Distribution-Aligned Decoding for Efficient LLM Task Adaptation
作者: Senkang Hu, Xudong Han, Jinqi Jiang, Yihang Tao, Zihan Fang, Yong Dai, Sam Tak Wu Kwong, Yuguang Fang
分类: cs.CL, cs.AI
发布日期: 2025-09-19 (更新: 2025-10-12)
备注: Accepted by NeurIPS'25
💡 一句话要点
提出SVDecode,通过分布对齐解码高效适应LLM下游任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 参数高效微调 分布对齐 解码策略 任务适配
📋 核心要点
- 现有PEFT方法在LLM任务适配中仍面临高昂的计算成本和效果瓶颈。
- SVDecode通过提取steering vector直接在解码阶段对齐输出分布,避免了权重更新。
- 实验表明,SVDecode在多个任务上显著提升了模型性能,且无需额外可训练参数。
📝 摘要(中文)
即使采用参数高效微调(PEFT),将数十亿参数的语言模型适配到下游任务仍然代价高昂。本文将任务适配重新定义为输出分布对齐:目标是在解码过程中直接引导输出分布趋向于任务分布,而不是通过权重更新间接实现。基于此,我们引入了Steering Vector Decoding (SVDecode),这是一种轻量级、兼容PEFT且具有理论基础的方法。我们首先进行一个简短的预热微调,并从预热微调模型和预训练模型的输出分布之间的Kullback-Leibler (KL)散度梯度中提取任务相关的steering vector。然后,该steering vector用于指导解码过程,以引导模型的输出分布趋向于任务分布。我们从理论上证明了SVDecode与完全微调的梯度步长一阶等价,并推导出steering vector强度的全局最优解。在三个任务和九个基准测试中,SVDecode与四种标准PEFT方法相结合,将多项选择题的准确率提高了高达5个百分点,并将开放式问题的真实性提高了2个百分点,在常识数据集上获得了类似的增益(1-2个百分点),而无需在PEFT适配器之外添加可训练参数。因此,SVDecode为大型语言模型提供了更强的任务适应性的轻量级、理论基础坚实的途径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在适应下游任务时,即使采用参数高效微调(PEFT)方法,仍然存在的计算成本高昂和性能提升有限的问题。现有PEFT方法主要通过更新少量参数来间接影响输出分布,效率较低,且可能无法充分捕捉任务特定的知识。
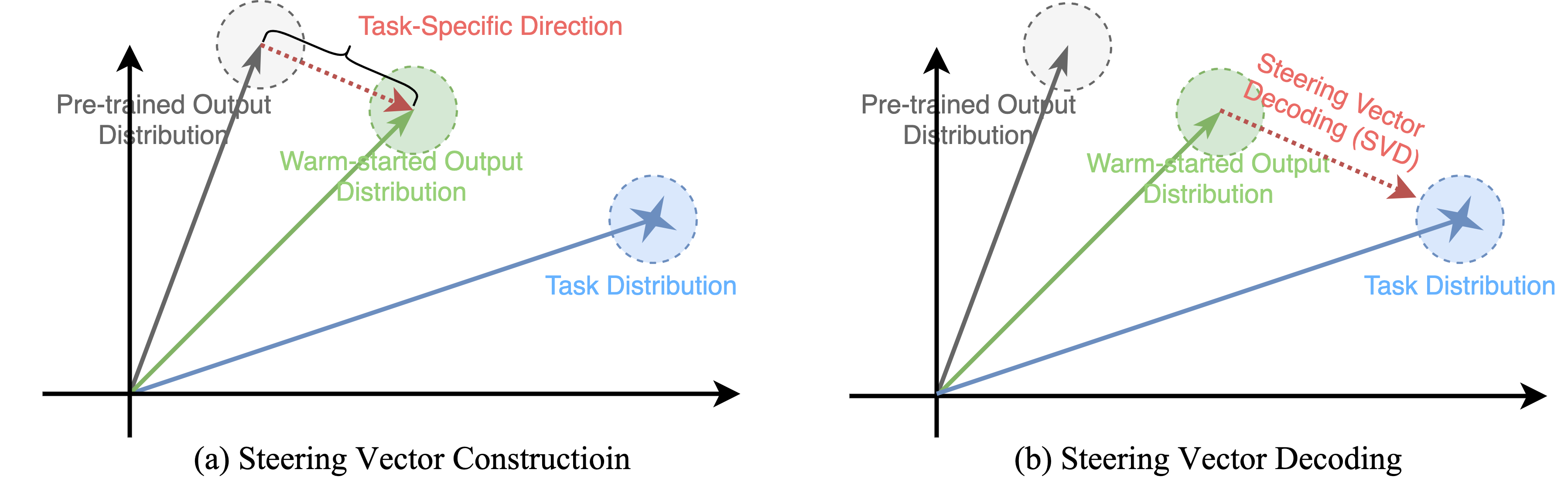
核心思路:论文的核心思路是将任务适配问题转化为输出分布对齐问题。通过直接在解码阶段引导模型的输出分布向目标任务的分布靠拢,避免了通过权重更新间接实现分布对齐的低效方式。这种方法的核心在于找到一个能够有效引导输出分布的“steering vector”。
技术框架:SVDecode方法主要包含以下几个阶段: 1. 预热微调(Warm-start Fine-tuning):使用少量数据对预训练模型进行快速微调,使其初步适应目标任务。 2. Steering Vector提取:计算预热微调模型和预训练模型输出分布之间的KL散度,并利用其梯度作为steering vector。该向量代表了从预训练分布到任务分布的最有效方向。 3. 解码阶段引导:在解码过程中,将steering vector添加到模型的隐藏状态中,从而引导模型的输出分布向目标任务分布靠拢。
关键创新:SVDecode的关键创新在于: 1. 分布对齐视角:将任务适配问题重新定义为输出分布对齐问题,为解决LLM任务适配问题提供了一个新的视角。 2. Steering Vector引导:通过提取steering vector直接在解码阶段引导输出分布,避免了传统PEFT方法中通过权重更新间接影响输出分布的低效方式。 3. 理论支撑:论文从理论上证明了SVDecode与完全微调的梯度步长一阶等价,并推导出了steering vector强度的全局最优解。
