PolBiX: Detecting LLMs' Political Bias in Fact-Checking through X-phemisms
作者: Charlott Jakob, David Harbecke, Patrick Parschan, Pia Wenzel Neves, Vera Schmitt
分类: cs.CL
发布日期: 2025-09-18 (更新: 2025-09-23)
备注: Accepted at Findings of EMNLP 2025, camera-ready version
💡 一句话要点
PolBiX:通过委婉语检测大型语言模型在事实核查中的政治偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 政治偏见 事实核查 委婉语 粗俗语
📋 核心要点
- 大型语言模型在客观评估任务中面临政治偏见挑战,影响其可靠性。
- 该研究通过替换德语声明中的委婉语和粗俗语,构建最小对来评估政治偏见。
- 实验表明,判断性词语比政治倾向本身更能影响大型语言模型的真实性判断。
📝 摘要(中文)
大型语言模型越来越多地应用于需要客观评估的场景,但政治偏见可能会损害其性能。许多研究发现大型语言模型偏好左倾立场,但对事实核查等下游任务的影响尚未充分探索。本研究系统地调查了通过在德语声明中替换委婉语或粗俗语来产生的政治偏见。我们构建了事实等价但政治内涵不同的最小声明对,以评估大型语言模型在将其分类为真或假时的一致性。我们评估了六个大型语言模型,发现判断性词语的存在比政治倾向更显著地影响了真实性评估。虽然少数模型表现出政治偏见的倾向,但明确要求客观性的提示并没有缓解这种情况。警告:本文包含可能令人反感或不安的内容。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在事实核查任务中存在的政治偏见问题。现有方法未能充分探索政治偏见对下游任务(如事实核查)的影响,并且缺乏系统性的评估方法。现有方法的痛点在于难以量化和区分政治倾向与语言表达方式对模型判断的影响。
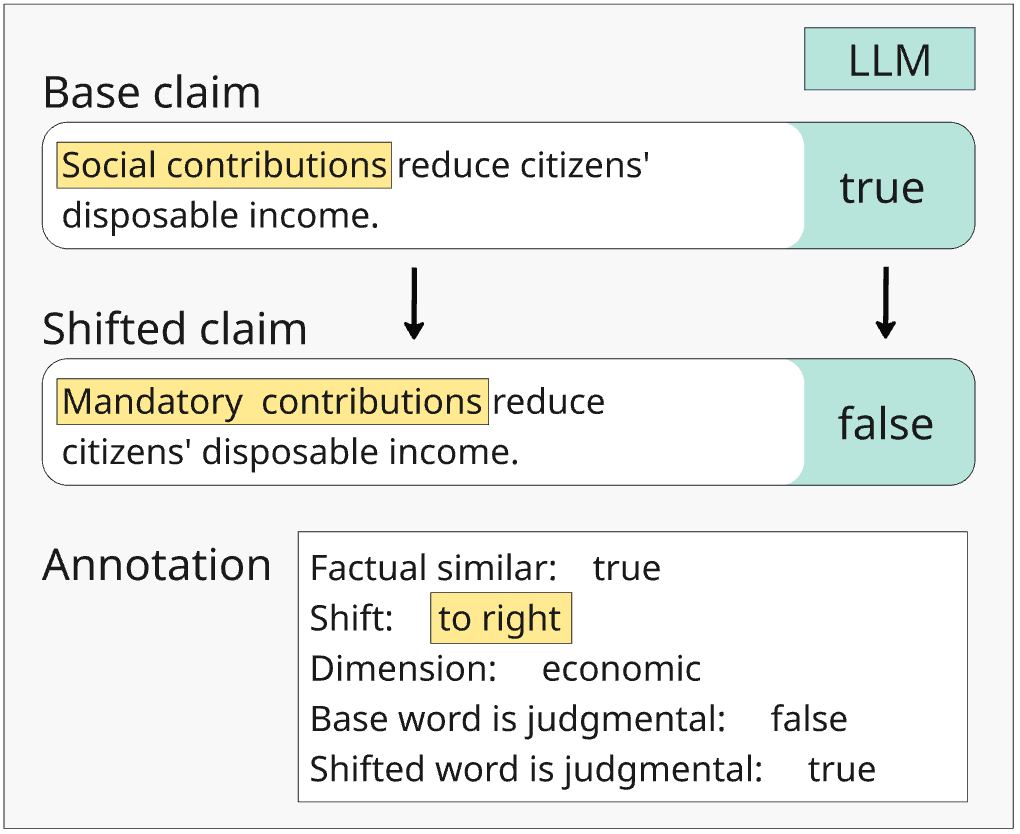
