Beyond Spurious Signals: Debiasing Multimodal Large Language Models via Counterfactual Inference and Adaptive Expert Routing
作者: Zichen Wu, Hsiu-Yuan Huang, Yunfang Wu
分类: cs.CL, cs.AI, cs.MM
发布日期: 2025-09-18
备注: Accepted by EMNLP 2025 Findings
💡 一句话要点
提出基于因果推断和自适应专家路由的多模态大语言模型去偏框架,提升复杂推理任务的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 因果推断 反事实推理 去偏 混合专家 鲁棒性 泛化能力
📋 核心要点
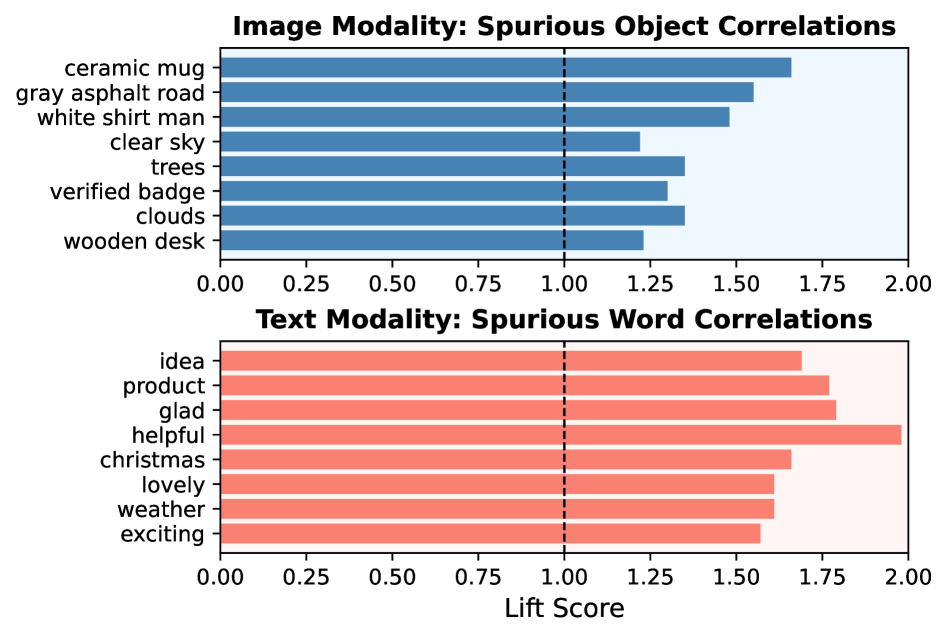
- 多模态大语言模型易受虚假相关性影响,导致在复杂推理任务中表现不佳,泛化能力受限。
- 论文提出基于因果中介的去偏框架,利用反事实示例区分核心语义和虚假上下文,并采用混合专家架构进行模态特定去偏。
- 实验结果表明,该框架在多模态讽刺检测和情感分析任务上显著优于现有方法,提升了模型的鲁棒性。
📝 摘要(中文)
多模态大语言模型(MLLMs)在整合视觉和文本信息方面表现出强大的能力,但常常依赖于虚假相关性,这损害了它们在复杂多模态推理任务中的鲁棒性和泛化能力。本文通过一种新颖的基于因果中介的去偏框架,解决了MLLMs中表面相关性偏差的关键挑战。具体而言,我们通过反事实示例区分核心语义与虚假的文本和视觉上下文,以激活训练阶段的去偏,并采用具有动态路由的混合专家(MoE)架构,以选择性地启用特定模态的去偏专家。在多模态讽刺检测和情感分析任务上的实证评估表明,我们的框架显著优于单模态去偏策略和现有的最先进模型。
🔬 方法详解
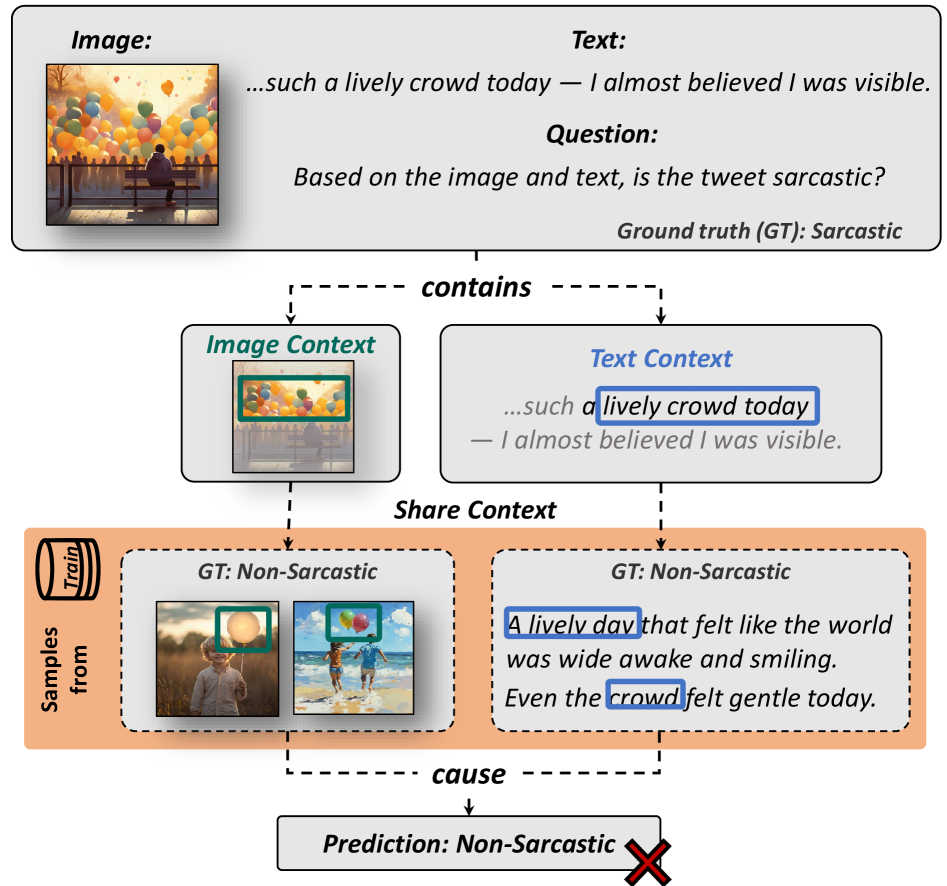
问题定义:多模态大语言模型(MLLMs)在处理多模态数据时,容易受到数据中存在的虚假相关性的影响。例如,模型可能会将图像中的特定背景与某种情感直接关联,而不是真正理解图像和文本的语义关系。这种虚假相关性会导致模型在面对新的、未见过的数据时表现不佳,泛化能力不足。现有方法通常采用单模态的去偏策略,无法有效地解决多模态数据中复杂的偏差问题。
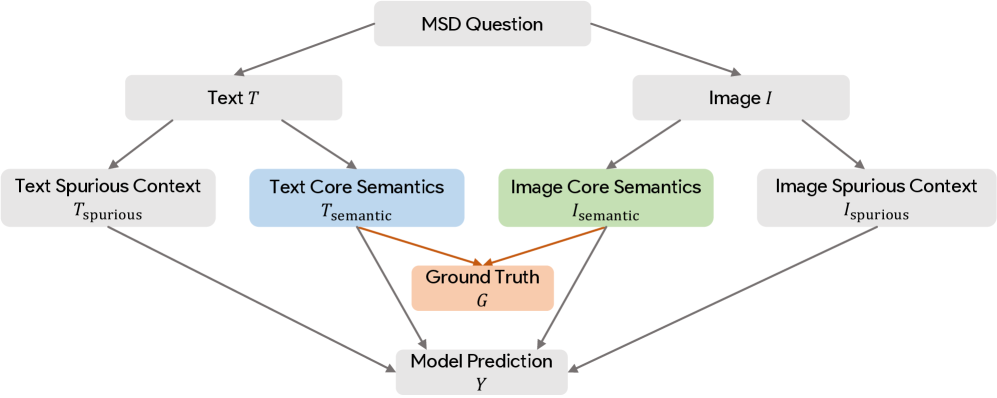
核心思路:本文的核心思路是通过因果推断来识别和消除MLLMs中的虚假相关性。具体来说,论文利用反事实推理来区分核心语义和虚假的文本及视觉上下文。通过生成反事实示例,模型可以学习到哪些特征是真正重要的,哪些是虚假的。此外,论文还引入了混合专家(MoE)架构,允许模型根据不同的模态选择性地启用不同的去偏专家,从而实现更精细的去偏。
技术框架:该框架主要包含两个阶段:训练阶段的去偏和推理阶段的自适应专家路由。在训练阶段,首先利用反事实示例来训练去偏专家,这些专家专门用于消除特定模态中的虚假相关性。然后,在推理阶段,模型使用动态路由机制来选择性地启用这些去偏专家。整体架构包括一个多模态编码器,用于提取视觉和文本特征;一个反事实生成模块,用于生成反事实示例;一组模态特定的去偏专家;以及一个动态路由模块,用于选择合适的专家。
