Sparse-Autoencoder-Guided Internal Representation Unlearning for Large Language Models
作者: Tomoya Yamashita, Akira Ito, Yuuki Yamanaka, Masanori Yamada, Takayuki Miura, Toshiki Shibahara
分类: cs.CL, cs.LG
发布日期: 2025-09-19
💡 一句话要点
提出基于稀疏自编码器的内部表征解学习方法,提升大语言模型遗忘效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 遗忘学习 内部表征 稀疏自编码器 隐私保护
📋 核心要点
- 现有LLM遗忘方法主要通过抑制不良输出来实现,无法真正消除模型内部的知识,且易导致模型崩溃。
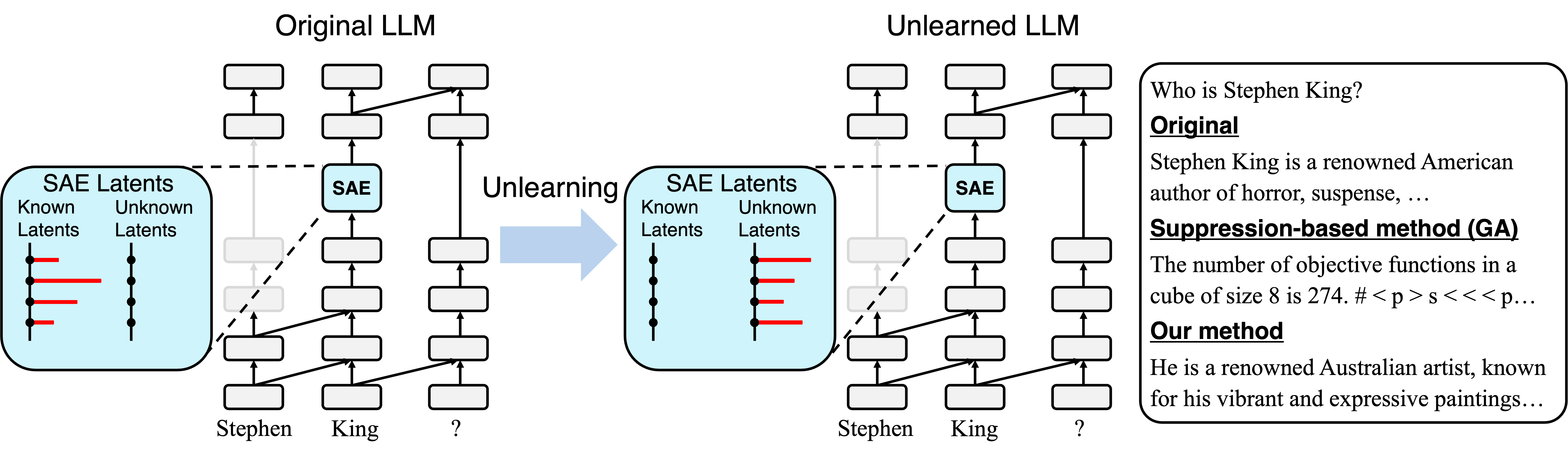
- 论文提出一种新颖的遗忘方法,通过稀疏自编码器将目标实体的内部激活与“未知”实体的激活对齐。
- 实验表明,该方法能有效对齐内部激活,减少模型对目标知识的回忆,同时避免对非目标知识的损害。
📝 摘要(中文)
随着大型语言模型(LLMs)在各种应用中的日益普及,隐私和版权问题日益突出,对更有效的LLM遗忘技术的需求也随之增加。许多现有的遗忘方法旨在通过额外的训练(例如,梯度上升)来抑制不良输出,从而降低生成此类输出的概率。虽然这种基于抑制的方法可以控制模型输出,但它们可能无法消除嵌入在模型内部激活中的底层知识;抑制响应并不等同于忘记它。此外,这种基于抑制的方法通常会遭受模型崩溃。为了解决这些问题,我们提出了一种新颖的遗忘方法,该方法直接干预模型的内部激活。在我们的公式中,遗忘被定义为一种状态,其中遗忘目标的激活与“未知”实体的激活无法区分。我们的方法引入了一个遗忘目标,该目标将目标实体的激活从已知实体的激活转移到稀疏自编码器潜在空间中未知实体的激活。通过将目标的内部激活与未知实体的内部激活对齐,我们将模型对目标实体的识别从“已知”转变为“未知”,从而实现真正的遗忘,同时避免过度抑制和模型崩溃。经验表明,我们的方法有效地对齐了遗忘目标的内部激活,这是基于抑制的方法无法可靠实现的。此外,我们的方法有效地减少了模型在问答任务中对目标知识的回忆,而不会对非目标知识造成重大损害。
🔬 方法详解
问题定义:现有的大语言模型遗忘方法,例如基于梯度上升的抑制方法,主要通过降低模型生成特定输出的概率来实现“遗忘”。然而,这些方法并不能真正消除模型内部存储的相关知识,仅仅是抑制了输出。此外,这些方法容易导致模型性能下降甚至模型崩溃。因此,需要一种能够真正从模型内部消除特定知识,同时保持模型整体性能的遗忘方法。
核心思路:论文的核心思路是将“遗忘”定义为一种状态,即模型对目标实体的内部表征与对“未知”实体的内部表征无法区分。通过将目标实体的内部激活状态向“未知”实体的激活状态对齐,使得模型不再能够识别该目标实体,从而实现真正的遗忘。这种方法避免了直接抑制输出,从而降低了模型崩溃的风险。
