Exploring Polyglot Harmony: On Multilingual Data Allocation for Large Language Models Pretraining
作者: Ping Guo, Yubing Ren, Binbin Liu, Fengze Liu, Haobin Lin, Yifan Zhang, Bingni Zhang, Taifeng Wang, Yin Zheng
分类: cs.CL, cs.AI
发布日期: 2025-09-19
💡 一句话要点
Climb:一种跨语言交互感知的大语言模型多语种数据分配优化框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语种学习 大语言模型 数据分配 跨语言交互 预训练 语言比例优化
📋 核心要点
- 现有大语言模型多语种训练中,语言比例分配缺乏有效策略,难以充分利用跨语言交互。
- Climb框架通过量化跨语言交互,优化语言比例分配,从而提升多语种大语言模型性能。
- 实验表明,Climb能准确衡量跨语言交互,并使模型在多语种任务上达到SOTA,甚至超越更大规模模型。
📝 摘要(中文)
大型语言模型(LLMs)已成为全球范围内各种应用不可或缺的一部分,推动了对有效多语种能力的空前需求。实现强大的多语种性能的关键在于训练语料库中语言比例的战略分配。然而,由于复杂的跨语言交互和对数据集规模的敏感性,确定最佳语言比例极具挑战性。本文介绍了一种名为Climb(跨语言交互感知多语种平衡)的新框架,旨在系统地优化多语种数据分配。Climb的核心是引入了一种跨语言交互感知的语言比例,通过捕捉语言间的依赖关系来显式量化每种语言的有效分配。利用这一比例,Climb提出了一种原则性的两步优化程序——首先均衡各语言的边际收益,然后最大化所得语言分配向量的大小——从而显著简化了固有多语种优化问题。大量实验证实,Climb可以准确衡量各种多语种环境下的跨语言交互。使用Climb导出的比例训练的LLM始终如一地实现了最先进的多语种性能,甚至实现了与使用更多tokens训练的开源LLM相媲美的性能。
🔬 方法详解
问题定义:现有的大语言模型在进行多语种预训练时,如何确定不同语言数据之间的最佳比例是一个关键问题。简单地按照某种固定的比例(例如,按照各语言的互联网数据量比例)进行分配,无法充分利用不同语言之间的知识迁移和互补关系。现有的方法缺乏对跨语言交互的有效建模,导致训练效率低下,模型性能受限。
核心思路:Climb框架的核心思路是显式地建模和量化不同语言之间的交互关系,并基于此来优化语言数据的分配比例。它认为,每种语言的“有效分配”不仅取决于其自身的比例,还取决于其与其他语言的交互强度。通过最大化所有语言的有效分配,可以提升模型的整体多语种能力。
技术框架:Climb框架包含两个主要步骤:1) 跨语言交互感知的语言比例计算:首先,通过某种方式(例如,基于模型的困惑度或互信息)来估计不同语言之间的交互强度。然后,基于这些交互强度,计算每种语言的“有效分配”比例。2) 两步优化:首先,均衡各语言的边际收益,即确保每种语言对模型性能的提升潜力大致相同。然后,最大化所得语言分配向量的大小,即尽可能地利用所有语言的数据。
关键创新:Climb框架的关键创新在于提出了“跨语言交互感知的语言比例”这一概念,并将其应用于多语种数据分配的优化中。与现有方法相比,Climb能够更准确地衡量不同语言对模型性能的贡献,从而实现更有效的训练。
关键设计:Climb框架的具体实现细节可能因不同的应用场景而异。例如,可以使用不同的方法来估计语言之间的交互强度,可以使用不同的优化算法来求解最佳的语言分配比例。论文中可能还涉及一些超参数的设置,例如,用于控制边际收益均衡程度的参数,以及用于控制分配向量大小的参数。
🖼️ 关键图片

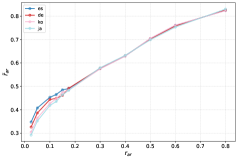
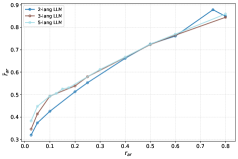
📊 实验亮点
实验结果表明,使用Climb框架训练的LLM在多语种任务上取得了显著的性能提升,达到了state-of-the-art水平。更重要的是,Climb框架训练的模型甚至可以与使用更多tokens训练的开源LLM相媲美,这表明Climb框架能够更有效地利用数据,提高训练效率。
🎯 应用场景
该研究成果可广泛应用于多语种大语言模型的预训练,提升模型在跨语言理解、翻译、生成等任务上的性能。通过优化数据分配,可以降低训练成本,提高模型效率,并促进多语种人工智能技术的普及和应用。未来,该方法有望扩展到更多语言和更大规模的模型。
📄 摘要(原文)
Large language models (LLMs) have become integral to a wide range of applications worldwide, driving an unprecedented global demand for effective multilingual capabilities. Central to achieving robust multilingual performance is the strategic allocation of language proportions within training corpora. However, determining optimal language ratios is highly challenging due to intricate cross-lingual interactions and sensitivity to dataset scale. This paper introduces Climb (Cross-Lingual Interaction-aware Multilingual Balancing), a novel framework designed to systematically optimize multilingual data allocation. At its core, Climb introduces a cross-lingual interaction-aware language ratio, explicitly quantifying each language's effective allocation by capturing inter-language dependencies. Leveraging this ratio, Climb proposes a principled two-step optimization procedure--first equalizing marginal benefits across languages, then maximizing the magnitude of the resulting language allocation vectors--significantly simplifying the inherently complex multilingual optimization problem. Extensive experiments confirm that Climb can accurately measure cross-lingual interactions across various multilingual settings. LLMs trained with Climb-derived proportions consistently achieve state-of-the-art multilingual performance, even achieving competitive performance with open-sourced LLMs trained with more tokens.