VOX-KRIKRI: Unifying Speech and Language through Continuous Fusion
作者: Dimitrios Damianos, Leon Voukoutis, Georgios Paraskevopoulos, Vassilis Katsouros
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-09-19
💡 一句话要点
VOX-KRIKRI:通过连续融合统一语音和语言
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音LLM 多模态融合 跨模态注意力 连续空间融合 自动语音识别 低资源语音 希腊语
📋 核心要点
- 现有语音LLM通常直接使用音频嵌入,忽略了语音和语言之间的语义鸿沟,导致对齐效果不佳。
- 论文提出一种连续融合框架,通过中间的音频条件文本空间对齐语音和语言表示,提升跨模态对齐效果。
- 实验表明,该方法在希腊语语音识别上取得了SOTA结果,相对提升约20%,验证了其有效性。
📝 摘要(中文)
本文提出了一种多模态融合框架,旨在通过连接预训练的基于解码器的大型语言模型(LLM)和声学编码器-解码器架构(如Whisper)来构建支持语音的LLM。该方法没有直接使用音频嵌入,而是探索中间的音频条件文本空间,作为更有效的对齐机制。该方法完全在连续文本表示空间中运行,通过跨模态注意力将Whisper的隐藏解码器状态与LLM的隐藏状态融合,并支持离线和流式模式。我们推出了第一个希腊语语音LLM——VoxKrikri,并通过分析表明,我们的方法有效地对齐了跨模态的表示。这些结果表明,连续空间融合是多语言和低资源语音LLM的一个有希望的途径,同时在希腊语自动语音识别方面取得了最先进的结果,在基准测试中平均提高了约20%的相对性能。
🔬 方法详解
问题定义:现有语音LLM构建方法,如直接使用音频嵌入,难以有效对齐语音和语言两种模态的信息。这导致模型在处理语音相关任务时,性能受到限制,尤其是在多语言和低资源场景下,问题更为突出。现有方法的痛点在于缺乏有效的跨模态对齐机制,无法充分利用预训练LLM的语言能力。