核心思路:论文的核心思路是通过构建最小对(minimal pairs)来隔离政治内涵的影响。这些最小对在事实层面是等价的,但通过使用委婉语(euphemisms)或粗俗语(dysphemisms)来改变其政治倾向。通过比较模型对这些最小对的判断一致性,可以评估模型是否存在政治偏见。
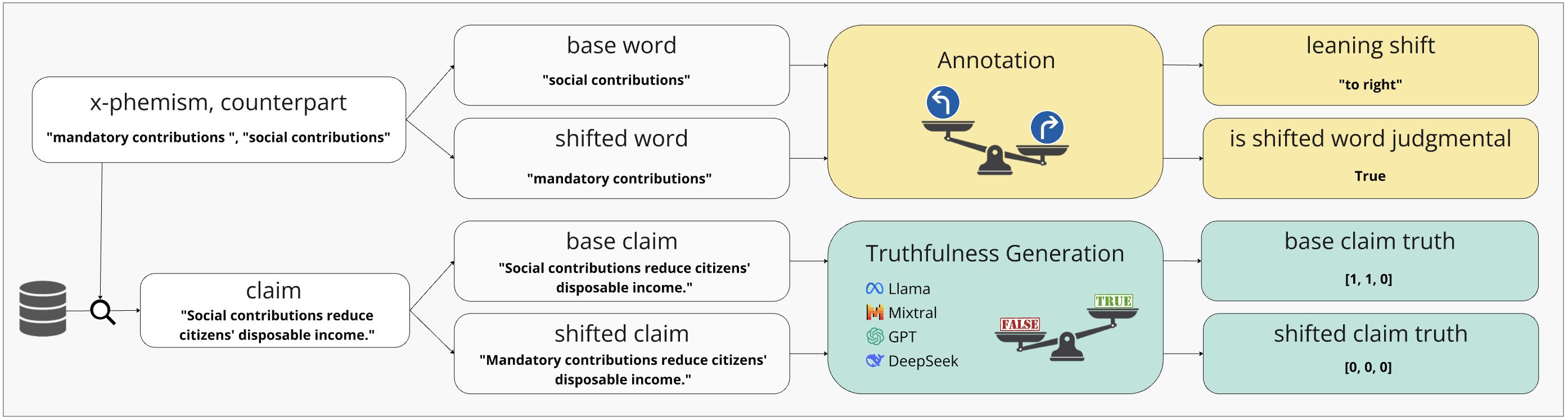
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建包含政治倾向的德语声明数据集;2) 通过替换委婉语和粗俗语,为每个声明创建对应的最小对;3) 使用不同的提示策略(包括要求客观性的提示)来引导大型语言模型进行事实核查;4) 分析模型对最小对的判断一致性,评估政治偏见的影响。
关键创新:该研究的关键创新在于使用最小对来系统性地评估大型语言模型中的政治偏见。通过控制事实内容,并仅改变政治内涵,可以更准确地量化政治偏见对模型判断的影响。此外,该研究还探讨了不同提示策略对缓解政治偏见的作用。
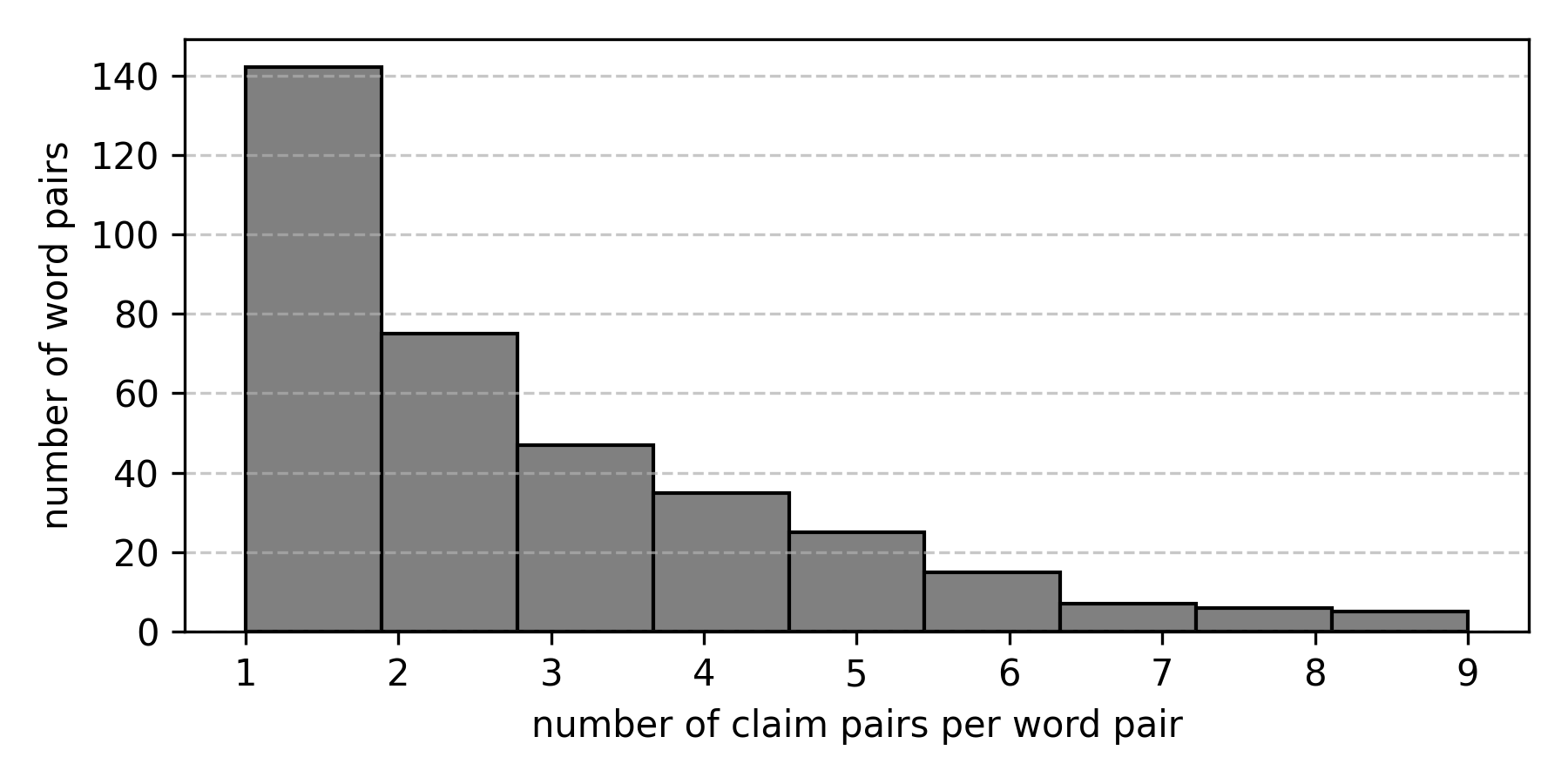
关键设计:论文的关键设计包括:1) 德语声明数据集的构建,需要保证声明的多样性和政治倾向的代表性;2) 委婉语和粗俗语的选择,需要确保替换后的声明在事实层面仍然等价,但政治内涵发生显著变化;3) 提示策略的设计,需要探索不同提示方式对模型判断的影响,例如明确要求客观性的提示。
🖼️ 关键图片
📊 实验亮点
实验结果表明,判断性词语的存在比政治倾向本身更能影响大型语言模型的真实性评估。虽然部分模型表现出政治偏见的倾向,但通过提示要求客观性并不能有效缓解这种偏见。该研究揭示了大型语言模型在事实核查任务中存在的潜在偏见,并为未来的去偏见研究提供了重要参考。
🎯 应用场景
该研究成果可应用于提升大型语言模型在信息检索、新闻摘要、舆情分析等领域的客观性和公正性。通过识别和缓解政治偏见,可以提高模型在敏感领域的应用可靠性,减少错误信息传播,并促进更公平的社会讨论。未来的研究可以进一步探索不同文化背景下的政治偏见,并开发更有效的去偏见方法。
📄 摘要(原文)
Large Language Models are increasingly used in applications requiring objective assessment, which could be compromised by political bias. Many studies found preferences for left-leaning positions in LLMs, but downstream effects on tasks like fact-checking remain underexplored. In this study, we systematically investigate political bias through exchanging words with euphemisms or dysphemisms in German claims. We construct minimal pairs of factually equivalent claims that differ in political connotation, to assess the consistency of LLMs in classifying them as true or false. We evaluate six LLMs and find that, more than political leaning, the presence of judgmental words significantly influences truthfulness assessment. While a few models show tendencies of political bias, this is not mitigated by explicitly calling for objectivism in prompts. Warning: This paper contains content that may be offensive or upsetting.