Concept Unlearning in Large Language Models via Self-Constructed Knowledge Triplets
作者: Tomoya Yamashita, Yuuki Yamanaka, Masanori Yamada, Takayuki Miura, Toshiki Shibahara, Tomoharu Iwata
分类: cs.CL, cs.LG
发布日期: 2025-09-19
💡 一句话要点
提出基于自构建知识三元组的大语言模型概念遗忘方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 机器遗忘 概念遗忘 知识图谱 知识三元组
📋 核心要点
- 现有机器遗忘方法依赖于明确的目标句子,无法有效移除人物、事件等更广泛的概念。
- 论文提出概念遗忘(CU)方法,利用知识图表示LLM内部知识,通过移除目标节点和边实现概念移除。
- 实验结果表明,该方法在实现概念级别遗忘的同时,能够有效保留无关知识。
📝 摘要(中文)
机器遗忘(MU)作为解决大语言模型(LLM)中隐私和版权问题的方案,近年来备受关注。现有的MU方法旨在从LLM中移除特定的目标句子,同时最大限度地减少对无关知识的损害。然而,这些方法需要明确的目标句子,并且不支持移除更广泛的概念,例如人物或事件。为了解决这个局限性,我们引入了概念遗忘(CU)作为LLM遗忘的一个新要求。我们利用知识图来表示LLM的内部知识,并将CU定义为移除遗忘目标节点和相关边。这种基于图的公式能够实现更直观的遗忘,并促进更有效方法的设计。我们提出了一种新颖的方法,该方法提示LLM生成关于遗忘目标的知识三元组和解释性句子,并将遗忘过程应用于这些表示。通过将遗忘过程与LLM的内部知识表示对齐,我们的方法能够实现更精确和全面的概念移除。在真实世界和合成数据集上的实验表明,我们的方法有效地实现了概念级别的遗忘,同时保留了无关的知识。
🔬 方法详解
问题定义:现有的大语言模型(LLM)机器遗忘方法主要关注于删除特定的句子,无法处理更广泛的概念遗忘,例如删除关于某个特定人物或事件的所有相关知识。这些方法需要明确的目标句子作为输入,并且难以保证彻底删除所有相关信息,同时可能对模型中其他无关知识造成损害。
核心思路:论文的核心思路是将LLM的内部知识表示为知识图,其中节点代表概念,边代表概念之间的关系。概念遗忘的目标被定义为从知识图中移除与特定概念相关的节点和边。为了实现这一目标,论文提出了一种方法,首先让LLM生成关于遗忘目标的知识三元组和解释性句子,然后对这些表示进行遗忘处理。
