SciEvent: Benchmarking Multi-domain Scientific Event Extraction
作者: Bofu Dong, Pritesh Shah, Sumedh Sonawane, Tiyasha Banerjee, Erin Brady, Xinya Du, Ming Jiang
分类: cs.CL
发布日期: 2025-09-19
备注: 9 pages, 8 figures (main); 22 pages, 11 figures (appendix). Accepted to EMNLP 2025 (Main Conference)
💡 一句话要点
SciEvent:提出多领域科学事件抽取基准,促进科学内容结构化理解。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学信息抽取 事件抽取 多领域学习 自然语言处理 基准数据集
📋 核心要点
- 现有科学信息抽取方法依赖于窄领域实体关系抽取,缺乏跨领域适用性和上下文理解能力。
- SciEvent提出统一的事件抽取模式,构建多领域科学摘要数据集,实现科学内容的结构化理解。
- 实验表明,现有模型在社会学和人文学科等领域表现不佳,SciEvent为提升模型泛化能力提供基准。
📝 摘要(中文)
科学信息抽取(SciIE)主要依赖于狭窄领域的实体关系抽取,限制了其在跨学科研究中的应用,并且难以捕捉科学信息的必要上下文,导致语句碎片化或冲突。本文提出了SciEvent,这是一个新的多领域基准,包含通过统一事件抽取(EE)模式标注的科学摘要,旨在实现对科学内容的结构化和上下文感知理解。它包括五个研究领域的500篇摘要,以及事件片段、触发词和细粒度论元的标注。我们将SciIE定义为一个多阶段EE流程:(1)将摘要分割为核心科学活动--背景、方法、结果和结论;(2)提取相应的触发词和论元。使用微调的EE模型、大型语言模型(LLM)和人工标注者的实验表明存在性能差距,当前模型在社会学和人文学科等领域表现不佳。SciEvent作为一个具有挑战性的基准,是迈向通用、多领域SciIE的一步。
🔬 方法详解
问题定义:现有的科学信息抽取方法主要集中在特定领域,并且依赖于实体关系抽取,这导致了两个主要问题:一是跨领域适用性差,难以应用于不同学科的研究;二是缺乏对科学信息上下文的理解,导致抽取出的信息碎片化,甚至出现冲突。因此,需要一种能够处理多领域科学文本,并能有效抽取事件及其上下文信息的方法。
核心思路:本文的核心思路是将科学信息抽取任务定义为一个多阶段的事件抽取流程,并构建一个多领域的数据集来训练和评估模型。通过统一的事件抽取模式,将科学摘要分解为核心科学活动(背景、方法、结果、结论),并提取相应的触发词和论元,从而实现对科学内容的结构化理解。
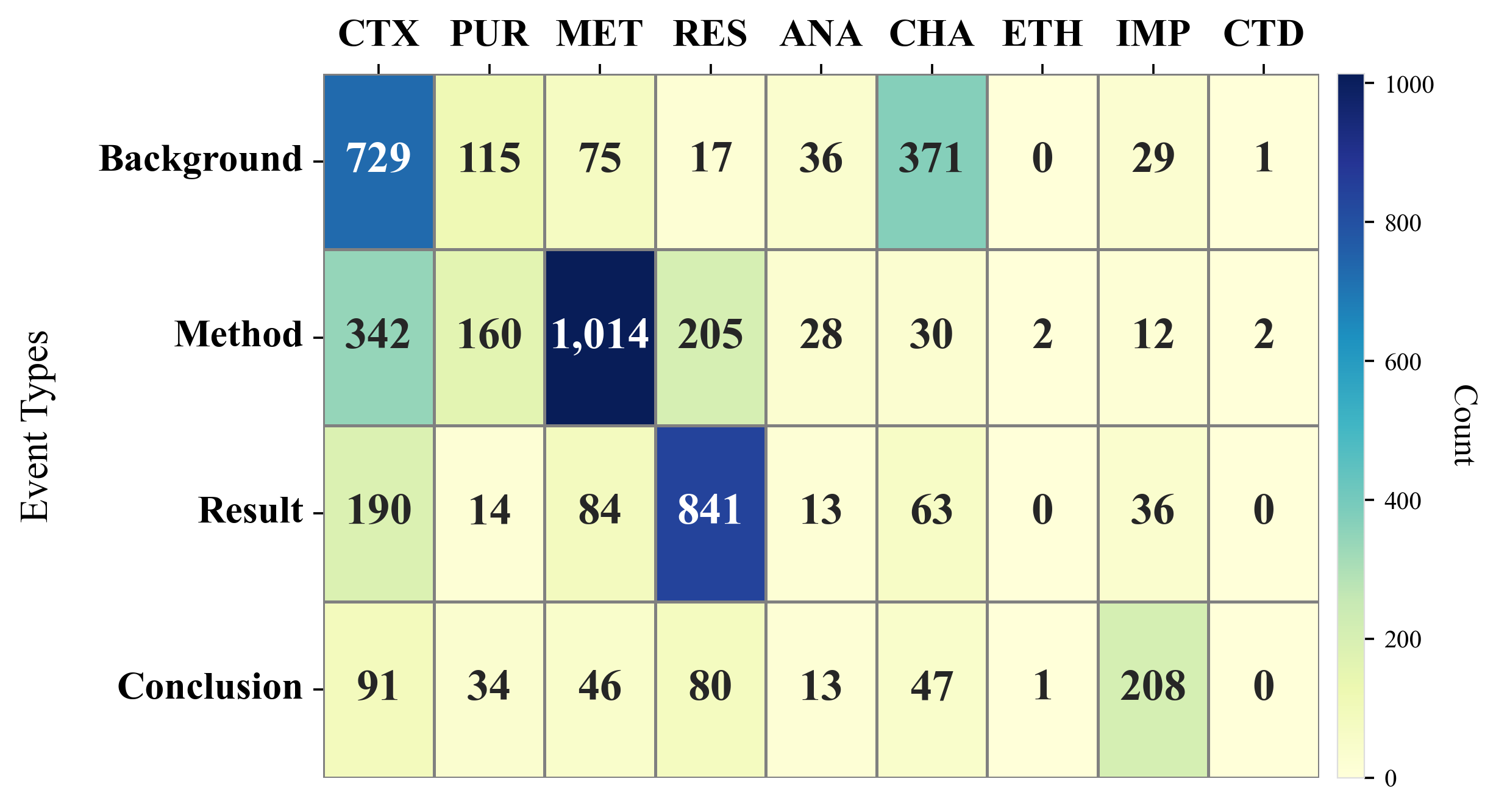
技术框架:SciEvent的整体框架包含以下两个主要阶段: 1. 摘要分割:将科学摘要分割成四个核心部分:背景(Background)、方法(Method)、结果(Result)和结论(Conclusion)。 2. 事件抽取:在分割后的每个部分中,提取事件的触发词(trigger)和论元(argument)。 整个流程旨在将非结构化的科学文本转化为结构化的事件表示,从而方便后续的分析和利用。
关键创新:SciEvent的关键创新在于: 1. 多领域数据集:构建了一个包含五个不同研究领域(计算机科学、材料科学、化学、社会学和人文学科)的科学摘要数据集,从而提高了模型的泛化能力。 2. 统一事件抽取模式:定义了一个统一的事件抽取模式,可以应用于不同领域的科学文本,从而实现了跨领域的知识表示和推理。 3. 多阶段事件抽取流程:将科学信息抽取任务分解为摘要分割和事件抽取两个阶段,从而降低了任务的复杂度,并提高了抽取精度。
