LLM-Assisted Topic Reduction for BERTopic on Social Media Data
作者: Wannes Janssens, Matthias Bogaert, Dirk Van den Poel
分类: cs.CL, cs.LG
发布日期: 2025-09-18
备注: 13 pages, 8 figures. To be published in the Post-Workshop proceedings of the ECML PKDD 2025 Conference
💡 一句话要点
提出LLM辅助的BERTopic主题降维方法,提升社交媒体数据主题建模效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: BERTopic 主题建模 大型语言模型 主题降维 社交媒体分析
📋 核心要点
- 社交媒体数据噪声大、稀疏,导致BERTopic主题建模产生大量重叠主题,影响效果。
- 利用大型语言模型进行主题降维,合并语义相似的主题,提升主题多样性和一致性。
- 实验表明,该方法在Twitter/X数据集上优于基线方法,但性能受数据集和参数影响。
📝 摘要(中文)
BERTopic框架利用Transformer嵌入和层次聚类从非结构化文本语料库中提取潜在主题。然而,它在处理社交媒体数据时面临挑战,因为社交媒体数据通常噪声大且稀疏,导致产生大量重叠主题。最近的研究探索了使用大型语言模型进行端到端主题建模,但这些方法通常需要大量的计算开销,限制了其在大数据环境中的可扩展性。本文提出了一种结合BERTopic进行主题生成和大型语言模型进行主题降维的框架。该方法首先生成一组初始主题,并构建每个主题的表示。然后,将这些表示作为输入提供给语言模型,语言模型迭代地识别和合并语义相似的主题。我们在三个Twitter/X数据集和四个不同的语言模型上评估了该方法。结果表明,我们的方法在提高主题多样性方面优于基线方法,并且在许多情况下也提高了主题一致性,但对数据集特征和初始参数选择具有一定的敏感性。
🔬 方法详解
问题定义:BERTopic在处理社交媒体数据时,由于数据本身的噪声和稀疏性,容易产生大量语义重叠的主题,导致主题区分度不高,难以有效提取有意义的信息。现有的大型语言模型端到端主题建模方法计算开销大,难以应用于大规模社交媒体数据。
核心思路:论文的核心思路是将BERTopic和大型语言模型结合起来,利用BERTopic快速生成初始主题,然后利用大型语言模型的语义理解能力对这些主题进行降维,合并相似的主题,从而提高主题的多样性和一致性。这种方法旨在在计算效率和主题质量之间取得平衡。
技术框架:该框架包含两个主要阶段:1) 主题生成阶段:使用BERTopic从文本数据中提取初始主题。BERTopic利用Transformer模型生成文档嵌入,然后使用层次聚类算法对文档嵌入进行聚类,每个簇代表一个主题。2) 主题降维阶段:使用大型语言模型对初始主题进行降维。首先,为每个主题构建表示(例如,使用主题中的关键词或文档嵌入的平均值)。然后,将这些主题表示输入到大型语言模型中,语言模型迭代地识别和合并语义相似的主题。
关键创新:该方法的关键创新在于将BERTopic和大型语言模型结合起来,利用BERTopic快速生成初始主题,然后利用大型语言模型的语义理解能力对这些主题进行降维。这种混合方法旨在克服BERTopic在处理噪声数据时的局限性,并降低大型语言模型端到端主题建模的计算成本。
关键设计:主题表示的构建方式(例如,使用主题关键词的嵌入或文档嵌入的平均值)以及大型语言模型合并主题的策略(例如,基于语义相似度阈值)是关键的设计选择。论文中使用了不同的语言模型,并评估了它们在不同数据集上的性能。此外,初始BERTopic的参数设置,例如主题数量,也会影响最终结果。
