DivLogicEval: A Framework for Benchmarking Logical Reasoning Evaluation in Large Language Models
作者: Tsz Ting Chung, Lemao Liu, Mo Yu, Dit-Yan Yeung
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-19 (更新: 2025-09-26)
备注: Accepted by EMNLP 2025. Project Page: https://ttchungc.github.io/projects/divlogiceval/
💡 一句话要点
DivLogicEval:用于评估大语言模型逻辑推理能力的新基准框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 逻辑推理 基准测试 自然语言处理 模型评估
📋 核心要点
- 现有逻辑推理基准测试存在语言多样性不足和分布偏差问题,导致对大语言模型的逻辑推理能力评估不准确。
- 论文提出DivLogicEval基准,包含多样化陈述的自然语句,并设计新的评估指标以减少偏差和随机性的影响。
- 实验表明,DivLogicEval能有效评估大语言模型的逻辑推理能力,并对比了不同LLM在该基准上的表现。
📝 摘要(中文)
本文提出了一种新的经典逻辑基准DivLogicEval,用于评估大语言模型(LLMs)的逻辑推理能力。现有基准可能混淆多种推理技能,从而对逻辑推理技能的评估不准确。此外,现有的逻辑推理基准在语言多样性方面存在局限性,并且它们的分布偏离了理想逻辑推理基准的分布,这可能导致有偏差的评估结果。DivLogicEval由以违反直觉的方式组成的自然语句构成,这些语句具有多样化的陈述。为了确保更可靠的评估,本文还引入了一种新的评估指标,以减轻LLM中固有的偏差和随机性的影响。实验结果表明,回答DivLogicEval中的问题需要一定程度的逻辑推理,并比较了不同流行LLM在进行逻辑推理方面的性能。
🔬 方法详解
问题定义:现有的大语言模型逻辑推理能力评估基准存在两个主要问题:一是混杂了多种推理技能,无法准确评估纯粹的逻辑推理能力;二是语言多样性不足,分布与理想的逻辑推理基准存在偏差,导致评估结果存在偏见。因此,需要一个更纯粹、更具代表性的逻辑推理评估基准。
核心思路:论文的核心思路是构建一个包含多样化陈述的自然语言数据集,这些陈述以违反直觉的方式组合,从而更有效地考察模型的逻辑推理能力。同时,设计一种新的评估指标,以减轻模型固有的偏差和随机性对评估结果的影响。
技术框架:DivLogicEval框架主要包含两个部分:数据集构建和评估指标设计。数据集构建方面,收集并组合自然语言语句,确保语句的多样性和违反直觉的特性。评估指标方面,设计一种新的指标,用于衡量模型在逻辑推理任务上的准确性,并减轻偏差和随机性的影响。整体流程是:给定一个逻辑推理问题,模型生成答案,然后使用新的评估指标评估答案的质量。
关键创新:该论文的关键创新在于:1) 提出了一个新的逻辑推理基准DivLogicEval,该基准更纯粹、更具代表性,能够更准确地评估大语言模型的逻辑推理能力。2) 设计了一种新的评估指标,能够减轻模型固有的偏差和随机性对评估结果的影响,从而提高评估的可靠性。与现有方法相比,DivLogicEval更注重逻辑推理的纯粹性,并采用更稳健的评估方法。
