Best-of-L: Cross-Lingual Reward Modeling for Mathematical Reasoning
作者: Sara Rajaee, Rochelle Choenni, Ekaterina Shutova, Christof Monz
分类: cs.CL, cs.AI
发布日期: 2025-09-19
💡 一句话要点
提出Best-of-L跨语言奖励模型,提升多语言LLM在数学推理任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言学习 奖励模型 数学推理 多语言LLM 自然语言处理
📋 核心要点
- 多语言LLM的推理能力在不同语言间存在差异,且不同语言的推理路径可能互补,但现有研究对此关注不足。
- 论文提出跨语言奖励模型,对不同语言生成的答案进行排序,从而选择更优的推理路径。
- 实验表明,该模型显著提升了多语言LLM在数学推理任务中的性能,尤其是在低采样预算下对英语提升明显。
📝 摘要(中文)
大型语言模型(LLM)的推理能力不断提升,但多语言LLM中这种能力在不同语言之间的差异,以及不同语言是否能产生互补的推理路径,仍然不清楚。为了研究这个问题,我们训练了一个奖励模型,用于对给定问题的跨语言生成响应进行排序。结果表明,与在单一语言内使用奖励模型相比,我们的跨语言奖励模型显著提高了数学推理性能,甚至对高资源语言也有益处。虽然英语在多语言模型中通常表现出最高的性能,但我们发现,在低采样预算下,跨语言采样尤其有利于英语。我们的发现揭示了通过利用不同语言的互补优势来提高多语言推理的新机会。
🔬 方法详解
问题定义:论文旨在解决多语言大型语言模型在数学推理任务中,不同语言之间推理能力差异的问题。现有方法通常只关注单一语言内的奖励建模,忽略了不同语言可能提供的互补信息,导致模型性能受限。
核心思路:论文的核心思路是利用跨语言的奖励建模,即训练一个能够评估不同语言生成的答案质量的奖励模型。通过比较和选择不同语言的输出,模型可以学习到不同语言在解决数学问题时的优势,从而提升整体的推理能力。
技术框架:整体框架包括以下几个主要步骤:1) 使用多语言LLM生成针对同一数学问题的多种语言的答案;2) 使用跨语言奖励模型对这些答案进行排序,奖励模型的目标是预测答案的质量;3) 根据奖励模型的排序结果,选择最优的答案作为最终输出。这个过程可以看作是一个“Best-of-L”的策略,即从L种语言的输出中选择最佳结果。
关键创新:最重要的创新点在于跨语言奖励模型的训练和应用。传统的奖励模型通常只针对单一语言进行训练,而该论文提出的模型能够同时处理多种语言的答案,并学习不同语言之间的关联性。这种跨语言的建模方式能够更好地利用多语言LLM的潜力,提升其推理能力。
关键设计:奖励模型的设计可能涉及以下关键细节:1) 使用Transformer架构作为奖励模型的基础;2) 使用对比学习或排序损失函数来训练奖励模型,使其能够区分不同质量的答案;3) 考虑不同语言之间的差异,例如使用语言嵌入或适配器来调整模型参数;4) 在推理阶段,可以使用不同的采样策略来生成多种语言的答案,例如温度采样或Top-k采样。
🖼️ 关键图片


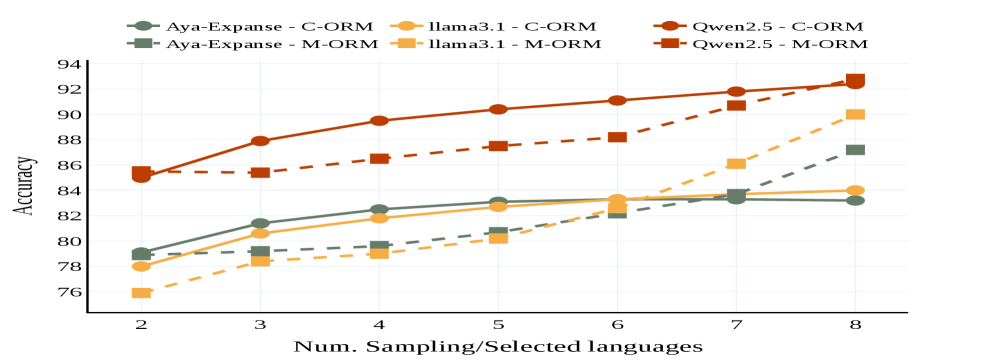
📊 实验亮点
实验结果表明,跨语言奖励模型在数学推理任务中显著优于单一语言奖励模型,即使对于英语等高资源语言,也能获得性能提升。在低采样预算下,跨语言采样对英语的提升尤为明显,这表明该方法能够有效利用不同语言的互补优势。
🎯 应用场景
该研究成果可应用于提升多语言LLM在各种需要数学推理能力的场景中的性能,例如自动问答系统、智能教育平台、金融分析等。通过利用不同语言的优势,可以构建更强大、更可靠的多语言智能系统,促进跨文化交流和知识共享。
📄 摘要(原文)
While the reasoning abilities of large language models (LLMs) continue to advance, it remains unclear how such ability varies across languages in multilingual LLMs and whether different languages produce reasoning paths that complement each other. To investigate this question, we train a reward model to rank generated responses for a given question across languages. Our results show that our cross-lingual reward model substantially improves mathematical reasoning performance compared to using reward modeling within a single language, benefiting even high-resource languages. While English often exhibits the highest performance in multilingual models, we find that cross-lingual sampling particularly benefits English under low sampling budgets. Our findings reveal new opportunities to improve multilingual reasoning by leveraging the complementary strengths of diverse languages.