关键创新:该论文最重要的技术创新点在于将因果推断和混合专家架构结合起来,用于多模态大语言模型的去偏。与传统的单模态去偏方法相比,该方法能够更有效地识别和消除多模态数据中复杂的虚假相关性。此外,动态路由机制允许模型根据不同的输入自适应地选择合适的去偏专家,从而提高了模型的灵活性和鲁棒性。
关键设计:反事实示例的生成是关键设计之一,论文采用了一种基于梯度的方法来生成反事实图像和文本。动态路由模块使用一个门控网络来计算每个专家的权重,该门控网络的输入是多模态编码器的输出。损失函数包括一个交叉熵损失,用于训练主模型;一个对比损失,用于训练去偏专家;以及一个正则化项,用于防止过拟合。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架在多模态讽刺检测和情感分析任务上取得了显著的性能提升。例如,在多模态讽刺检测任务上,该方法比最先进的模型提高了5%的准确率。此外,消融实验验证了反事实推理和自适应专家路由的有效性,证明了该框架的各个组成部分都对最终性能做出了贡献。
🎯 应用场景
该研究成果可广泛应用于需要鲁棒性和泛化能力的多模态任务中,例如自动驾驶、医疗诊断、智能客服等。通过消除模型对虚假相关性的依赖,可以提高模型在复杂环境下的可靠性和准确性,从而提升用户体验和决策质量。未来,该方法还可以扩展到其他多模态领域,例如视频理解、语音识别等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have shown substantial capabilities in integrating visual and textual information, yet frequently rely on spurious correlations, undermining their robustness and generalization in complex multimodal reasoning tasks. This paper addresses the critical challenge of superficial correlation bias in MLLMs through a novel causal mediation-based debiasing framework. Specially, we distinguishing core semantics from spurious textual and visual contexts via counterfactual examples to activate training-stage debiasing and employ a Mixture-of-Experts (MoE) architecture with dynamic routing to selectively engages modality-specific debiasing experts. Empirical evaluation on multimodal sarcasm detection and sentiment analysis tasks demonstrates that our framework significantly surpasses unimodal debiasing strategies and existing state-of-the-art models.