Think, Verbalize, then Speak: Bridging Complex Thoughts and Comprehensible Speech
作者: Sang Hoon Woo, Sehun Lee, Kang-wook Kim, Gunhee Kim
分类: cs.CL, cs.AI
发布日期: 2025-09-19
备注: EMNLP 2025 Main. Project page: https://yhytoto12.github.io/TVS-ReVerT
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Think-Verbalize-Speak框架,解耦推理与口语表达,提升口语对话系统性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 口语对话系统 大型语言模型 推理与表达解耦 语音自然度 增量摘要
📋 核心要点
- 现有口语对话系统直接应用LLM,导致推理能力与口语表达不匹配,影响系统整体性能。
- 论文提出Think-Verbalize-Speak框架,通过中间步骤“verbalizing”将推理结果转化为自然口语文本。
- 实验表明,该方法在几乎不影响推理能力的前提下,显著提升了口语表达的自然性和简洁性。
📝 摘要(中文)
口语对话系统越来越多地采用大型语言模型(LLMs)来利用其先进的推理能力。然而,由于最佳文本和口头表达之间存在不匹配,直接在口语交流中应用LLMs通常会产生次优结果。虽然现有的方法调整LLMs以产生适合口语的输出,但它们对推理性能的影响仍未得到充分探索。在这项工作中,我们提出了Think-Verbalize-Speak,一个将推理与口语表达分离的框架,以保留LLMs的完整推理能力。我们方法的核心是verbalizing,一个将思想转化为自然、适合口语文本的中间步骤。我们还介绍了ReVerT,一种基于增量和异步摘要的、延迟高效的verbalizer。跨多个基准的实验表明,我们的方法在对推理影响最小的情况下,增强了语音的自然性和简洁性。包含数据集和源代码的项目页面可在https://yhytoto12.github.io/TVS-ReVerT 找到。
🔬 方法详解
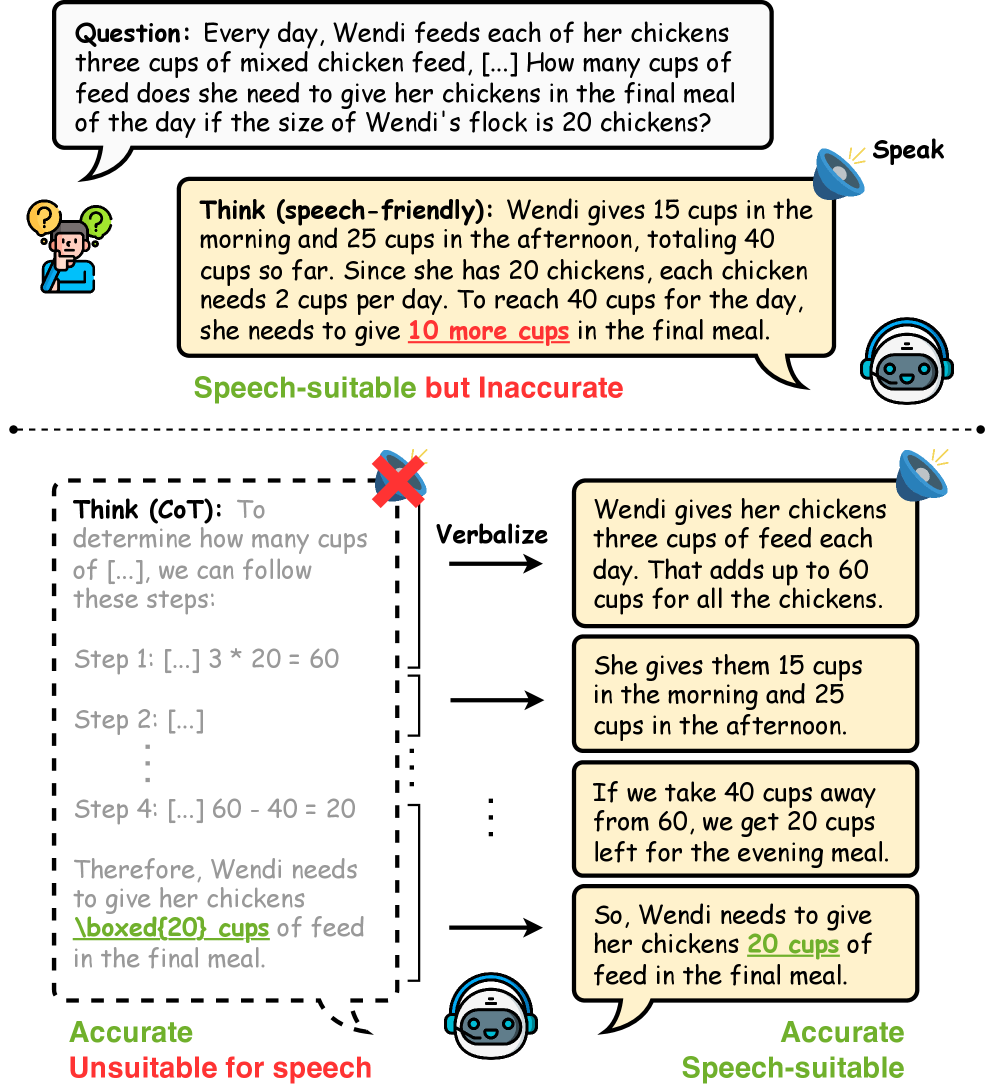
问题定义:现有口语对话系统直接使用大型语言模型(LLMs)进行推理和口语输出,但LLMs擅长生成书面文本,直接应用于口语场景会导致表达冗余、不自然,影响用户体验。同时,为了适应口语表达,对LLMs进行调整可能会牺牲其原有的推理能力。因此,如何平衡LLMs的推理能力和口语表达的自然性是一个关键问题。
核心思路:论文的核心思路是将LLMs的推理过程与口语表达过程解耦。通过引入一个中间步骤“verbalizing”,将LLMs的推理结果转化为自然、简洁、适合口语表达的文本。这样既能充分利用LLMs的推理能力,又能保证口语输出的质量。
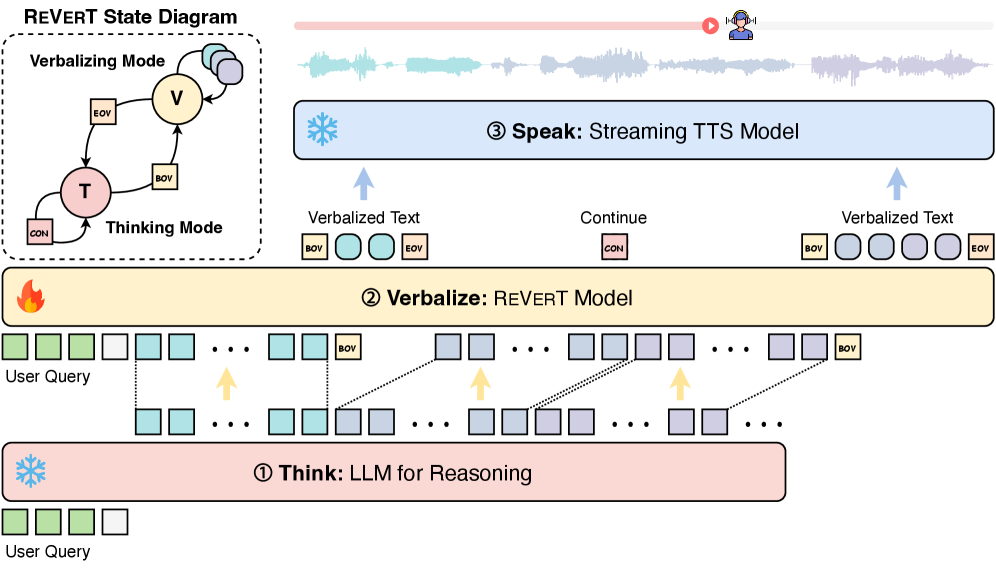
技术框架:Think-Verbalize-Speak框架包含三个主要阶段:Think、Verbalize和Speak。在Think阶段,LLM进行推理,生成原始的推理结果。在Verbalize阶段,verbalizer(论文中提出的ReVerT模型)将推理结果转化为适合口语表达的文本。在Speak阶段,文本到语音(TTS)模型将verbalized文本转化为语音输出。ReVerT采用增量和异步摘要技术,以实现低延迟的verbalizing。