核心思路:论文的核心思路是利用一个中间的音频条件文本空间,作为语音和语言模态之间的桥梁。通过将语音信息转换为文本表示,并以此调节LLM的文本处理过程,实现更有效的跨模态对齐。这种方法避免了直接在原始音频特征空间进行融合,从而降低了学习难度,并更好地利用了预训练LLM的知识。
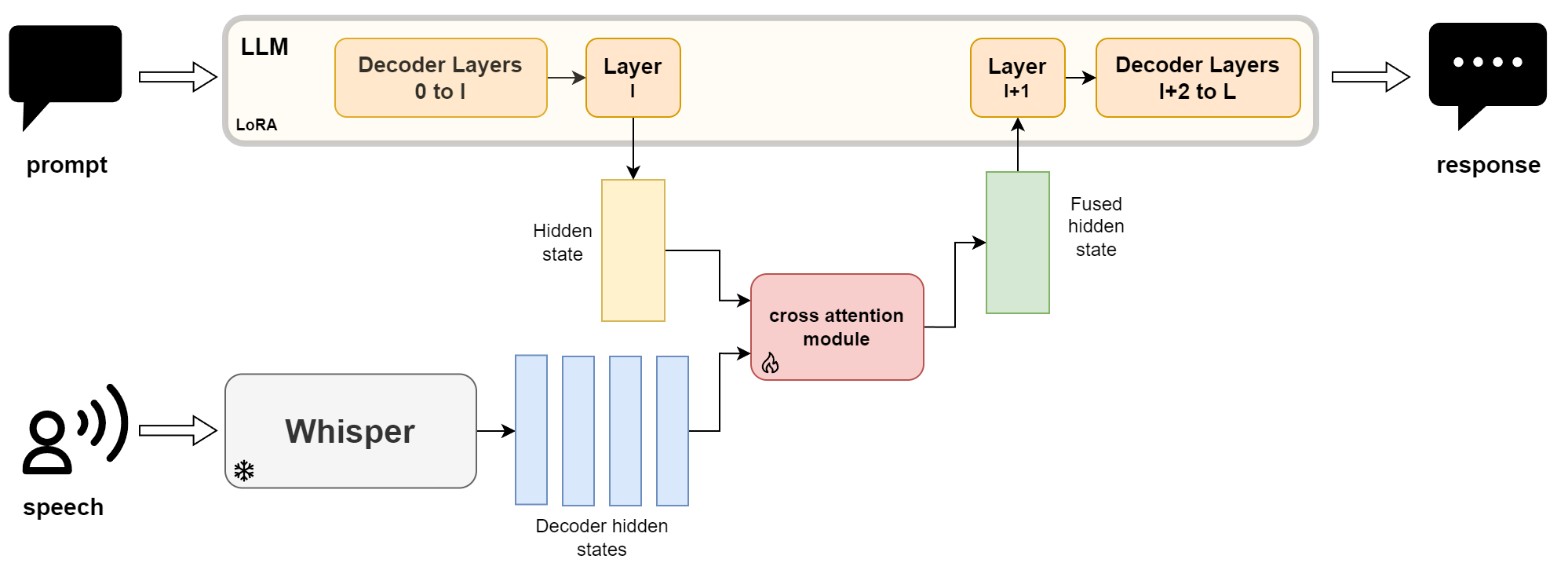
技术框架:整体框架包含一个声学编码器-解码器(如Whisper)和一个预训练的LLM。Whisper负责将语音转换为隐藏解码器状态,这些状态随后被用于调节LLM的文本处理过程。具体而言,通过跨模态注意力机制,将Whisper的隐藏状态与LLM的隐藏状态融合。整个过程在连续文本表示空间中进行,支持离线和流式两种模式。
关键创新:最重要的技术创新点在于提出了中间音频条件文本空间的概念,并将其应用于跨模态融合。与直接融合音频嵌入的方法相比,这种方法能够更好地对齐语音和语言的语义信息,从而提升模型的性能。此外,该框架具有通用性,可以应用于不同的声学模型和LLM。
关键设计:论文使用了跨模态注意力机制来实现Whisper隐藏状态和LLM隐藏状态的融合。具体来说,Whisper的隐藏状态作为query,LLM的隐藏状态作为key和value,通过注意力机制计算融合后的表示。损失函数方面,论文可能采用了标准的语言模型损失函数,并可能结合了其他辅助损失函数来提升模型的性能。具体的网络结构细节和参数设置在论文中应该有更详细的描述。
🖼️ 关键图片
📊 实验亮点
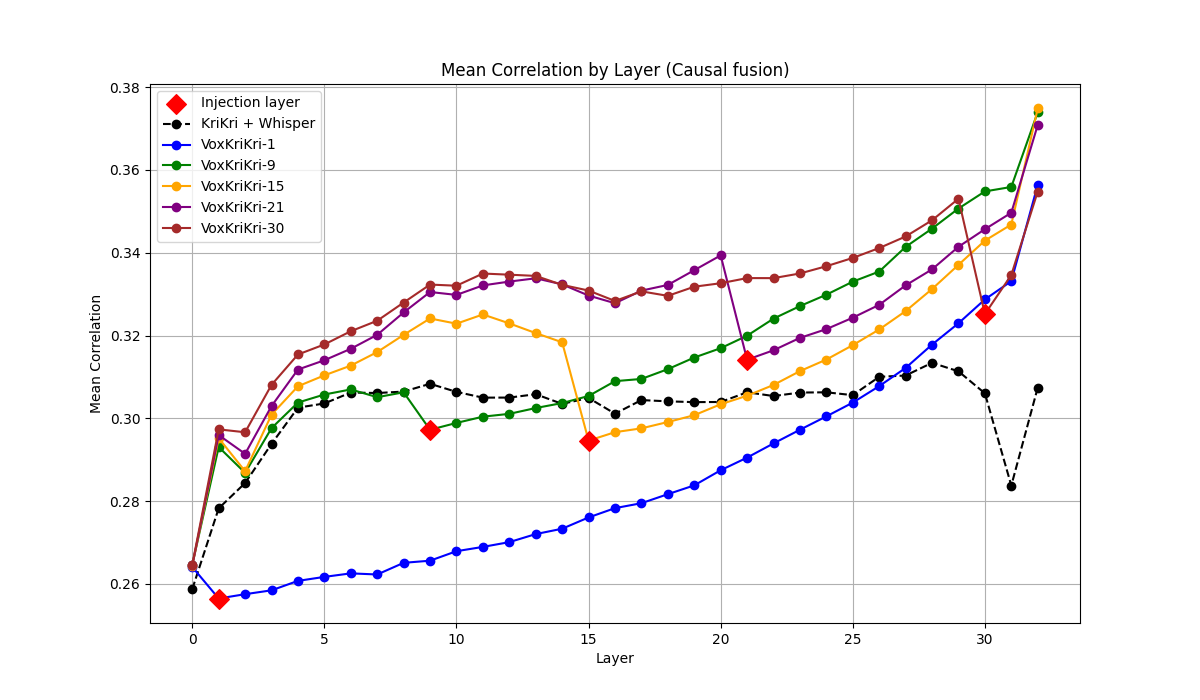
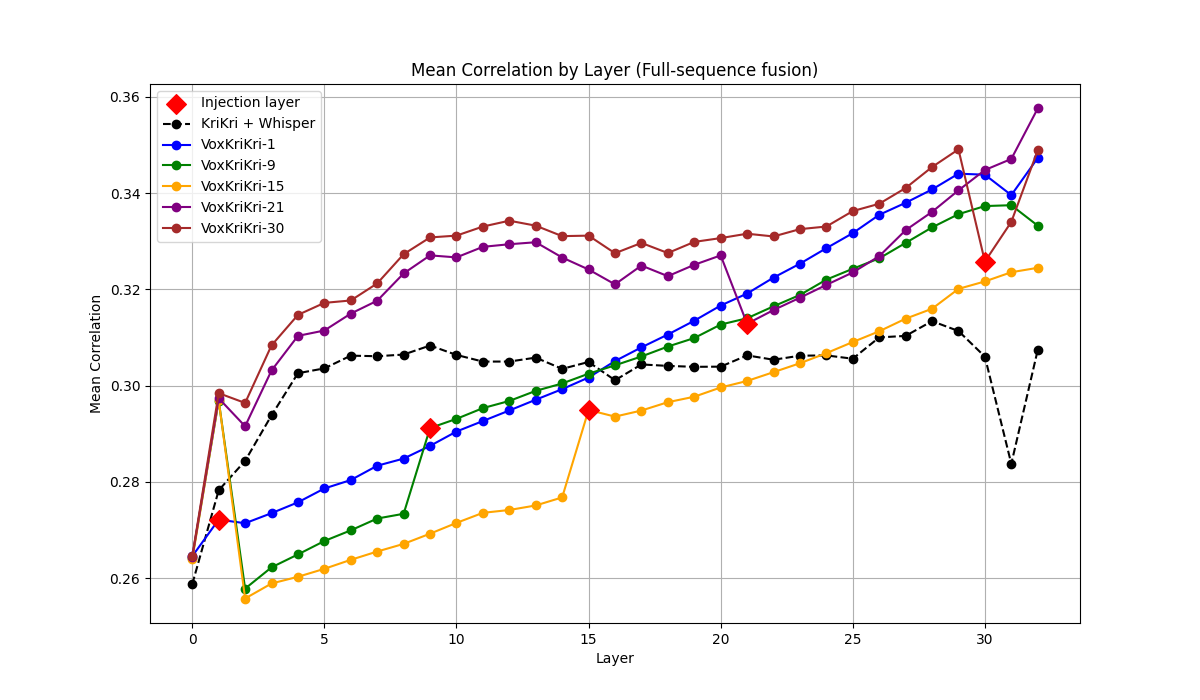
论文构建了第一个希腊语语音LLM——VoxKrikri,并在希腊语自动语音识别任务上取得了最先进的结果。实验结果表明,该方法在多个基准测试中平均提高了约20%的相对性能,显著优于现有方法,验证了所提出框架的有效性。
🎯 应用场景
该研究成果可应用于多种场景,如语音助手、语音翻译、语音搜索等。特别是在多语言和低资源场景下,该方法具有更大的应用潜力。通过构建支持语音的LLM,可以实现更自然、更智能的人机交互,并为语音相关任务提供更强大的解决方案。未来,该方法有望推动语音技术在各个领域的广泛应用。
📄 摘要(原文)
We present a multimodal fusion framework that bridges pre-trained decoder-based large language models (LLM) and acoustic encoder-decoder architectures such as Whisper, with the aim of building speech-enabled LLMs. Instead of directly using audio embeddings, we explore an intermediate audio-conditioned text space as a more effective mechanism for alignment. Our method operates fully in continuous text representation spaces, fusing Whisper's hidden decoder states with those of an LLM through cross-modal attention, and supports both offline and streaming modes. We introduce \textit{VoxKrikri}, the first Greek speech LLM, and show through analysis that our approach effectively aligns representations across modalities. These results highlight continuous space fusion as a promising path for multilingual and low-resource speech LLMs, while achieving state-of-the-art results for Automatic Speech Recognition in Greek, providing an average $\sim20\%$ relative improvement across benchmarks.