🖼️ 关键图片

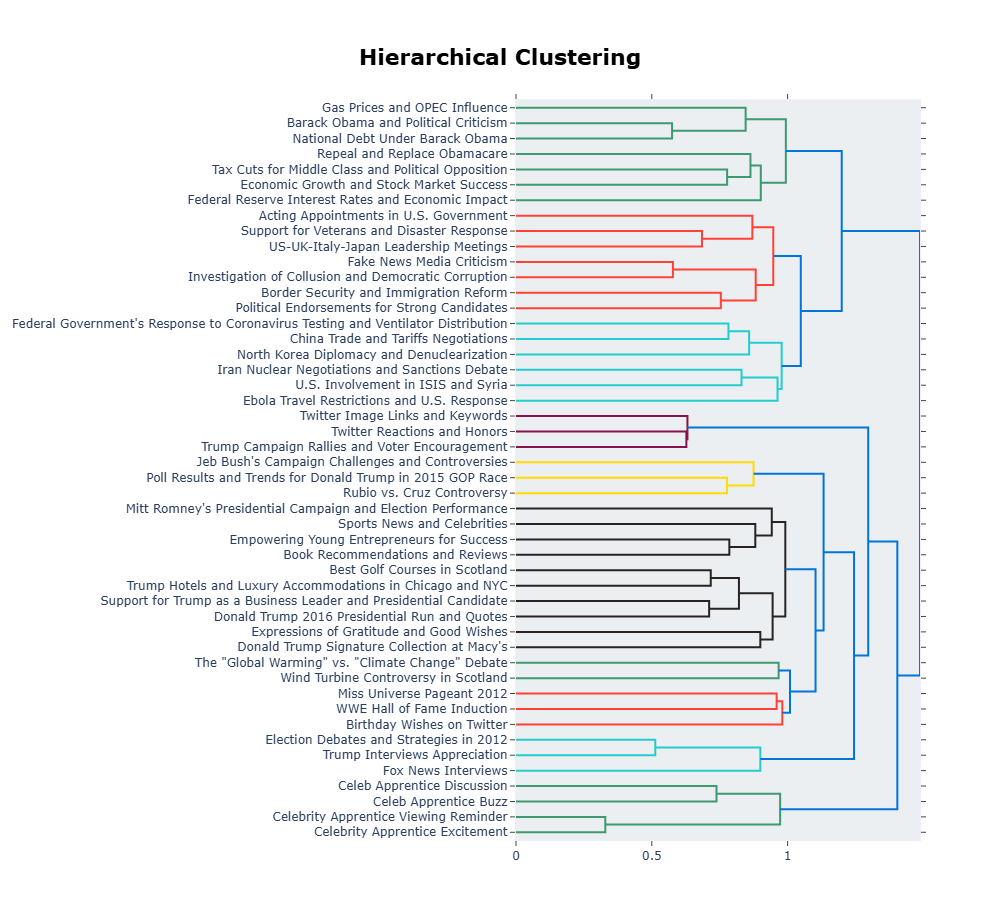
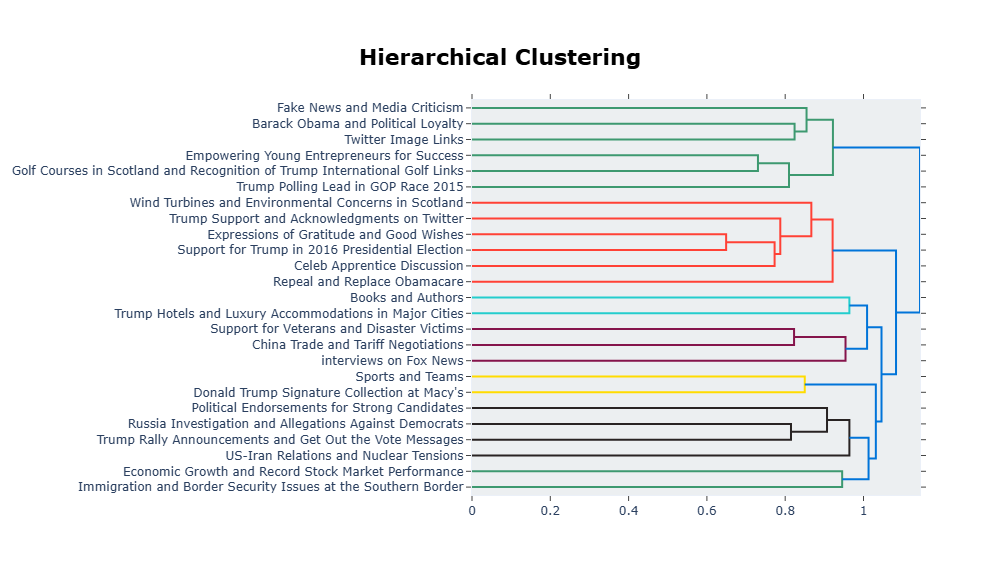
📊 实验亮点
实验结果表明,该方法在三个Twitter/X数据集上,使用不同的语言模型,均能有效提高主题多样性,并在许多情况下提高主题一致性。相较于基线BERTopic方法,该方法能够生成更具区分度和可解释性的主题。但实验结果也显示,该方法的性能对数据集特征和初始参数选择具有一定的敏感性。
🎯 应用场景
该研究成果可应用于社交媒体舆情分析、用户兴趣挖掘、个性化推荐等领域。通过更准确地提取社交媒体数据中的主题,可以更好地理解用户行为和趋势,为企业决策提供支持,并提升用户体验。未来,该方法可以扩展到其他类型的文本数据,例如新闻文章、客户评论等。
📄 摘要(原文)
The BERTopic framework leverages transformer embeddings and hierarchical clustering to extract latent topics from unstructured text corpora. While effective, it often struggles with social media data, which tends to be noisy and sparse, resulting in an excessive number of overlapping topics. Recent work explored the use of large language models for end-to-end topic modelling. However, these approaches typically require significant computational overhead, limiting their scalability in big data contexts. In this work, we propose a framework that combines BERTopic for topic generation with large language models for topic reduction. The method first generates an initial set of topics and constructs a representation for each. These representations are then provided as input to the language model, which iteratively identifies and merges semantically similar topics. We evaluate the approach across three Twitter/X datasets and four different language models. Our method outperforms the baseline approach in enhancing topic diversity and, in many cases, coherence, with some sensitivity to dataset characteristics and initial parameter selection.