RephQA: Evaluating Readability of Large Language Models in Public Health Question Answering
作者: Weikang Qiu, Tinglin Huang, Ryan Rullo, Yucheng Kuang, Ali Maatouk, S. Raquel Ramos, Rex Ying
分类: cs.CL
发布日期: 2025-09-19 (更新: 2025-10-03)
备注: ACM KDD Health Track 2025 Blue Sky Best Paper
💡 一句话要点
RephQA:评估大型语言模型在公共健康问答中的可读性,并提出优化策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可读性评估 公共健康问答 基准数据集 策略优化
📋 核心要点
- 现有大型语言模型在公共健康问答中,虽然具备一定的推理能力,但生成回复的可读性不足,难以被非医学背景人群理解。
- 论文提出RephQA基准,用于评估LLM在公共健康问答中的可读性,并探索多种策略来提升LLM生成文本的可读性。
- 实验结果表明,现有LLM在可读性方面存在差距,而token-adapted GRPO策略能够有效提升LLM生成文本的可读性。
📝 摘要(中文)
大型语言模型(LLMs)在解决复杂的医疗问题方面展现出潜力。然而,现有研究主要集中在提高准确性和推理能力,而忽略了LLM生成回复的可读性,尤其是在向非医学背景的人群清晰简洁地回答公共健康问题方面的能力。本文提出了RephQA,一个用于评估LLM在公共健康问答(QA)中可读性的基准。它包含来自13个主题的27个来源的533个专家评审的QA对,并包括一个代理多项选择任务来评估信息量,以及两个可读性指标:Flesch-Kincaid grade level和专业评分。对25个LLM的评估表明,大多数模型未能达到可读性标准,突出了推理和有效沟通之间的差距。为了解决这个问题,我们探索了四种提高可读性的策略——标准提示、思维链提示、Group Relative Policy Optimization (GRPO)以及token-adapted变体。Token-adapted GRPO取得了最佳结果,推动了更实用和用户友好的公共健康代理的开发。这些结果代表了朝着构建更实用的公共健康代理迈出的一步。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在公共健康问答领域生成内容可读性差的问题。现有方法主要关注准确性和推理能力,忽略了面向非医学背景用户时,清晰简洁地传递信息的重要性。这导致LLM生成的回复难以被普通大众理解,阻碍了其在公共健康领域的实际应用。
核心思路:论文的核心思路是通过构建一个专门评估可读性的基准数据集RephQA,并利用该基准来评估和优化LLM生成文本的可读性。通过引入可读性指标和优化策略,使LLM能够生成更易于理解的公共健康信息。
技术框架:整体框架包括以下几个主要步骤:1) 构建RephQA基准数据集,包含专家评审的QA对和可读性评估指标;2) 使用RephQA评估多个LLM的可读性;3) 探索多种可读性增强策略,包括标准提示、思维链提示、GRPO以及token-adapted GRPO;4) 使用RephQA评估不同策略的效果,并选择最优策略。
关键创新:论文的关键创新在于:1) 提出了RephQA基准,为评估LLM在公共健康问答中的可读性提供了一个标准;2) 提出了token-adapted GRPO策略,通过调整token生成概率,显著提升了LLM生成文本的可读性。这种方法针对可读性进行了专门优化,与传统的基于准确性的优化方法不同。
关键设计:RephQA基准包含533个QA对,涵盖13个主题。可读性评估指标包括Flesch-Kincaid grade level和专业评分。Token-adapted GRPO通过调整GRPO的奖励函数,使其更关注生成易于理解的token序列。具体来说,它使用可读性指标作为奖励信号,引导LLM生成更符合人类阅读习惯的文本。
