TextMineX: Data, Evaluation Framework and Ontology-guided LLM Pipeline for Humanitarian Mine Action
作者: Chenyue Zhou, Gürkan Solmaz, Flavio Cirillo, Kiril Gashteovski, Jonathan Fürst
分类: cs.CL, cs.AI
发布日期: 2025-09-18 (更新: 2026-01-27)
💡 一句话要点
TextMineX:构建人道主义排雷领域知识抽取数据集与本体引导的LLM流程
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人道主义排雷 知识抽取 大型语言模型 领域本体 信息提取
📋 核心要点
- 人道主义排雷行动产生大量知识,但非结构化报告阻碍了信息共享和利用。
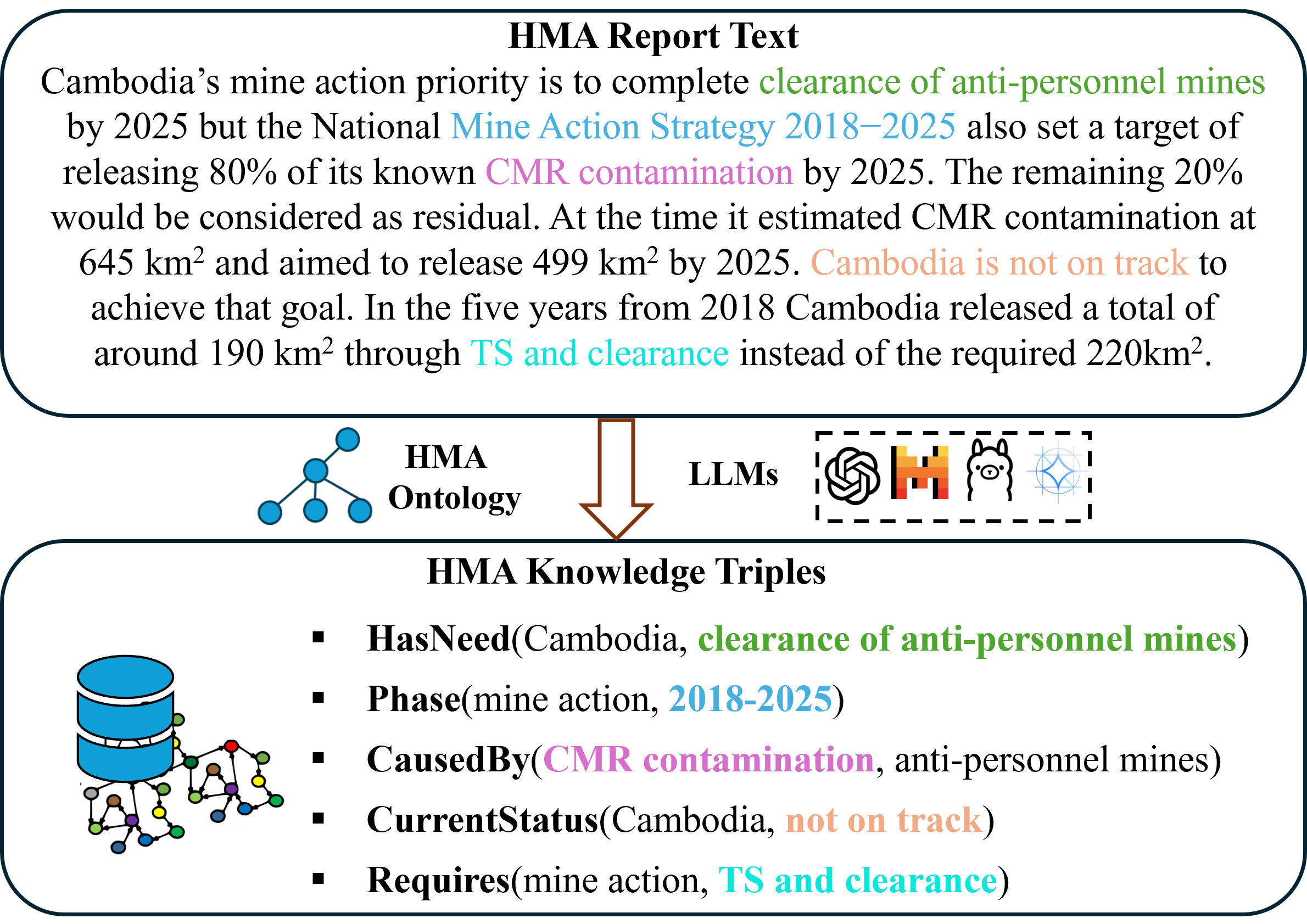
- TextMineX提出了一种基于本体引导的LLM流程,将非结构化报告转化为(主体, 关系, 客体)三元组。
- 实验表明,该方法显著提高了知识抽取准确率,减少了幻觉,并增强了格式一致性。
📝 摘要(中文)
人道主义排雷行动(HMA)旨在解决冲突地区地雷探测与移除的难题。HMA机构产生的大量拯救生命的操作知识隐藏在非结构化报告中,限制了机构间的信息传递。为了解决这个问题,我们提出了TextMineX:这是首个针对HMA领域文本知识抽取的数据集、评估框架和本体引导的大型语言模型(LLM)流程。TextMineX将HMA报告结构化为(主体, 关系, 客体)三元组,从而创建特定领域的知识。为了确保与现实世界的关联性,我们使用了来自合作方柬埔寨排雷行动中心(CMAC)的数据集。我们进一步引入了一种偏差感知的评估框架,该框架结合了人工标注的三元组和LLM-as-Judge协议,以减轻无参考评分中的位置偏差。实验表明,与基线模型相比,本体对齐的提示可将提取准确率提高高达44.2%,减少幻觉22.5%,并提高格式一致性20.9%。我们公开发布数据集和代码。
🔬 方法详解
问题定义:人道主义排雷行动领域存在大量非结构化的报告,这些报告蕴含着重要的操作知识。然而,由于缺乏结构化的数据表示和有效的知识抽取方法,这些知识难以被有效利用和共享,从而限制了排雷行动的效率和安全性。现有方法难以从这些非结构化文本中准确、高效地提取关键信息,并将其转化为可用的知识。
