LiteLong: Resource-Efficient Long-Context Data Synthesis for LLMs
作者: Junlong Jia, Xing Wu, Chaochen Gao, Ziyang Chen, Zijia Lin, Zhongzhi Li, Weinong Wang, Haotian Xu, Donghui Jin, Debing Zhang, Binghui Guo
分类: cs.CL, cs.AI
发布日期: 2025-09-19
备注: work in progress
💡 一句话要点
LiteLong:一种资源高效的长文本数据合成方法,用于训练大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本数据合成 大型语言模型 多智能体辩论 主题组织 资源高效
📋 核心要点
- 现有长文本数据合成方法计算效率低,难以满足大型语言模型训练的需求。
- LiteLong通过结构化主题组织和多智能体辩论,高效生成高质量长文本数据。
- 实验表明,LiteLong在长文本基准测试中表现出色,并能与其他方法集成。
📝 摘要(中文)
高质量的长文本数据对于训练能够处理大量文档的大型语言模型至关重要。然而,现有的基于相关性聚合的合成方法面临计算效率的挑战。我们提出了LiteLong,一种资源高效的方法,通过结构化的主题组织和多智能体辩论来合成长文本数据。我们的方法利用BISAC图书分类系统提供全面的分层主题组织,然后采用多LLM辩论机制,在该结构内生成多样化、高质量的主题。对于每个主题,我们使用轻量级的BM25检索来获取相关文档,并将它们连接成128K token的训练样本。在HELMET和Ruler基准测试上的实验表明,LiteLong实现了具有竞争力的长文本性能,并且可以与其他长依赖增强方法无缝集成。LiteLong通过降低计算和数据工程成本,使高质量的长文本数据合成更易于访问,从而促进了长文本语言训练的进一步研究。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)训练中,高质量长文本数据合成的计算效率问题。现有的基于相关性聚合的方法,例如直接拼接相关文档,计算成本高昂,难以生成多样化和结构化的长文本数据,限制了LLMs在长文本理解和生成方面的能力。
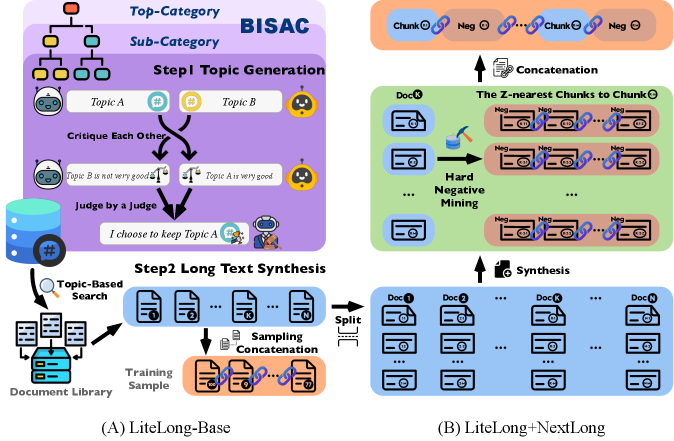
核心思路:LiteLong的核心思路是通过结构化的主题组织和多智能体辩论来高效地生成高质量的长文本数据。首先,利用BISAC图书分类系统构建分层主题结构,确保主题的覆盖度和组织性。然后,采用多LLM辩论机制,在每个主题下生成多样化的子主题,增加数据的丰富性。最后,使用轻量级的BM25检索相关文档,降低计算成本。
技术框架:LiteLong的整体框架包括以下几个主要阶段:1) 主题组织:利用BISAC图书分类系统构建分层主题结构。2) 主题生成:使用多LLM辩论机制,在每个主题下生成多样化的子主题。3) 文档检索:使用BM25算法检索与子主题相关的文档。4) 数据合成:将检索到的文档拼接成128K token的训练样本。
关键创新:LiteLong的关键创新在于:1) 结构化主题组织:利用BISAC图书分类系统,提供了一种全面的分层主题组织方式,避免了随机或无序的主题生成。2) 多智能体辩论:采用多LLM辩论机制,生成多样化、高质量的主题,提高了数据的丰富性和质量。3) 资源高效的检索:使用轻量级的BM25检索,降低了计算成本,使得长文本数据合成更加高效。与现有方法相比,LiteLong在保证数据质量的同时,显著降低了计算资源的需求。
关键设计:在主题生成阶段,使用了多个LLM进行辩论,每个LLM扮演不同的角色,例如提问者、回答者、评论者等,通过多轮对话来生成更全面、更深入的主题。在文档检索阶段,使用了BM25算法,并设置了合适的检索阈值,以保证检索到的文档与主题的相关性。最终合成的训练样本长度为128K token,这是一个经过实验验证的,能够有效训练LLM长文本处理能力的长度。
🖼️ 关键图片


📊 实验亮点
LiteLong在HELMET和Ruler基准测试中取得了具有竞争力的长文本性能。实验结果表明,LiteLong能够有效地提高LLM在长文本理解和生成方面的能力。此外,LiteLong可以与其他长依赖增强方法无缝集成,进一步提升性能。该方法显著降低了长文本数据合成的计算成本,使得高质量长文本数据合成更加易于访问。
🎯 应用场景
LiteLong可以应用于各种需要长文本处理能力的领域,例如:长文档摘要、信息检索、问答系统、机器翻译、小说创作等。该方法降低了长文本数据合成的成本,使得更多研究者和开发者能够训练出更强大的长文本LLM,从而推动相关领域的发展。未来,LiteLong可以进一步扩展到其他类型的数据,例如代码、音频、视频等,以支持更多模态的长文本处理。
📄 摘要(原文)
High-quality long-context data is essential for training large language models (LLMs) capable of processing extensive documents, yet existing synthesis approaches using relevance-based aggregation face challenges of computational efficiency. We present LiteLong, a resource-efficient method for synthesizing long-context data through structured topic organization and multi-agent debate. Our approach leverages the BISAC book classification system to provide a comprehensive hierarchical topic organization, and then employs a debate mechanism with multiple LLMs to generate diverse, high-quality topics within this structure. For each topic, we use lightweight BM25 retrieval to obtain relevant documents and concatenate them into 128K-token training samples. Experiments on HELMET and Ruler benchmarks demonstrate that LiteLong achieves competitive long-context performance and can seamlessly integrate with other long-dependency enhancement methods. LiteLong makes high-quality long-context data synthesis more accessible by reducing both computational and data engineering costs, facilitating further research in long-context language training.