UniGist: Towards General and Hardware-aligned Sequence-level Long Context Compression
作者: Chenlong Deng, Zhisong Zhang, Kelong Mao, Shuaiyi Li, Tianqing Fang, Hongming Zhang, Haitao Mi, Dong Yu, Zhicheng Dou
分类: cs.CL
发布日期: 2025-09-19
备注: 15 pages, 7 figures
💡 一句话要点
UniGist:面向通用和硬件对齐的序列级长文本上下文压缩框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本压缩 序列级压缩 上下文建模 键值缓存 大型语言模型
📋 核心要点
- 长文本KV缓存的内存开销是LLM部署瓶颈,序列级压缩会损失重要上下文信息。
- UniGist用特殊压缩token(gist)替换原始token,细粒度保留上下文信息。
- UniGist采用无chunk训练策略和gist shift技巧,优化GPU训练,提升压缩质量。
📝 摘要(中文)
大型语言模型处理长文本输入的能力日益增强,但键值(KV)缓存的内存开销仍然是通用部署的主要瓶颈。尽管已经探索了各种压缩策略,但序列级压缩(即删除某些token的完整KV缓存)尤其具有挑战性,因为它可能导致重要上下文信息的丢失。为了解决这个问题,我们引入了UniGist,这是一个序列级长文本上下文压缩框架,它通过以细粒度的方式用特殊的压缩token(gist)替换原始token来有效地保留上下文信息。我们采用无chunk的训练策略,并设计了一个带有gist shift技巧的高效内核,从而实现了优化的GPU训练。我们的方案还支持灵活的推理,允许实际删除压缩的token,从而实现实时的内存节省。跨多个长文本上下文任务的实验表明,UniGist显著提高了压缩质量,尤其是在细节回忆任务和长程依赖建模方面表现出色。
🔬 方法详解
问题定义:现有的大型语言模型在处理长文本时,KV缓存会占用大量内存,成为部署的瓶颈。序列级压缩虽然可以减少内存占用,但直接丢弃某些token的KV缓存会导致关键上下文信息的丢失,影响模型性能。因此,如何在压缩长文本的同时,尽可能保留重要的上下文信息是一个关键问题。
核心思路:UniGist的核心思路是用特殊的压缩token(gist)来代替原始token,从而在减少内存占用的同时,保留原始token的上下文信息。这种方法不是简单地丢弃token,而是用一种更紧凑的方式来表示token的含义,从而在压缩和性能之间取得平衡。
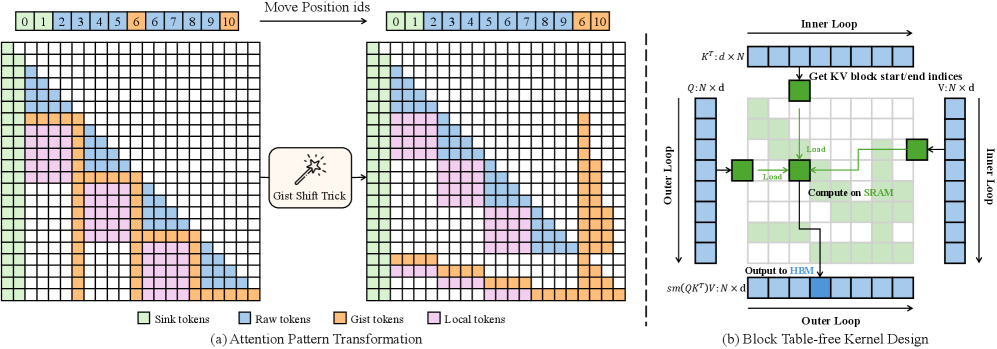
技术框架:UniGist的整体框架包括一个训练阶段和一个推理阶段。在训练阶段,模型学习如何将原始token压缩成gist token。在推理阶段,模型可以使用gist token进行推理,从而减少内存占用。为了优化训练过程,UniGist采用了无chunk的训练策略,并设计了一个带有gist shift技巧的高效内核。
关键创新:UniGist的关键创新在于使用gist token来代替原始token,从而实现细粒度的上下文压缩。与传统的序列级压缩方法相比,UniGist可以更好地保留上下文信息,从而提高模型性能。此外,UniGist的无chunk训练策略和gist shift技巧可以有效地提高训练效率。
关键设计:UniGist的关键设计包括:1) Gist token的表示方式:如何设计gist token,使其能够有效地表示原始token的上下文信息?2) 损失函数:如何设计损失函数,使得模型能够学习到高质量的gist token?3) Gist shift技巧:如何设计gist shift技巧,以提高训练效率?这些细节的设计直接影响着UniGist的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,UniGist在多个长文本上下文任务上显著提高了压缩质量。尤其是在细节回忆任务和长程依赖建模方面,UniGist表现出色。与现有方法相比,UniGist可以在保持甚至提高模型性能的同时,显著减少内存占用。具体性能数据需要在论文中查找。
🎯 应用场景
UniGist可应用于各种需要处理长文本的场景,例如长文档摘要、问答系统、机器翻译等。通过减少KV缓存的内存占用,UniGist可以使大型语言模型更容易部署在资源受限的设备上,例如移动设备和边缘设备。此外,UniGist还可以用于加速长文本推理,提高用户体验。
📄 摘要(原文)
Large language models are increasingly capable of handling long-context inputs, but the memory overhead of key-value (KV) cache remains a major bottleneck for general-purpose deployment. While various compression strategies have been explored, sequence-level compression, which drops the full KV caches for certain tokens, is particularly challenging as it can lead to the loss of important contextual information. To address this, we introduce UniGist, a sequence-level long-context compression framework that efficiently preserves context information by replacing raw tokens with special compression tokens (gists) in a fine-grained manner. We adopt a chunk-free training strategy and design an efficient kernel with a gist shift trick, enabling optimized GPU training. Our scheme also supports flexible inference by allowing the actual removal of compressed tokens, resulting in real-time memory savings. Experiments across multiple long-context tasks demonstrate that UniGist significantly improves compression quality, with especially strong performance in detail-recalling tasks and long-range dependency modeling.