The Curious Case of Visual Grounding: Different Effects for Speech- and Text-based Language Encoders
作者: Adrian Sauter, Willem Zuidema, Marianne de Heer Kloots
分类: cs.CL
发布日期: 2025-09-19
备注: 5 pages, 3 figures, Submitted to ICASSP 2026
💡 一句话要点
研究视觉信息融入对语音和文本语言编码器内部表征的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉基础 语音编码器 文本编码器 表征学习 多模态学习
📋 核心要点
- 现有语音和文本模型在融合视觉信息时效果差异大,缺乏对内部表征影响的深入理解。
- 通过比较视觉信息融入后语音和文本编码器内部表征的差异,揭示视觉基础对语音和文本理解的不同影响。
- 实验表明视觉基础增强了语音和文本表征的一致性,但对语音模型的语义区分能力提升有限。
📝 摘要(中文)
本文研究了训练中包含的视觉信息如何影响基于音频和文本的深度学习模型中的语言处理。我们探索了这种视觉基础如何影响模型内部的词语表征,并发现语音和文本语言编码器存在显著不同的影响。首先,全局表征比较表明,视觉基础增加了口语和书面语言表征之间的一致性,但这种影响似乎主要由增强的词语身份编码驱动,而非语义。然后,我们应用有针对性的聚类分析来探究模型表征中的语音与语义可区分性。语音表征在视觉基础下仍然以语音为主导,但与文本表征相反,视觉基础并没有提高语义可区分性。我们的发现可以为开发更有效的方法以利用视觉信息丰富语音模型语义提供有益的参考。
🔬 方法详解
问题定义:现有语音和文本模型在融入视觉信息进行训练时,其内部语言表征受到的影响机制尚不明确。特别是,语音模型是否能像文本模型一样,通过视觉信息提升语义理解能力,是一个待解决的问题。现有方法缺乏对视觉信息如何影响语音和文本模型内部表征的细致分析,阻碍了更有效多模态语音理解模型的开发。
核心思路:本文的核心思路是通过对比分析视觉信息融入训练后,语音和文本编码器内部表征的变化,来揭示视觉基础对两种模态语言理解的不同影响。具体而言,通过全局表征比较和有针对性的聚类分析,探究视觉基础如何影响词语身份编码、语音可区分性和语义可区分性。
技术框架:整体框架包括以下几个主要步骤:1) 使用包含视觉信息的训练数据分别训练语音和文本编码器;2) 对比分析视觉基础前后,语音和文本表征的全局一致性;3) 应用聚类分析,探究语音和文本表征中语音和语义的可区分性;4) 分析视觉基础对语音和文本模型在词语身份编码、语音可区分性和语义可区分性上的不同影响。
关键创新:该研究的关键创新在于:1) 首次系统性地对比分析了视觉基础对语音和文本编码器内部表征的不同影响;2) 采用全局表征比较和有针对性的聚类分析相结合的方法,深入探究了视觉基础对词语身份编码、语音可区分性和语义可区分性的影响;3) 揭示了视觉基础对语音模型的语义区分能力提升有限,为未来多模态语音理解模型的设计提供了新的思路。
