Re-FRAME the Meeting Summarization SCOPE: Fact-Based Summarization and Personalization via Questions
作者: Frederic Kirstein, Sonu Kumar, Terry Ruas, Bela Gipp
分类: cs.CL, cs.AI
发布日期: 2025-09-19 (更新: 2025-11-14)
备注: Accepted at EMNLP 2025
DOI: 10.18653/v1/2025.findings-emnlp.1094
💡 一句话要点
提出FRAME框架和SCOPE协议,通过问题驱动的事实性摘要和个性化,提升会议摘要质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 会议摘要 大型语言模型 事实性摘要 个性化 语义增强 推理链 无参考评估
📋 核心要点
- 现有LLM会议摘要方法易产生幻觉、遗漏和不相关信息,缺乏可靠性和个性化。
- 提出FRAME框架,通过提取、组织和增强关键事实,将摘要任务重构为语义增强过程。
- 引入SCOPE协议和P-MESA评估框架,实验表明能有效减少幻觉和遗漏,提升个性化效果。
📝 摘要(中文)
大型语言模型(LLMs)在会议摘要中容易出错,产生幻觉、遗漏和不相关信息。本文提出了FRAME,一个模块化流程,将摘要重构为语义增强任务。FRAME提取并评估显著的事实,按主题组织,并用它们来丰富概要,生成抽象式摘要。为了个性化摘要,我们引入了SCOPE,一个“边思考边说话”协议,让模型通过回答九个问题来构建推理轨迹,然后进行内容选择。为了评估,我们提出了P-MESA,一个多维、无参考的评估框架,用于评估摘要是否适合目标读者。P-MESA能够可靠地识别错误实例,针对人工标注达到>=89%的平衡准确率,并且与人类严重程度评级高度一致(r >= 0.70)。在QMSum和FAME数据集上,FRAME将幻觉和遗漏减少了2/5(用MESA测量),而SCOPE在仅使用提示的基线上提高了知识契合度和目标对齐。我们的发现提倡重新思考摘要方法,以提高控制、忠实性和个性化。
🔬 方法详解
问题定义:现有基于大型语言模型的会议摘要方法存在幻觉、信息遗漏以及内容不相关等问题,导致摘要质量不高,难以满足用户对准确性和个性化的需求。这些问题源于模型对会议内容的理解不足以及缺乏对用户需求的精准把握。
核心思路:论文的核心思路是将会议摘要任务分解为语义增强的过程,通过提取和组织会议中的关键事实,并结合用户的个性化需求,生成更准确、更相关的摘要。这种方法旨在提高摘要的忠实度和个性化程度,从而解决现有方法的不足。
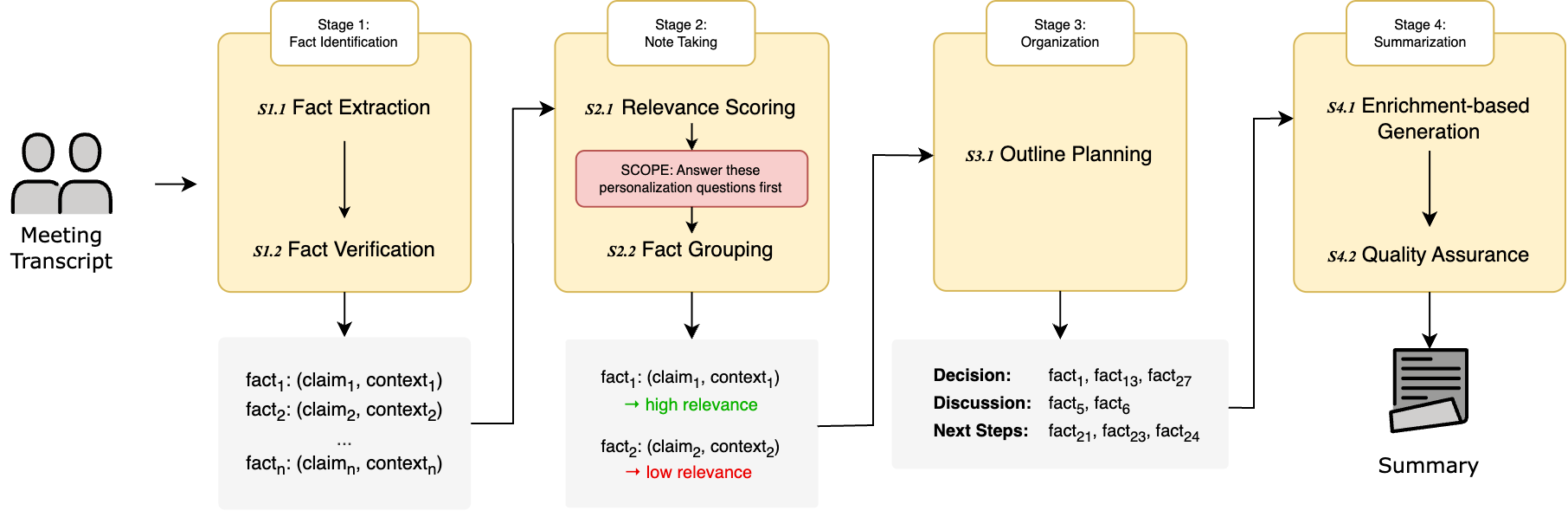
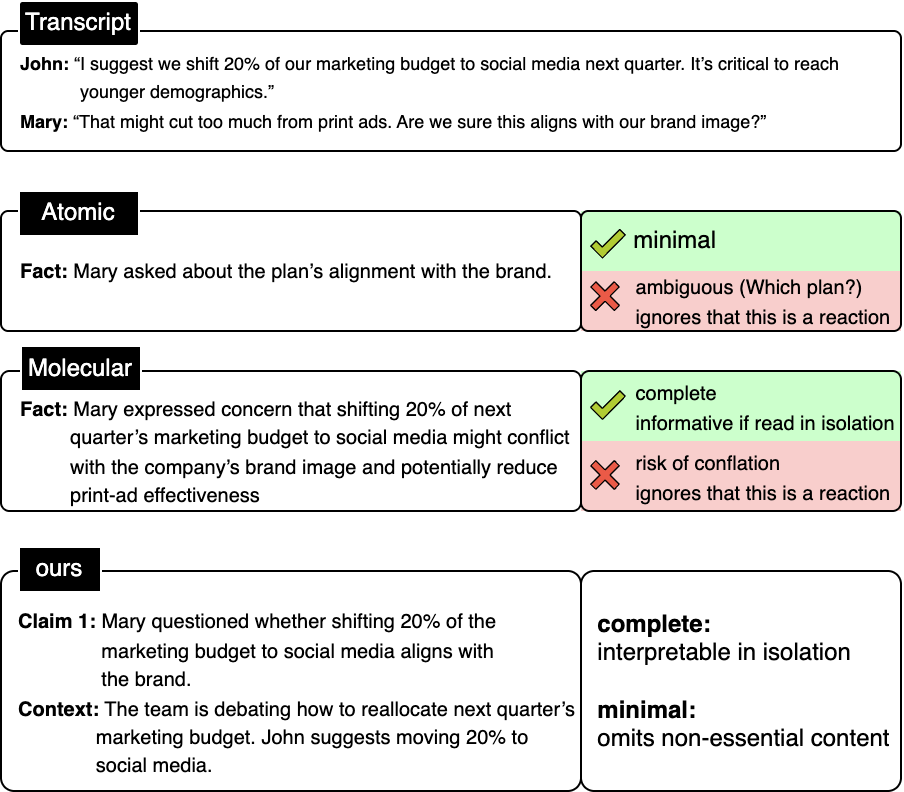
技术框架:FRAME框架包含以下主要模块:1) 事实提取和评分:从会议记录中提取关键事实,并根据其重要性进行评分。2) 主题组织:将提取的事实按主题进行组织,形成结构化的信息。3) 概要增强:利用组织好的事实来丰富概要,生成抽象式摘要。SCOPE协议则在内容选择前,通过让模型回答九个问题来构建推理轨迹,从而实现个性化。
关键创新:论文的关键创新在于将摘要任务重构为语义增强任务,并引入了SCOPE协议来实现个性化。FRAME框架通过提取和组织关键事实,提高了摘要的准确性和忠实度。SCOPE协议通过问题驱动的方式,使模型能够更好地理解用户的需求,从而生成更符合用户期望的摘要。