关键设计:数据集构建的关键设计在于语句的多样性和违反直觉的组合方式。具体来说,论文可能采用了某种策略来选择和组合语句,以确保数据集的难度和区分度。评估指标的关键设计在于如何量化模型的逻辑推理能力,并减轻偏差和随机性的影响。具体的参数设置、损失函数和网络结构等技术细节在摘要中未提及,属于未知信息。
🖼️ 关键图片

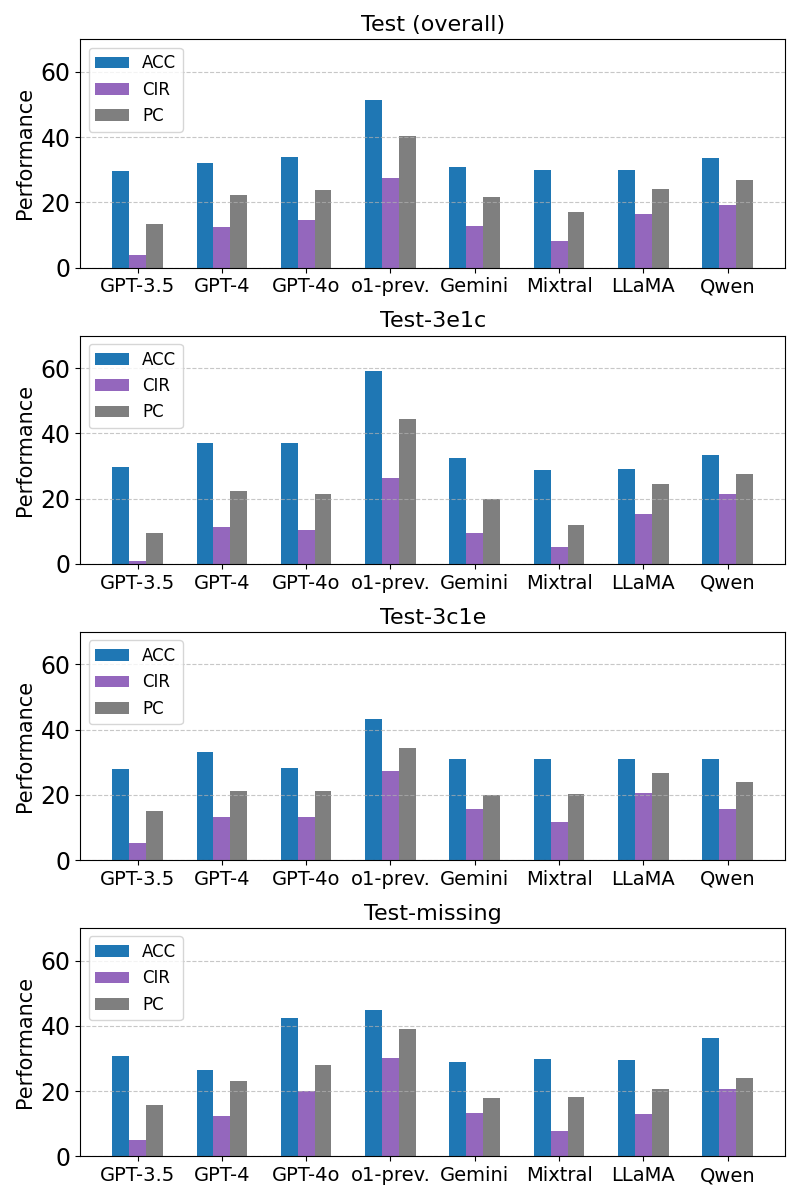
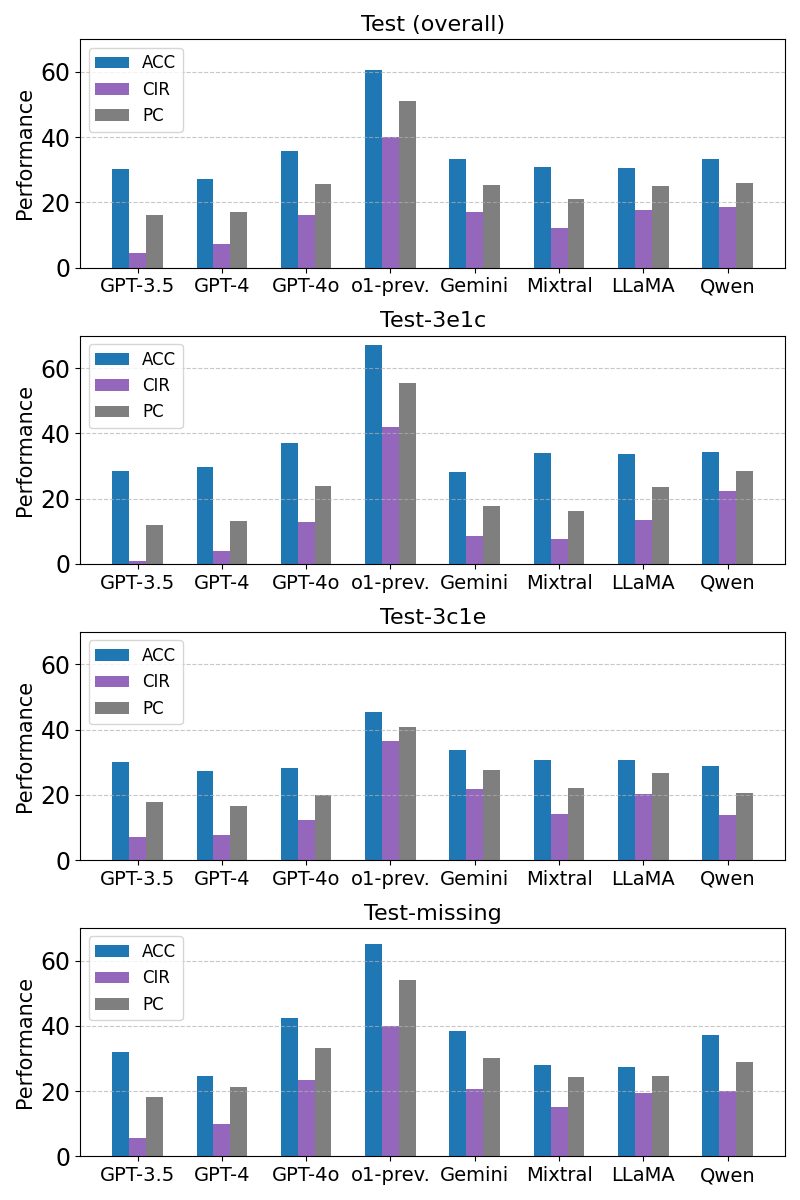
📊 实验亮点
论文提出了DivLogicEval基准,并设计了新的评估指标。实验结果表明,该基准能够有效评估大语言模型的逻辑推理能力,并对比了不同LLM在该基准上的表现。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于大语言模型的评测与改进,帮助研究人员更准确地了解模型的逻辑推理能力,并针对性地进行优化。此外,该基准和评估方法也可用于其他需要逻辑推理能力的AI系统的开发和评估,例如智能问答系统、知识图谱推理等。
📄 摘要(原文)
Logic reasoning in natural language has been recognized as an important measure of human intelligence for Large Language Models (LLMs). Popular benchmarks may entangle multiple reasoning skills and thus provide unfaithful evaluations on the logic reasoning skill. Meanwhile, existing logic reasoning benchmarks are limited in language diversity and their distributions are deviated from the distribution of an ideal logic reasoning benchmark, which may lead to biased evaluation results. This paper thereby proposes a new classical logic benchmark DivLogicEval, consisting of natural sentences composed of diverse statements in a counterintuitive way. To ensure a more reliable evaluation, we also introduce a new evaluation metric that mitigates the influence of bias and randomness inherent in LLMs. Through experiments, we demonstrate the extent to which logical reasoning is required to answer the questions in DivLogicEval and compare the performance of different popular LLMs in conducting logical reasoning.