Multi-Physics: A Comprehensive Benchmark for Multimodal LLMs Reasoning on Chinese Multi-Subject Physics Problems
作者: Zhongze Luo, Zhenshuai Yin, Yongxin Guo, Zhichao Wang, Jionghao Zhu, Xiaoying Tang
分类: cs.CL
发布日期: 2025-09-19
🔗 代码/项目: GITHUB
💡 一句话要点
提出Multi-Physics:用于评估多模态LLM在中文物理问题上推理能力的综合基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 物理推理 中文基准 科学推理
📋 核心要点
- 现有物理推理评估基准缺乏细粒度的学科覆盖、忽略逐步推理过程,且主要以英文为中心,未能充分评估视觉信息的作用。
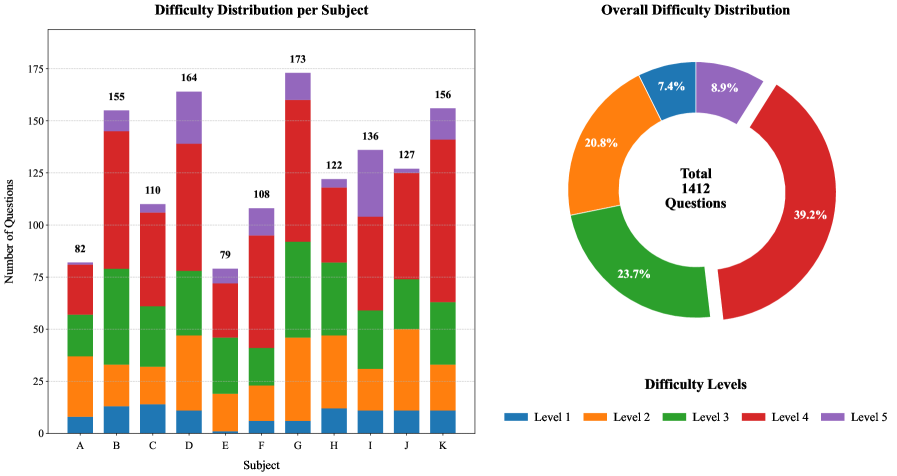
- Multi-Physics基准包含1412道图像关联的中文物理题,覆盖11个高中物理学科,并提供5个难度级别,用于更全面地评估模型。
- 通过双重评估框架,分析MLLM最终答案准确性和逐步推理过程的完整性,并研究难度级别和视觉信息对模型性能的影响。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在推理方面取得了显著进展,但将其应用于物理等专业科学领域时,现有的评估基准存在明显不足。具体而言,现有基准通常缺乏细粒度的学科覆盖,忽略了逐步推理过程,并且主要以英语为中心,未能系统地评估视觉信息的作用。因此,我们推出了Multi-Physics,一个用于中文物理推理的综合基准,包含5个难度级别,涵盖11个高中物理学科的1,412个图像关联的多项选择题。我们采用双重评估框架来评估20个不同的MLLM,分析最终答案的准确性和逐步推理过程的完整性。此外,我们通过比较改变输入模式前后模型的性能,系统地研究了难度级别和视觉信息的影响。我们的工作不仅为社区提供了细粒度的资源,还为剖析最先进的MLLM的多模态推理过程提供了稳健的方法,我们的数据集和代码已开源。
🔬 方法详解
问题定义:现有针对多模态大型语言模型(MLLMs)在物理问题上的推理能力评估基准存在不足。这些基准通常缺乏对物理学科的细粒度覆盖,无法全面评估模型在不同物理概念上的理解和应用能力。此外,现有基准往往忽略了逐步推理过程的评估,无法判断模型是否真正理解了解题思路,还是仅仅通过某种捷径得到了正确答案。最后,现有基准大多以英文为主,缺乏对中文物理问题的支持,限制了对MLLMs在中文环境下的推理能力的评估。
核心思路:Multi-Physics基准的核心思路是构建一个全面、细粒度、多难度的中文物理问题数据集,并设计一个双重评估框架,既评估最终答案的准确性,又评估逐步推理过程的完整性。通过这种方式,可以更深入地了解MLLMs在解决中文物理问题时的优势和不足,并为未来的模型改进提供指导。同时,通过对比不同难度级别和不同输入模式(有无视觉信息)下模型的表现,可以进一步分析模型对物理概念的理解程度以及对视觉信息的利用能力。
技术框架:Multi-Physics基准主要包含以下几个部分:1)数据集构建:收集并整理了1412道图像关联的中文物理问题,涵盖11个高中物理学科,并根据难度分为5个级别。2)模型评估:采用双重评估框架,首先评估模型最终答案的准确性,然后评估模型逐步推理过程的完整性。3)性能分析:对比不同模型在不同难度级别和不同输入模式下的表现,分析模型对物理概念的理解程度以及对视觉信息的利用能力。
关键创新:Multi-Physics基准的关键创新在于其全面性、细粒度和双重评估框架。与现有基准相比,Multi-Physics覆盖了更广泛的物理学科,提供了更细粒度的难度划分,并采用了更全面的评估方法。这使得Multi-Physics能够更准确地评估MLLMs在中文物理问题上的推理能力,并为未来的模型改进提供更有效的指导。
关键设计:数据集构建方面,题目来源于真实的高中物理试题,保证了题目的质量和难度。难度分级由物理专家进行标注,保证了难度分级的准确性。评估框架方面,最终答案准确性采用标准的多项选择题评估方法。逐步推理过程的完整性评估则需要人工进行判断,判断模型是否给出了正确的解题思路和步骤。
🖼️ 关键图片


📊 实验亮点
通过对20个不同的MLLM进行评估,发现模型在Multi-Physics基准上的表现参差不齐,表明现有模型在中文物理推理方面仍有很大的提升空间。实验结果还表明,视觉信息对模型的性能有显著影响,但不同模型对视觉信息的利用能力存在差异。此外,模型在不同难度级别上的表现也存在差异,表明模型对不同难度级别的物理概念的理解程度不同。
🎯 应用场景
该研究成果可应用于教育领域,辅助学生学习物理,并为教师提供教学参考。同时,该基准可用于评估和提升多模态大型语言模型在科学领域的推理能力,推动人工智能在科学研究中的应用。未来,该研究可扩展到其他科学领域,构建更通用的科学推理基准。
📄 摘要(原文)
While multimodal LLMs (MLLMs) demonstrate remarkable reasoning progress, their application in specialized scientific domains like physics reveals significant gaps in current evaluation benchmarks. Specifically, existing benchmarks often lack fine-grained subject coverage, neglect the step-by-step reasoning process, and are predominantly English-centric, failing to systematically evaluate the role of visual information. Therefore, we introduce \textbf {Multi-Physics} for Chinese physics reasoning, a comprehensive benchmark that includes 5 difficulty levels, featuring 1,412 image-associated, multiple-choice questions spanning 11 high-school physics subjects. We employ a dual evaluation framework to evaluate 20 different MLLMs, analyzing both final answer accuracy and the step-by-step integrity of their chain-of-thought. Furthermore, we systematically study the impact of difficulty level and visual information by comparing the model performance before and after changing the input mode. Our work provides not only a fine-grained resource for the community but also offers a robust methodology for dissecting the multimodal reasoning process of state-of-the-art MLLMs, and our dataset and code have been open-sourced: https://github.com/luozhongze/Multi-Physics.