核心思路:TextMineX的核心思路是利用大型语言模型(LLM)的强大文本理解和生成能力,结合领域本体的知识指导,从非结构化的HMA报告中抽取结构化的知识三元组。通过本体对齐的提示,引导LLM更好地理解HMA领域的概念和关系,从而提高知识抽取的准确性和可靠性。这种方法旨在弥合非结构化文本和结构化知识之间的差距,为HMA领域提供更有效的知识管理和利用手段。
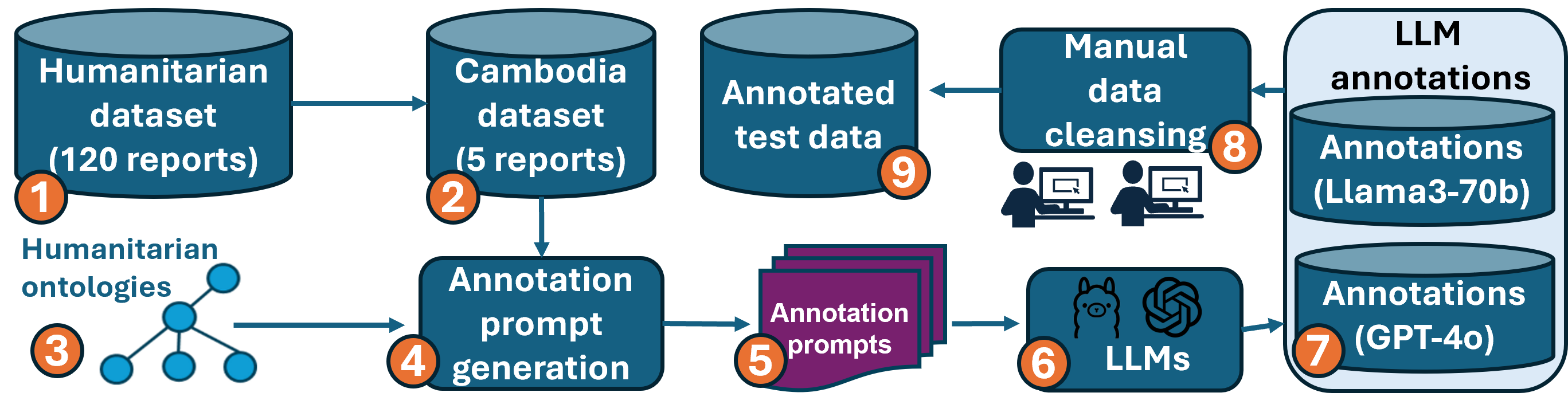
技术框架:TextMineX的整体流程包括以下几个主要阶段:1) 数据集构建:收集和整理来自CMAC的HMA报告,并进行人工标注,构建用于训练和评估的数据集。2) 本体构建:构建HMA领域的本体,定义领域内的概念、关系和属性。3) LLM微调:使用标注的数据集对LLM进行微调,使其适应HMA领域的知识抽取任务。4) 本体引导的提示:设计本体对齐的提示,引导LLM更好地理解和抽取知识。5) 评估框架:设计偏差感知的评估框架,结合人工标注和LLM-as-Judge协议,评估知识抽取的性能。
关键创新:TextMineX的关键创新在于以下几个方面:1) 首次构建了HMA领域的知识抽取数据集,为该领域的研究提供了数据基础。2) 提出了本体引导的LLM流程,利用领域本体的知识指导LLM进行知识抽取,提高了准确性和可靠性。3) 设计了偏差感知的评估框架,减轻了无参考评分中的位置偏差,更客观地评估了知识抽取的性能。
关键设计:在本体引导的提示设计中,论文采用了本体对齐的方法,将本体中的概念和关系融入到提示中,引导LLM更好地理解HMA领域的知识。在评估框架中,论文采用了LLM-as-Judge协议,利用LLM的文本理解能力来评估知识抽取的质量,并结合人工标注来校正LLM的偏差。具体的参数设置和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TextMineX方法在知识抽取方面取得了显著的性能提升。与基线模型相比,本体对齐的提示可将提取准确率提高高达44.2%,减少幻觉22.5%,并提高格式一致性20.9%。这些结果表明,TextMineX方法能够有效地从非结构化HMA报告中抽取准确、可靠的知识。
🎯 应用场景
TextMineX可应用于人道主义排雷行动领域,帮助排雷机构更有效地管理和利用操作知识,提高排雷效率和安全性。通过结构化HMA报告,可以促进机构间的信息共享和协作,加速排雷进程。未来,该方法还可扩展到其他类似的领域,如灾害救援、公共卫生等,为知识管理和决策提供支持。
📄 摘要(原文)
Humanitarian Mine Action (HMA) addresses the challenge of detecting and removing landmines from conflict regions. Much of the life-saving operational knowledge produced by HMA agencies is buried in unstructured reports, limiting the transferability of information between agencies. To address this issue, we propose TextMineX: the first dataset, evaluation framework and ontology-guided large language model (LLM) pipeline for knowledge extraction from text in the HMA domain. TextMineX structures HMA reports into (subject, relation, object)-triples, thus creating domain-specific knowledge. To ensure real-world relevance, we utilized the dataset from our collaborator Cambodian Mine Action Centre (CMAC). We further introduce a bias-aware evaluation framework that combines human-annotated triples with an LLM-as-Judge protocol to mitigate position bias in reference-free scoring. Our experiments show that ontology-aligned prompts improve extraction accuracy by up to 44.2%, reduce hallucinations by 22.5%, and enhance format adherence by 20.9% compared to baseline models. We publicly release the dataset and code.