技术框架:该方法主要包含以下几个步骤:1. 使用稀疏自编码器学习模型内部激活的潜在空间表示。2. 收集“已知”实体和“未知”实体的激活数据,并将其映射到潜在空间。3. 定义一个遗忘目标,该目标旨在将目标实体的激活在潜在空间中移动,使其更接近“未知”实体的激活,远离“已知”实体的激活。4. 使用优化算法更新模型参数,以最小化遗忘目标。
关键创新:该方法最重要的创新点在于其对“遗忘”的定义以及实现遗忘的方式。与传统的基于抑制的方法不同,该方法直接干预模型的内部表征,通过将目标实体的表征与“未知”实体的表征对齐来实现遗忘。这种方法更接近于人类的遗忘机制,并且能够避免过度抑制带来的负面影响。
关键设计:关键设计包括:1. 稀疏自编码器的结构和训练方式,用于学习有效的内部激活潜在空间表示。2. “未知”实体的选择策略,需要选择与目标实体语义上无关的实体,以保证遗忘的有效性。3. 遗忘目标的具体形式,例如可以使用均方误差损失函数来衡量目标实体激活与“未知”实体激活之间的距离。4. 优化算法的选择和参数设置,例如学习率、迭代次数等。
🖼️ 关键图片

📊 实验亮点
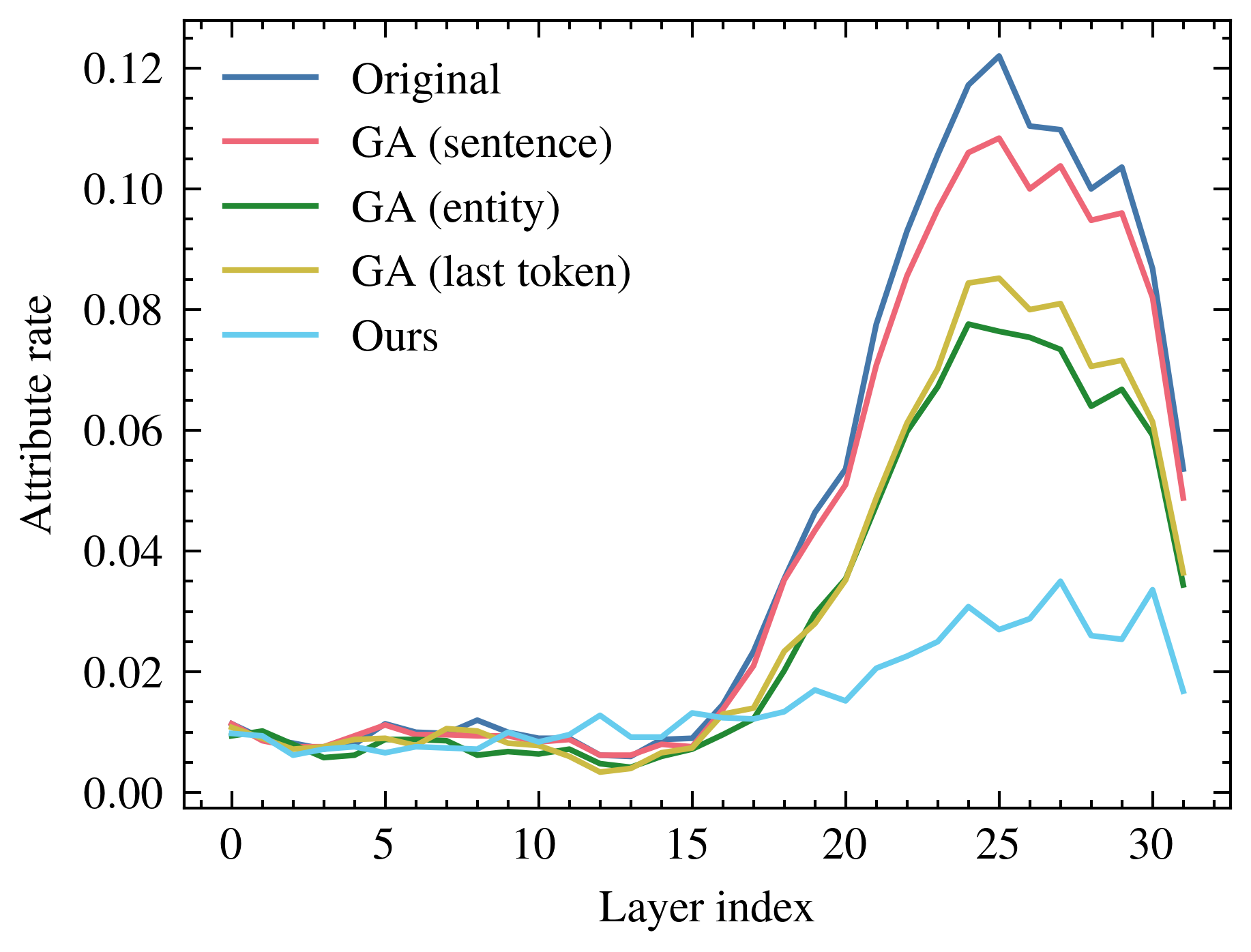
实验结果表明,该方法能够有效对齐遗忘目标的内部激活,显著降低模型在问答任务中对目标知识的回忆,同时对非目标知识的影响较小。与基于抑制的方法相比,该方法能够更可靠地实现遗忘,并且避免了模型崩溃的问题。实验数据表明,该方法在遗忘特定知识的同时,能够保持模型整体性能。
🎯 应用场景
该研究成果可应用于各种需要保护隐私和版权的场景,例如:从大型语言模型中移除个人身份信息、删除侵权内容、防止模型泄露商业机密等。该方法能够有效提升LLM的安全性,促进其在金融、医疗等敏感领域的应用。未来,该技术有望发展成为一种通用的LLM安全工具。
📄 摘要(原文)
As large language models (LLMs) are increasingly deployed across various applications, privacy and copyright concerns have heightened the need for more effective LLM unlearning techniques. Many existing unlearning methods aim to suppress undesirable outputs through additional training (e.g., gradient ascent), which reduces the probability of generating such outputs. While such suppression-based approaches can control model outputs, they may not eliminate the underlying knowledge embedded in the model's internal activations; muting a response is not the same as forgetting it. Moreover, such suppression-based methods often suffer from model collapse. To address these issues, we propose a novel unlearning method that directly intervenes in the model's internal activations. In our formulation, forgetting is defined as a state in which the activation of a forgotten target is indistinguishable from that of
unknown'' entities. Our method introduces an unlearning objective that modifies the activation of the target entity away from those of known entities and toward those of unknown entities in a sparse autoencoder latent space. By aligning the target's internal activation with those of unknown entities, we shift the model's recognition of the target entity fromknown'' to ``unknown'', achieving genuine forgetting while avoiding over-suppression and model collapse. Empirically, we show that our method effectively aligns the internal activations of the forgotten target, a result that the suppression-based approaches do not reliably achieve. Additionally, our method effectively reduces the model's recall of target knowledge in question-answering tasks without significant damage to the non-target knowledge.