🖼️ 关键图片


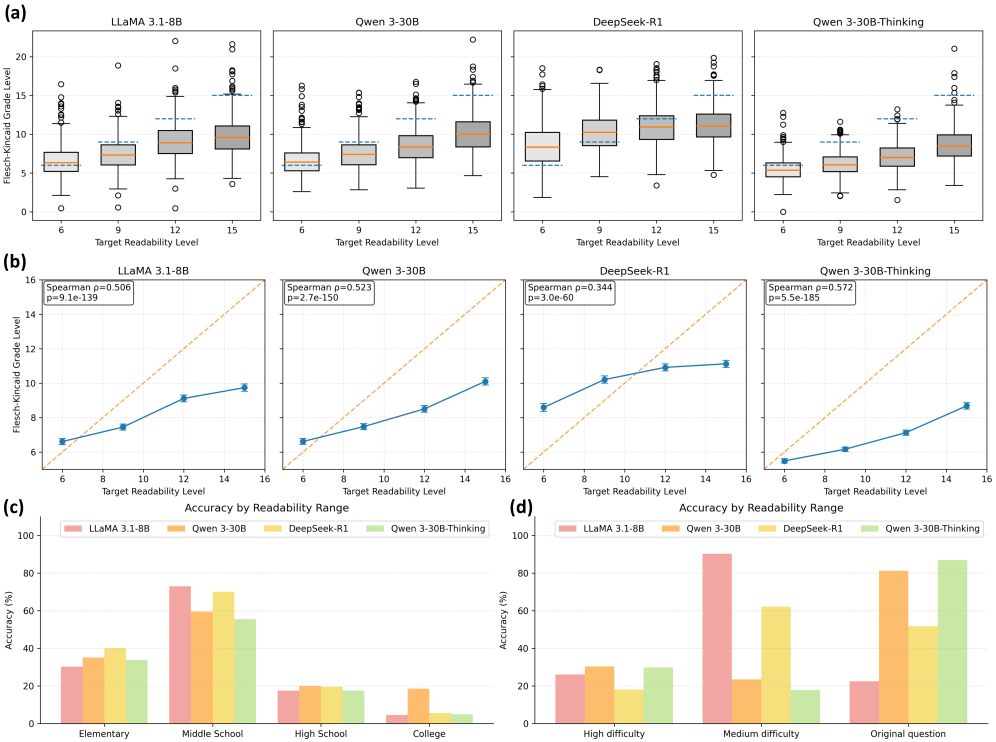
📊 实验亮点
实验结果表明,现有LLM在RephQA基准上的可读性表现不佳,大多数模型未能达到可读性标准。通过应用token-adapted GRPO策略,LLM生成文本的可读性得到了显著提升,在Flesch-Kincaid grade level和专业评分上均取得了最佳结果,表明该策略能够有效提升LLM在公共健康问答中的实用性。
🎯 应用场景
该研究成果可应用于构建用户友好的公共健康信息平台和智能助手,帮助非医学背景人群更好地理解健康知识,提升健康素养。未来,可将该方法推广到其他专业领域,例如法律、金融等,提升LLM在各领域的应用价值。
📄 摘要(原文)
Large Language Models (LLMs) hold promise in addressing complex medical problems. However, while most prior studies focus on improving accuracy and reasoning abilities, a significant bottleneck in developing effective healthcare agents lies in the readability of LLM-generated responses, specifically, their ability to answer public health problems clearly and simply to people without medical backgrounds. In this work, we introduce RephQA, a benchmark for evaluating the readability of LLMs in public health question answering (QA). It contains 533 expert-reviewed QA pairs from 27 sources across 13 topics, and includes a proxy multiple-choice task to assess informativeness, along with two readability metrics: Flesch-Kincaid grade level and professional score. Evaluation of 25 LLMs reveals that most fail to meet readability standards, highlighting a gap between reasoning and effective communication. To address this, we explore four readability-enhancing strategies-standard prompting, chain-of-thought prompting, Group Relative Policy Optimization (GRPO), and a token-adapted variant. Token-adapted GRPO achieves the best results, advancing the development of more practical and user-friendly public health agents. These results represent a step toward building more practical agents for public health.