关键设计: 1. KL散度梯度:使用KL散度梯度作为steering vector,因为它能够有效地衡量两个分布之间的差异,并提供从一个分布到另一个分布的最有效方向。 2. Steering Vector强度:论文推导出了steering vector强度的全局最优解,确保了在解码过程中能够有效地引导输出分布,同时避免过度干预。 3. PEFT兼容性:SVDecode可以与现有的PEFT方法相结合,进一步提升模型性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SVDecode与四种标准PEFT方法相结合,在三个任务和九个基准测试中,将多项选择题的准确率提高了高达5个百分点,并将开放式问题的真实性提高了2个百分点。在常识数据集上,SVDecode也获得了1-2个百分点的增益,且无需在PEFT适配器之外添加可训练参数。这些结果验证了SVDecode在提升LLM任务适应性方面的有效性和高效性。
🎯 应用场景
SVDecode可广泛应用于各种需要快速且高效地将大型语言模型适配到特定下游任务的场景,例如:智能客服、文本摘要、机器翻译、代码生成等。该方法能够降低模型部署和维护成本,加速LLM在实际应用中的落地,并提升用户体验。未来,该方法有望扩展到更多模态和任务类型,进一步提升LLM的通用性和适应性。
📄 摘要(原文)
Adapting billion-parameter language models to a downstream task is still costly, even with parameter-efficient fine-tuning (PEFT). We re-cast task adaptation as output-distribution alignment: the objective is to steer the output distribution toward the task distribution directly during decoding rather than indirectly through weight updates. Building on this view, we introduce Steering Vector Decoding (SVDecode), a lightweight, PEFT-compatible, and theoretically grounded method. We start with a short warm-start fine-tune and extract a task-aware steering vector from the Kullback-Leibler (KL) divergence gradient between the output distribution of the warm-started and pre-trained models. This steering vector is then used to guide the decoding process to steer the model's output distribution towards the task distribution. We theoretically prove that SVDecode is first-order equivalent to the gradient step of full fine-tuning and derive a globally optimal solution for the strength of the steering vector. Across three tasks and nine benchmarks, SVDecode paired with four standard PEFT methods improves multiple-choice accuracy by up to 5 percentage points and open-ended truthfulness by 2 percentage points, with similar gains (1-2 percentage points) on commonsense datasets without adding trainable parameters beyond the PEFT adapter. SVDecode thus offers a lightweight, theoretically grounded path to stronger task adaptation for large language models.