关键设计:论文中使用了预训练的语音和文本编码器,并使用包含视觉信息的图像-文本对数据进行微调。全局表征比较使用了Representational Similarity Analysis (RSA) 方法。聚类分析使用了k-means算法,并针对语音和语义类别设计了特定的聚类目标。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片

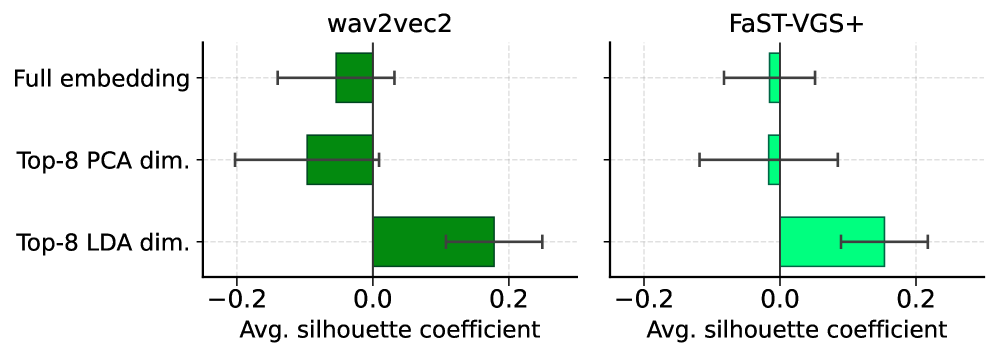
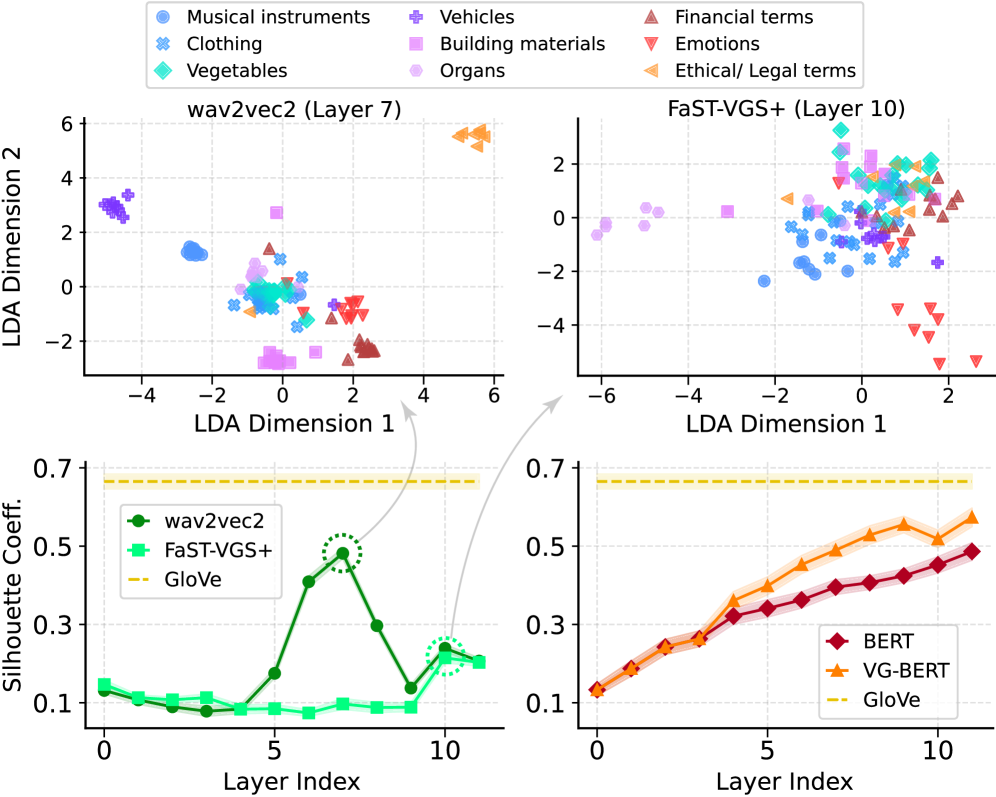
📊 实验亮点
实验结果表明,视觉基础增加了口语和书面语言表征之间的一致性,但主要由增强的词语身份编码驱动。与文本表征相反,视觉基础并没有显著提高语音表征的语义可区分性。这些发现为未来多模态语音理解模型的设计提供了重要的指导。
🎯 应用场景
该研究成果可应用于改进语音助手、语音翻译等应用。通过更有效地将视觉信息融入语音模型,可以提升语音理解的准确性和鲁棒性。未来的研究可以探索如何设计更有效的视觉-语音融合机制,以提升语音模型的语义理解能力,并应用于更广泛的多模态人机交互场景。
📄 摘要(原文)
How does visual information included in training affect language processing in audio- and text-based deep learning models? We explore how such visual grounding affects model-internal representations of words, and find substantially different effects in speech- vs. text-based language encoders. Firstly, global representational comparisons reveal that visual grounding increases alignment between representations of spoken and written language, but this effect seems mainly driven by enhanced encoding of word identity rather than meaning. We then apply targeted clustering analyses to probe for phonetic vs. semantic discriminability in model representations. Speech-based representations remain phonetically dominated with visual grounding, but in contrast to text-based representations, visual grounding does not improve semantic discriminability. Our findings could usefully inform the development of more efficient methods to enrich speech-based models with visually-informed semantics.