技术框架:该方法主要包含以下几个阶段: 1. 知识三元组生成:利用提示工程(Prompt Engineering)技术,引导LLM生成关于遗忘目标的知识三元组(例如:实体-关系-实体)和解释性句子。 2. 知识表示对齐:将生成的知识三元组和解释性句子与LLM的内部知识表示进行对齐,确保遗忘过程能够作用于LLM的内部知识。 3. 遗忘过程应用:使用特定的遗忘算法(具体算法未在摘要中提及,属于未知细节)对对齐后的知识表示进行处理,以移除与遗忘目标相关的知识。 4. 评估:评估遗忘效果,包括遗忘目标是否被成功移除,以及对无关知识的影响。
关键创新:该方法最重要的创新点在于将概念遗忘问题转化为知识图上的节点和边移除问题,并利用LLM自身生成知识三元组来辅助遗忘过程。这种方法能够更精确地定位和删除与遗忘目标相关的知识,并且能够处理更广泛的概念遗忘任务。与现有方法相比,该方法不需要明确的目标句子作为输入,而是通过知识三元组来表示遗忘目标,从而更加灵活和有效。
关键设计:摘要中没有提供关于具体参数设置、损失函数、网络结构等技术细节。这些细节属于未知信息,需要在论文正文中查找。
🖼️ 关键图片

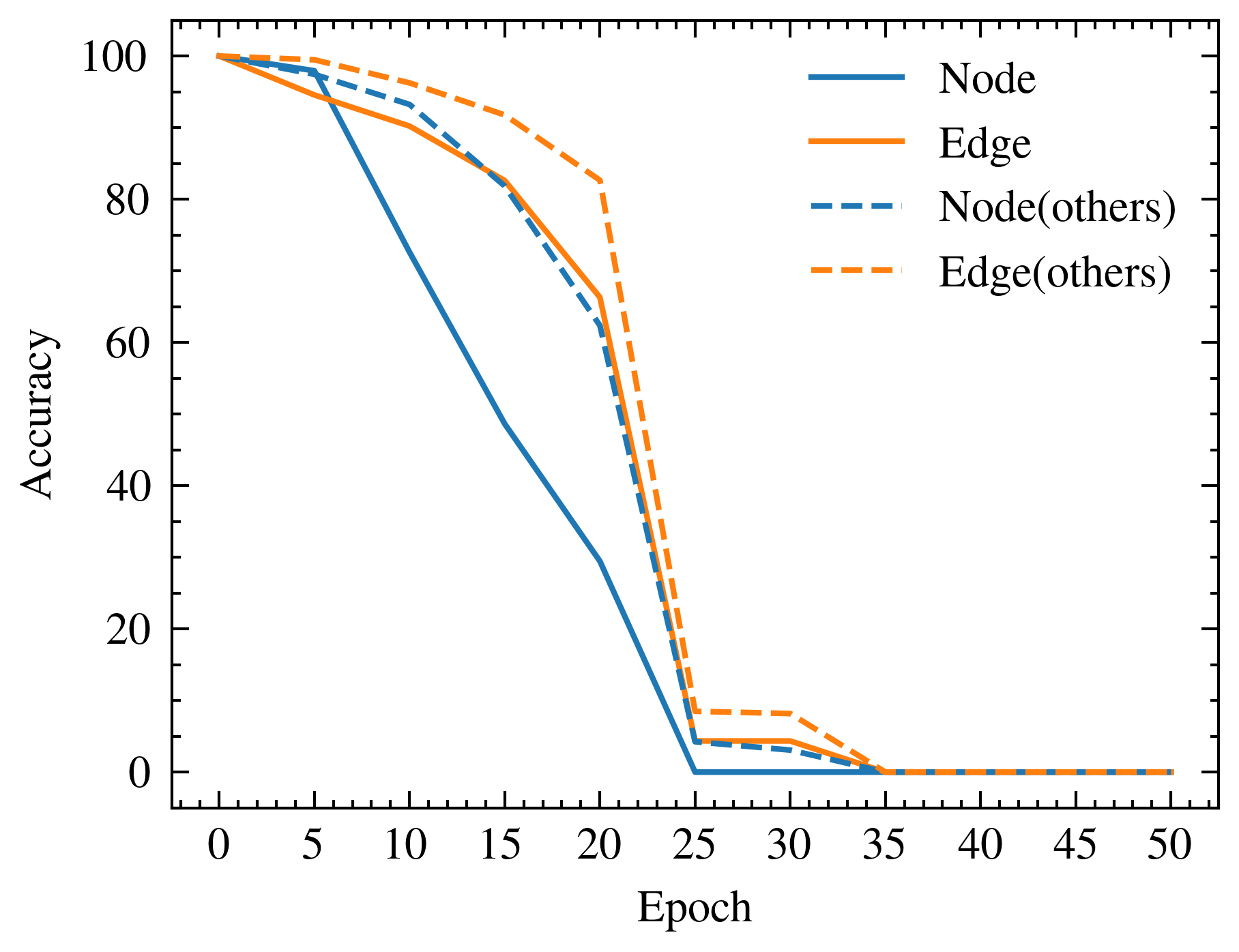
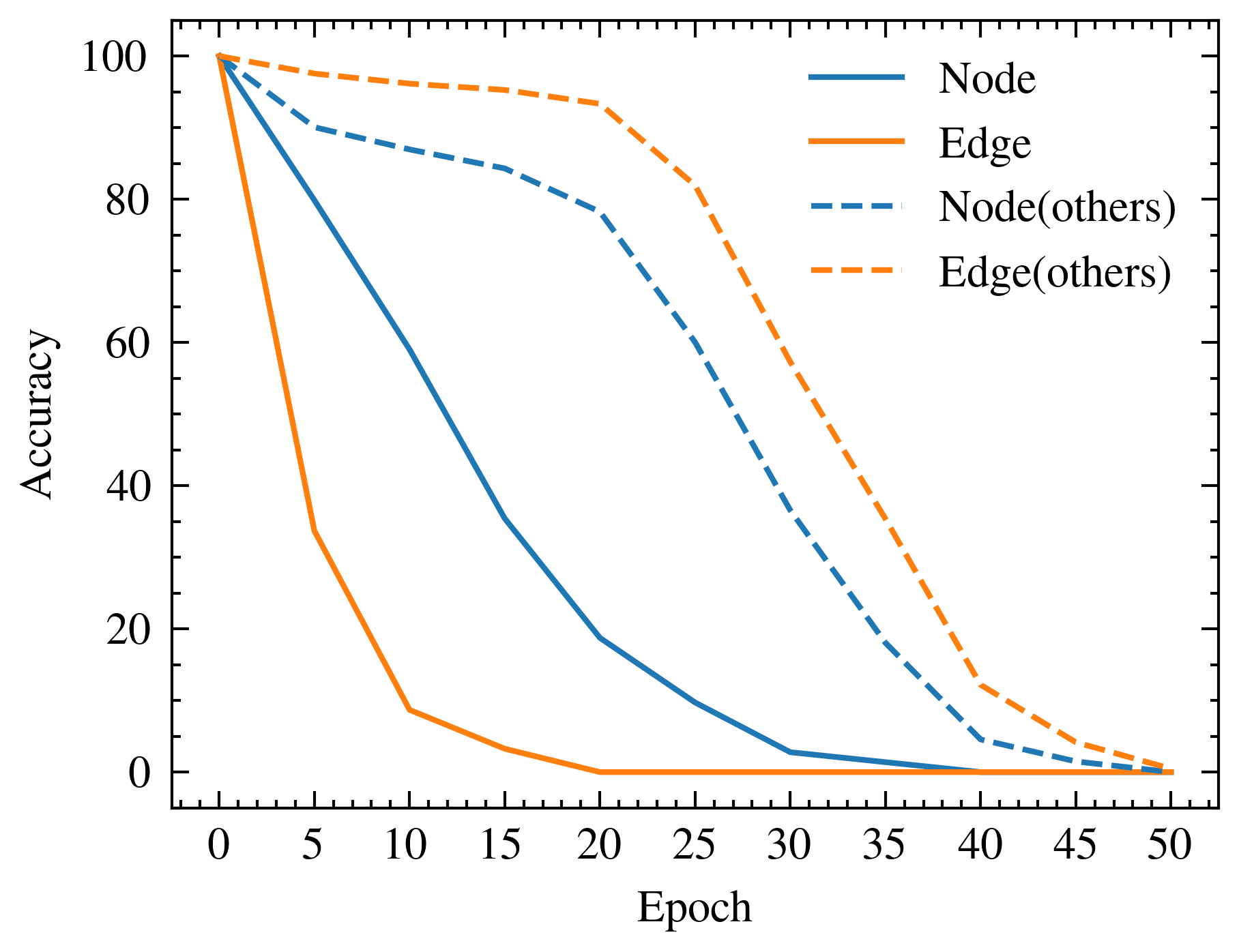
📊 实验亮点
论文在真实世界和合成数据集上进行了实验,证明了该方法能够有效地实现概念级别的遗忘,同时保留无关知识。具体的性能数据、对比基线和提升幅度等细节需要在论文正文中查找,摘要中未提供。
🎯 应用场景
该研究成果可应用于保护用户隐私、维护版权以及防止LLM生成有害或不准确的信息。例如,可以用于删除LLM中关于特定个人的敏感信息,或者移除关于虚假事件的错误知识。该技术还有助于提高LLM的可控性和安全性,使其能够更好地服务于人类社会。
📄 摘要(原文)
Machine Unlearning (MU) has recently attracted considerable attention as a solution to privacy and copyright issues in large language models (LLMs). Existing MU methods aim to remove specific target sentences from an LLM while minimizing damage to unrelated knowledge. However, these approaches require explicit target sentences and do not support removing broader concepts, such as persons or events. To address this limitation, we introduce Concept Unlearning (CU) as a new requirement for LLM unlearning. We leverage knowledge graphs to represent the LLM's internal knowledge and define CU as removing the forgetting target nodes and associated edges. This graph-based formulation enables a more intuitive unlearning and facilitates the design of more effective methods. We propose a novel method that prompts the LLM to generate knowledge triplets and explanatory sentences about the forgetting target and applies the unlearning process to these representations. Our approach enables more precise and comprehensive concept removal by aligning the unlearning process with the LLM's internal knowledge representations. Experiments on real-world and synthetic datasets demonstrate that our method effectively achieves concept-level unlearning while preserving unrelated knowledge.