关键设计:SCOPE协议的关键设计在于精心设计的九个问题,这些问题旨在引导模型思考用户的背景、目标和偏好,从而构建个性化的推理轨迹。P-MESA评估框架则通过多维度评估摘要的质量,包括准确性、相关性和个性化程度,为模型的训练和优化提供了有效的反馈。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FRAME框架在QMSum和FAME数据集上,将幻觉和遗漏减少了2/5(用MESA测量)。SCOPE协议在仅使用提示的基线上提高了知识契合度和目标对齐。P-MESA评估框架针对人工标注达到>=89%的平衡准确率,并且与人类严重程度评级高度一致(r >= 0.70)。
🎯 应用场景
该研究成果可应用于各种需要会议摘要的场景,例如企业会议记录、在线教育课程总结、科研讨论会纪要等。通过提供更准确、更个性化的摘要,可以帮助用户快速了解会议内容,提高工作效率和学习效果。未来,该技术有望进一步发展,实现更智能化的会议内容理解和摘要生成。
📄 摘要(原文)
Meeting summarization with large language models (LLMs) remains error-prone, often producing outputs with hallucinations, omissions, and irrelevancies. We present FRAME, a modular pipeline that reframes summarization as a semantic enrichment task. FRAME extracts and scores salient facts, organizes them thematically, and uses these to enrich an outline into an abstractive summary. To personalize summaries, we introduce SCOPE, a reason-out-loud protocol that has the model build a reasoning trace by answering nine questions before content selection. For evaluation, we propose P-MESA, a multi-dimensional, reference-free evaluation framework to assess if a summary fits a target reader. P-MESA reliably identifies error instances, achieving >= 89% balanced accuracy against human annotations and strongly aligns with human severity ratings (r >= 0.70). On QMSum and FAME, FRAME reduces hallucination and omission by 2 out of 5 points (measured with MESA), while SCOPE improves knowledge fit and goal alignment over prompt-only baselines. Our findings advocate for rethinking summarization to improve control, faithfulness, and personalization.