ATTS: Asynchronous Test-Time Scaling via Conformal Prediction
作者: Jing Xiong, Qiujiang Chen, Fanghua Ye, Zhongwei Wan, Chuanyang Zheng, Chenyang Zhao, Hui Shen, Alexander Hanbo Li, Chaofan Tao, Haochen Tan, Haoli Bai, Lifeng Shang, Lingpeng Kong, Ngai Wong
分类: cs.CL
发布日期: 2025-09-18 (更新: 2025-09-28)
备注: Tech Report
🔗 代码/项目: GITHUB
💡 一句话要点
ATTS:通过保形预测实现异步测试时扩展,显著加速大语言模型推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 测试时扩展 推测解码 异步推理 保形预测
📋 核心要点
- 现有大语言模型测试时扩展受限于高推理延迟和同步开销,尤其是在并行和顺序维度同时扩展时。
- ATTS通过在线校准实现异步推理,并设计序数分类算法支持三阶段拒绝采样,从而在保证精度前提下加速推理。
- 实验表明,ATTS在多个数据集上实现了显著的加速和吞吐量提升,同时降低了延迟和内存开销。
📝 摘要(中文)
大型语言模型(LLM)受益于测试时扩展,但常常受到高推理延迟的阻碍。推测解码是加速扩展过程的一种自然方法;然而,沿并行和顺序维度进行扩展带来了重大挑战,包括大量的内存受限执行和同步开销。我们引入了ATTS(异步测试时扩展),这是一个统计保证的自适应扩展框架,它遵循假设检验过程来解决这些挑战。通过重新审视算术强度,ATTS将同步确定为主要瓶颈。它通过在线校准实现异步推理,并提出了一种支持三阶段拒绝采样流水线的序数分类算法,从而沿顺序和并行轴进行扩展。在MATH、AMC23、AIME24和AIME25数据集以及多个draft-target模型家族的实验中,我们表明ATTS在测试时扩展中提供了高达56.7倍的加速和4.14倍的吞吐量提升,同时保持对拒绝率的精确控制,降低延迟和内存开销,并且不会造成精度损失。通过在并行和顺序维度上进行扩展,我们使1.5B/70B draft/target模型组合在AIME数据集上实现了最先进的推理模型o3-mini (high)的性能。我们已在https://github.com/menik1126/asynchronous-test-time-scaling上发布了代码。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在测试时扩展过程中,由于高推理延迟和同步开销导致的效率瓶颈问题。现有的推测解码方法在并行和顺序维度同时扩展时,会面临严重的内存受限执行和同步开销,限制了推理速度的提升。
核心思路:ATTS的核心思路是通过异步推理来消除同步瓶颈。它通过在线校准来动态调整扩展策略,并利用序数分类算法来支持三阶段拒绝采样流水线,从而在保证精度的前提下,最大限度地利用计算资源。这种异步的方式可以显著降低延迟和内存开销,提高推理效率。
技术框架:ATTS框架主要包含以下几个关键模块:1) 在线校准模块:用于动态估计draft模型的预测置信度,并根据置信度调整扩展策略。2) 序数分类模块:用于预测target模型对draft模型预测的接受程度,从而实现三阶段拒绝采样。3) 异步推理引擎:负责执行异步的draft和target模型推理,并协调各个模块之间的交互。整体流程是,首先利用draft模型进行快速预测,然后通过在线校准和序数分类来判断是否需要target模型进行验证,最终输出结果。
关键创新:ATTS的关键创新在于其异步推理机制和自适应扩展策略。与传统的同步推测解码方法不同,ATTS允许draft和target模型异步执行,从而避免了同步等待造成的延迟。此外,ATTS还能够根据draft模型的预测置信度动态调整扩展策略,从而在保证精度的前提下,最大限度地利用计算资源。
关键设计:ATTS的关键设计包括:1) 在线校准算法:采用保形预测(Conformal Prediction)方法,对draft模型的预测结果进行校准,得到置信度估计。2) 序数分类算法:将target模型对draft模型预测的接受程度建模为一个序数分类问题,并设计相应的损失函数进行训练。3) 三阶段拒绝采样流水线:根据序数分类的结果,将拒绝采样过程分为三个阶段,从而实现更精细的控制。
🖼️ 关键图片