关键设计:SciEvent的关键设计包括: 1. 数据集构建:人工标注了500篇科学摘要,包括事件片段、触发词和细粒度论元。 2. 评估指标:采用了标准的事件抽取评估指标,如精确率(Precision)、召回率(Recall)和F1值(F1-score),来评估模型的性能。 3. 基线模型:使用了微调的事件抽取模型和大型语言模型(LLMs)作为基线模型,并与人工标注者的性能进行了比较。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有模型在SciEvent数据集上的性能与人工标注者之间存在显著差距,尤其是在社会学和人文学科等领域。这表明当前模型在处理多领域科学文本和理解复杂上下文方面仍有不足。SciEvent作为一个具有挑战性的基准,可以促进更有效的科学信息抽取模型的研究和开发。
🎯 应用场景
SciEvent的研究成果可应用于多个领域,例如:智能科研助手,帮助研究人员快速理解文献内容;知识图谱构建,将科学知识以结构化的形式存储和管理;自动文献综述,自动生成特定主题的文献综述报告。该研究有助于提升科研效率,促进跨学科交流,加速科学发现。
📄 摘要(原文)
Scientific information extraction (SciIE) has primarily relied on entity-relation extraction in narrow domains, limiting its applicability to interdisciplinary research and struggling to capture the necessary context of scientific information, often resulting in fragmented or conflicting statements. In this paper, we introduce SciEvent, a novel multi-domain benchmark of scientific abstracts annotated via a unified event extraction (EE) schema designed to enable structured and context-aware understanding of scientific content. It includes 500 abstracts across five research domains, with manual annotations of event segments, triggers, and fine-grained arguments. We define SciIE as a multi-stage EE pipeline: (1) segmenting abstracts into core scientific activities--Background, Method, Result, and Conclusion; and (2) extracting the corresponding triggers and arguments. Experiments with fine-tuned EE models, large language models (LLMs), and human annotators reveal a performance gap, with current models struggling in domains such as sociology and humanities. SciEvent serves as a challenging benchmark and a step toward generalizable, multi-domain SciIE.