LLM-OREF: An Open Relation Extraction Framework Based on Large Language Models
作者: Hongyao Tu, Liang Zhang, Yujie Lin, Xin Lin, Haibo Zhang, Long Zhang, Jinsong Su
分类: cs.CL
发布日期: 2025-09-18
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于大语言模型的开放关系抽取框架LLM-OREF,无需人工干预即可泛化到新关系。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放关系抽取 大语言模型 关系发现 关系预测 自校正推理 知识图谱 信息抽取
📋 核心要点
- 现有开放关系抽取方法依赖于人工标注,限制了其在实际应用中的可用性。
- LLM-OREF框架利用大语言模型的理解和生成能力,通过关系发现器和关系预测器直接预测新关系,无需人工干预。
- 该框架设计了自校正推理策略,包含关系发现、去噪和预测三个阶段,提升了预测新关系的能力,并在多个数据集上验证了有效性。
📝 摘要(中文)
开放关系抽取(OpenRE)旨在开发一种能够泛化到训练期间未遇到的新关系的关系抽取模型。现有研究主要将OpenRE形式化为聚类任务,首先基于实例之间的相似性对所有测试实例进行聚类,然后手动为每个聚类分配一个新关系,但对人工标注的依赖限制了它们的实用性。本文提出了一种基于大语言模型(LLM)的OpenRE框架,该框架利用LLM强大的语言理解和生成能力,直接预测测试实例的新关系,无需人工干预。具体来说,我们的框架包含两个核心组件:(1)关系发现器(RD),旨在基于由具有已知关系的训练实例形成的演示来预测测试实例的新关系;(2)关系预测器(RP),用于在由实例组成的演示的指导下,从$n$个候选关系中为测试实例选择最可能的关系。为了增强我们的框架预测新关系的能力,我们设计了一种由关系发现、关系去噪和关系预测三个阶段组成的自校正推理策略。在第一阶段,我们使用RD初步预测所有测试实例的新关系。接下来,我们应用RP通过交叉验证方法从RD的预测结果中为每个新关系选择一些高可靠性的测试实例。在第三阶段,我们利用RP基于由这些可靠的测试实例构建的演示来重新预测所有测试实例的关系。在三个OpenRE数据集上的大量实验证明了我们框架的有效性。我们的代码已在https://github.com/XMUDeepLIT/LLM-OREF.git上发布。
🔬 方法详解
问题定义:开放关系抽取旨在识别文本中实体之间的关系,并推广到训练集中未出现的新关系类型。现有方法通常依赖于聚类,然后需要人工标注聚类结果以确定关系类型,这限制了其可扩展性和自动化程度。
核心思路:利用大语言模型(LLM)强大的语言理解和生成能力,直接预测测试实例的关系类型,避免人工标注。通过“演示”(demonstrations)的方式,让LLM学习如何从已知关系推断未知关系。
技术框架:LLM-OREF框架包含两个主要模块:关系发现器(RD)和关系预测器(RP)。RD负责基于训练数据的“演示”初步预测测试实例的关系。RP则从多个候选关系中选择最可能的关系,同样依赖于“演示”。为了提高预测准确性,框架采用自校正推理策略,包含关系发现、关系去噪和关系预测三个阶段。
关键创新:核心创新在于利用LLM直接进行开放关系抽取,避免了传统方法对人工标注的依赖。自校正推理策略通过交叉验证选择高可靠性的实例,并利用这些实例重新预测关系,提高了整体预测的准确性和鲁棒性。
关键设计:关系发现器和关系预测器都依赖于LLM,具体的LLM选择和prompt设计是关键。自校正推理策略中的交叉验证方法用于选择高可靠性实例,其具体实现细节(例如,如何定义“可靠性”,如何进行交叉验证)会影响最终性能。此外,如何构建有效的“演示”也是一个重要的设计选择。
🖼️ 关键图片
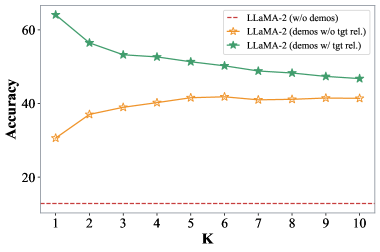


📊 实验亮点
实验结果表明,LLM-OREF框架在三个开放关系抽取数据集上表现出色,验证了其有效性。通过自校正推理策略,框架能够有效提升预测准确率,并在无需人工干预的情况下,实现对新关系的自动抽取和识别。具体性能数据和对比基线未在摘要中给出。
🎯 应用场景
该研究成果可应用于知识图谱构建、信息抽取、问答系统等领域。无需大量人工标注即可自动发现和抽取新的关系,降低了知识获取的成本,提高了知识图谱的覆盖率和质量。未来可应用于智能客服、舆情分析等场景,提升自动化知识发现和推理能力。
📄 摘要(原文)
The goal of open relation extraction (OpenRE) is to develop an RE model that can generalize to new relations not encountered during training. Existing studies primarily formulate OpenRE as a clustering task. They first cluster all test instances based on the similarity between the instances, and then manually assign a new relation to each cluster. However, their reliance on human annotation limits their practicality. In this paper, we propose an OpenRE framework based on large language models (LLMs), which directly predicts new relations for test instances by leveraging their strong language understanding and generation abilities, without human intervention. Specifically, our framework consists of two core components: (1) a relation discoverer (RD), designed to predict new relations for test instances based on \textit{demonstrations} formed by training instances with known relations; and (2) a relation predictor (RP), used to select the most likely relation for a test instance from $n$ candidate relations, guided by \textit{demonstrations} composed of their instances. To enhance the ability of our framework to predict new relations, we design a self-correcting inference strategy composed of three stages: relation discovery, relation denoising, and relation prediction. In the first stage, we use RD to preliminarily predict new relations for all test instances. Next, we apply RP to select some high-reliability test instances for each new relation from the prediction results of RD through a cross-validation method. During the third stage, we employ RP to re-predict the relations of all test instances based on the demonstrations constructed from these reliable test instances. Extensive experiments on three OpenRE datasets demonstrate the effectiveness of our framework. We release our code at https://github.com/XMUDeepLIT/LLM-OREF.git.