关键创新:该论文的关键创新在于提出了Think-Verbalize-Speak框架,将推理与口语表达解耦,并引入了ReVerT模型作为高效的verbalizer。与现有方法相比,该方法能够更好地平衡LLMs的推理能力和口语表达的自然性。ReVerT的增量和异步摘要技术能够有效降低verbalizing的延迟,提高系统的实时性。
关键设计:ReVerT模型基于Transformer架构,采用增量摘要的方式逐步生成口语文本。为了进一步降低延迟,ReVerT采用异步摘要技术,允许在LLM推理的同时进行verbalizing。具体的损失函数和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Think-Verbalize-Speak框架在多个基准测试中显著提升了口语表达的自然性和简洁性,同时对推理性能的影响很小。与直接使用LLMs进行口语输出相比,该方法在语音自然度和简洁度指标上取得了显著提升(具体数值未知)。ReVerT模型也展现了其高效的verbalizing能力,能够有效降低延迟。
🎯 应用场景
该研究成果可广泛应用于各种口语对话系统,例如智能助手、聊天机器人、语音客服等。通过提升口语表达的自然性和简洁性,可以改善用户体验,提高对话系统的实用性。此外,该方法还可以应用于语音内容生成、语音翻译等领域,具有广阔的应用前景。
📄 摘要(原文)
Spoken dialogue systems increasingly employ large language models (LLMs) to leverage their advanced reasoning capabilities. However, direct application of LLMs in spoken communication often yield suboptimal results due to mismatches between optimal textual and verbal delivery. While existing approaches adapt LLMs to produce speech-friendly outputs, their impact on reasoning performance remains underexplored. In this work, we propose Think-Verbalize-Speak, a framework that decouples reasoning from spoken delivery to preserve the full reasoning capacity of LLMs. Central to our method is verbalizing, an intermediate step that translates thoughts into natural, speech-ready text. We also introduce ReVerT, a latency-efficient verbalizer based on incremental and asynchronous summarization. Experiments across multiple benchmarks show that our method enhances speech naturalness and conciseness with minimal impact on reasoning. The project page with the dataset and the source code is available at https://yhytoto12.github.io/TVS-ReVerT