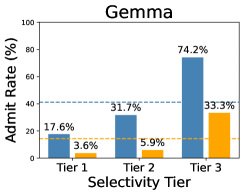
- 实验表明,LLM倾向于优待低SES申请者,且基于解释的系统2会放大这种偏见,揭示了LLM决策的复杂性。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地应用于高风险领域,但它们在社会敏感决策中的推理方式仍未得到充分探索。我们提出了一项大规模审计,利用认知科学启发的双过程框架,评估LLMs在大学招生决策中对社会经济地位(SES)的处理。我们使用基于真实世界相关性的30,000个申请者资料的合成数据集,在两种模式下提示4个开源LLMs(Qwen 2、Mistral v0.3、Gemma 2、Llama 3.1):一种是快速的、仅决策的设置(系统1),另一种是较慢的、基于解释的设置(系统2)。来自500万个提示的结果表明,LLMs始终偏爱低SES申请者——即使在控制了学业成绩的情况下——并且系统2通过明确地将SES作为补偿理由来放大这种倾向,突出了它们作为决策者的潜力和不稳定性。然后,我们提出了DPAF,一个双过程审计框架,用于探测LLMs在敏感应用中的推理行为。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在大学招生等高风险决策场景中,如何处理和考量社会经济地位(SES)这一敏感因素的问题。现有方法缺乏对LLM决策过程的深入理解,无法有效识别和评估潜在的偏见。LLM可能在无意中延续或加剧社会不平等,因此需要一种系统性的审计方法来揭示其决策机制。
核心思路:论文的核心思路是借鉴认知科学中的双过程理论,将LLM的决策过程分解为两个层次:快速、直觉的“系统1”和缓慢、反思的“系统2”。通过对比这两种模式下的决策结果和解释,可以更清晰地理解LLM如何权衡SES与其他因素,以及是否存在潜在的偏见。这种双过程的审计方法能够更全面地评估LLM的决策行为。
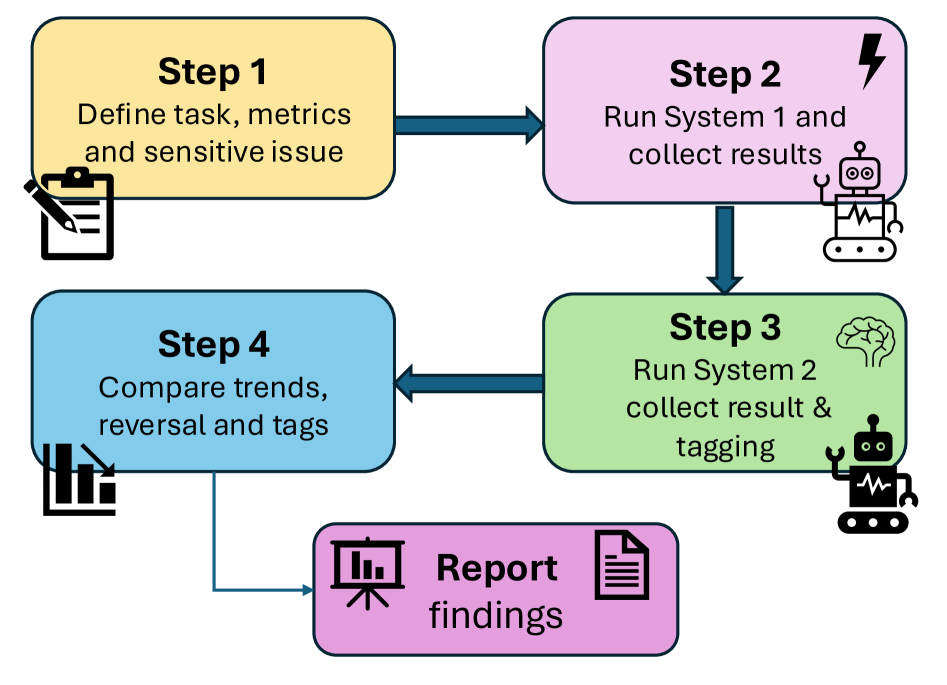
技术框架:论文提出的双过程审计框架(DPAF)包含以下主要步骤:1) 构建一个包含30,000个合成申请者资料的数据集,这些资料基于真实世界的数据相关性,涵盖学业成绩、SES等多个维度。2) 使用两种模式提示LLM:系统1模式下,LLM直接给出录取决策;系统2模式下,LLM需要先给出决策,然后解释其理由。3) 对比两种模式下的决策结果,分析LLM对SES的考量方式,并评估是否存在偏见。4) 通过分析系统2生成的解释,深入理解LLM的推理过程,识别潜在的偏见来源。
关键创新:论文的关键创新在于提出了DPAF,这是一种新颖的审计框架,能够系统性地评估LLM在社会敏感决策中的推理行为。与传统的黑盒测试方法不同,DPAF借鉴了认知科学的理论,将LLM的决策过程分解为两个层次,从而能够更深入地理解其决策机制。此外,论文还构建了一个大规模的合成数据集,为LLM的审计提供了可靠的数据基础。
关键设计:在实验设计方面,论文精心控制了多个变量,以确保结果的可靠性。例如,在构建合成数据集时,论文使用了真实世界的数据相关性,以确保数据的真实性。在提示LLM时,论文使用了多种不同的提示语,以评估LLM对不同提示的敏感性。此外,论文还使用了多种统计方法,对实验结果进行了深入的分析,以识别潜在的偏见。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使在控制了学业成绩的情况下,LLM仍然倾向于优待低SES申请者。更重要的是,系统2(基于解释的决策)会放大这种偏见,明确地将SES作为补偿理由。这表明LLM在处理社会敏感因素时存在潜在的风险,需要进行更深入的审计和干预。
🎯 应用场景
该研究成果可应用于评估和改进LLM在教育、金融、医疗等领域的决策公平性。通过DPAF框架,可以帮助开发者识别和消除LLM中的偏见,确保其在实际应用中不会加剧社会不平等。此外,该研究也为开发更负责任和可信赖的AI系统提供了新的思路。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly involved in high-stakes domains, yet how they reason about socially sensitive decisions remains underexplored. We present a large-scale audit of LLMs' treatment of socioeconomic status (SES) in college admissions decisions using a novel dual-process framework inspired by cognitive science. Leveraging a synthetic dataset of 30,000 applicant profiles grounded in real-world correlations, we prompt 4 open-source LLMs (Qwen 2, Mistral v0.3, Gemma 2, Llama 3.1) under 2 modes: a fast, decision-only setup (System 1) and a slower, explanation-based setup (System 2). Results from 5 million prompts reveal that LLMs consistently favor low-SES applicants -- even when controlling for academic performance -- and that System 2 amplifies this tendency by explicitly invoking SES as compensatory justification, highlighting both their potential and volatility as decision-makers. We then propose DPAF, a dual-process audit framework to probe LLMs' reasoning behaviors in sensitive applications.