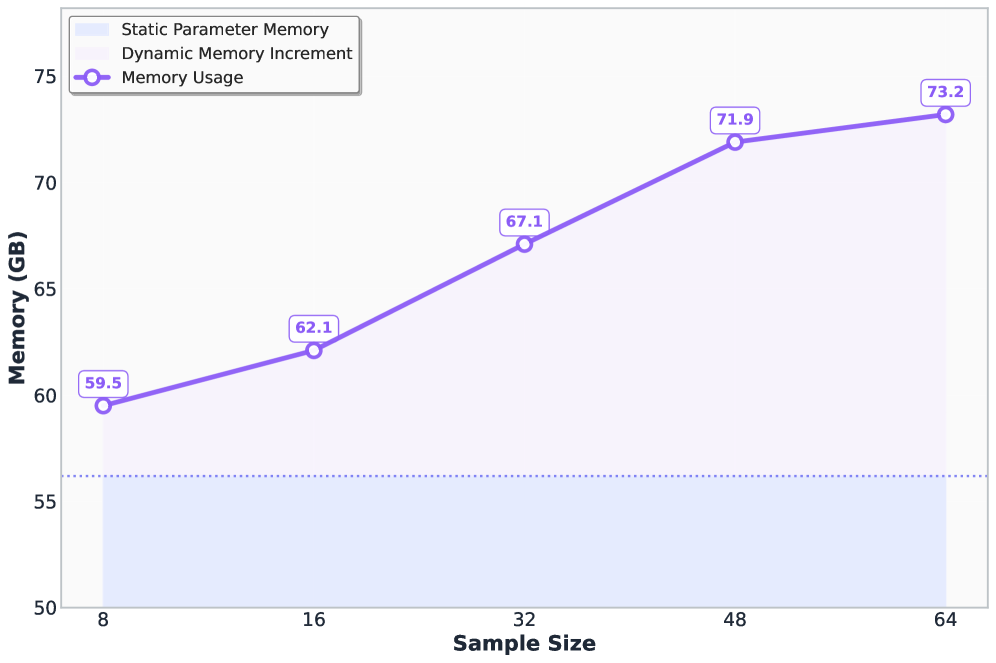
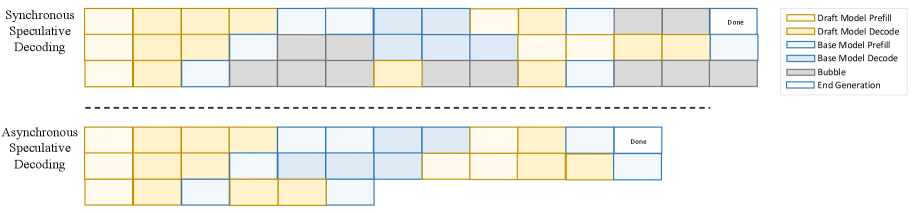
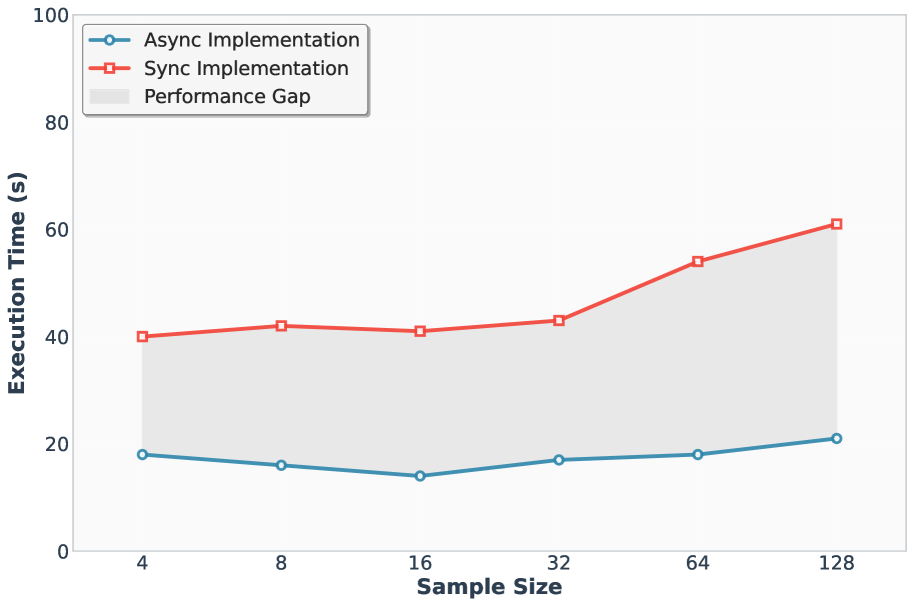
📊 实验亮点
ATTS在MATH、AMC23、AIME24和AIME25等数据集上进行了广泛的实验,结果表明,ATTS在测试时扩展中提供了高达56.7倍的加速和4.14倍的吞吐量提升,同时保持对拒绝率的精确控制,降低延迟和内存开销,并且不会造成精度损失。通过并行和顺序维度扩展,1.5B/70B draft/target模型组合在AIME数据集上实现了最先进的推理模型o3-mini (high)的性能。
🎯 应用场景
ATTS具有广泛的应用前景,可以应用于各种需要加速大语言模型推理的场景,例如在线问答、机器翻译、文本生成等。通过降低推理延迟和内存开销,ATTS可以提高用户体验,并降低部署成本。此外,ATTS还可以促进大语言模型在资源受限设备上的应用,例如移动设备和嵌入式系统。
📄 摘要(原文)
Large language models (LLMs) benefit from test-time scaling but are often hampered by high inference latency. Speculative decoding is a natural way to accelerate the scaling process; however, scaling along both the parallel and sequential dimensions poses significant challenges, including substantial memory-bound execution and synchronization overhead. We introduce ATTS (Asynchronous Test-Time Scaling), a statistically guaranteed adaptive scaling framework that follows the hypothesis testing process to address these challenges. By revisiting arithmetic intensity, ATTS identifies synchronization as the primary bottleneck. It enables asynchronous inference through online calibration and proposes an ordinal classification algorithm that supports a three-stage rejection sampling pipeline, scaling along both the sequential and parallel axes. Across experiments on the MATH, AMC23, AIME24, and AIME25 datasets and across multiple draft-target model families, we show that ATTS delivers up to 56.7x speedup in test-time scaling and a 4.14x throughput improvement, while maintaining accurate control of the rejection rate, reducing latency and memory overhead, and incurring no accuracy loss. By scaling both in parallel and sequential dimensions, we enable the 1.5B/70B draft/target model combination to achieve the performance of the state-of-the-art reasoning model o3-mini (high) on the AIME dataset. We have released the code at https://github.com/menik1126/asynchronous-test-time-scaling.