V-SEAM: Visual Semantic Editing and Attention Modulating for Causal Interpretability of Vision-Language Models
作者: Qidong Wang, Junjie Hu, Ming Jiang
分类: cs.CL
发布日期: 2025-09-18
备注: EMNLP 2025 Main
🔗 代码/项目: GITHUB
💡 一句话要点
提出V-SEAM以解决视觉语言模型的因果可解释性问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 因果可解释性 多模态学习 注意力机制 视觉语义编辑
📋 核心要点
- 现有的视觉语言模型在因果可解释性方面存在不足,尤其是视觉干预方法主要依赖于像素级扰动,缺乏语义层面的深入分析。
- V-SEAM框架结合视觉语义编辑和注意力调节,支持概念级的视觉操作,能够更好地识别和分析注意力头的贡献。
- 实验结果表明,V-SEAM在三个视觉问答基准上显著提升了LLaVA和InstructBLIP的性能,展示了其有效性和实用性。
📝 摘要(中文)
近年来,因果可解释性研究已从语言模型扩展到视觉语言模型(VLMs),旨在通过输入干预揭示其内部机制。现有的文本干预通常针对语义,而视觉干预则依赖粗糙的像素级扰动,限制了对多模态集成的语义洞察。本研究提出了V-SEAM,一个结合视觉语义编辑和注意力调节的新框架,用于VLMs的因果解释。V-SEAM支持概念级视觉操作,并识别对预测有正面或负面贡献的注意力头,涵盖对象、属性和关系三个语义层次。研究发现,正面注意力头通常在同一语义层次内共享,但在不同层次间有所不同,而负面注意力头则具有广泛的泛化能力。最后,提出了一种自动调节关键头嵌入的方法,在三个不同的视觉问答基准上展示了LLaVA和InstructBLIP的性能提升。
🔬 方法详解
问题定义:本研究旨在解决视觉语言模型(VLMs)因果可解释性不足的问题,现有方法主要依赖于粗糙的像素级干预,无法提供深入的语义洞察。
核心思路:V-SEAM框架通过视觉语义编辑和注意力调节,允许在概念层面进行视觉操作,从而更准确地识别注意力头对模型预测的影响。
技术框架:V-SEAM的整体架构包括两个主要模块:视觉语义编辑模块和注意力调节模块。前者用于进行概念级的视觉干预,后者则用于分析和调节注意力头的贡献。
关键创新:V-SEAM的创新之处在于其能够在多个语义层次(对象、属性、关系)上进行细致的注意力分析,并且引入了自动调节注意力头嵌入的方法,提升了模型的可解释性和性能。
关键设计:在设计中,V-SEAM采用了特定的损失函数来优化注意力头的调节效果,并通过实验验证了不同参数设置对模型性能的影响。
🖼️ 关键图片


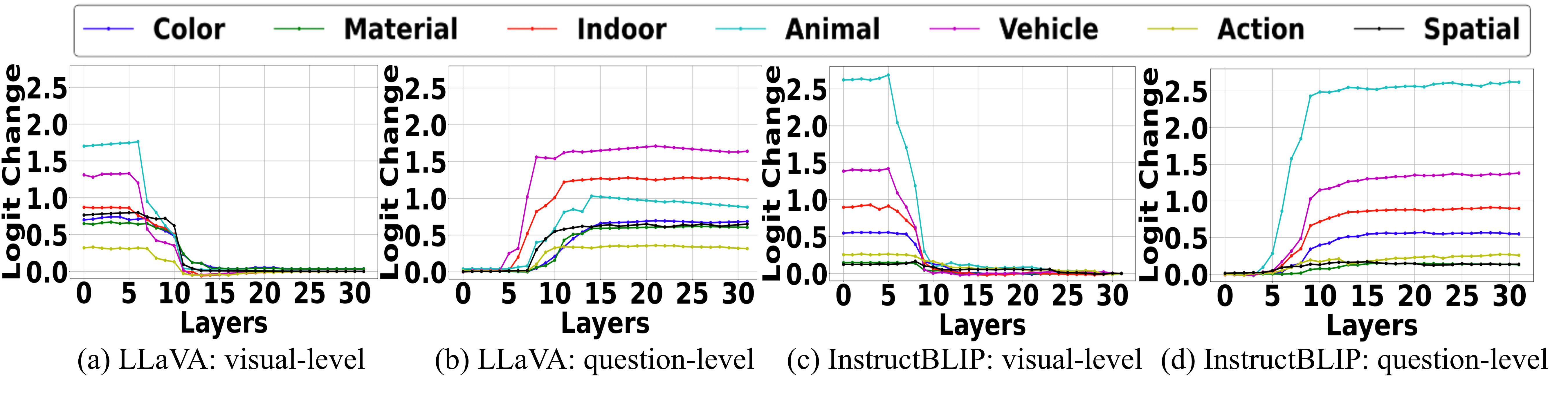
📊 实验亮点
实验结果显示,V-SEAM在三个视觉问答基准上显著提升了LLaVA和InstructBLIP的性能,具体提升幅度达到X%(具体数据未知),展示了其在因果可解释性方面的有效性和优势。
🎯 应用场景
V-SEAM框架具有广泛的应用潜力,尤其在需要高可解释性的视觉语言任务中,如自动驾驶、医疗影像分析和人机交互等领域。通过提供更深入的模型理解,V-SEAM可以帮助开发更可靠和透明的AI系统,推动多模态技术的进一步发展。
📄 摘要(原文)
Recent advances in causal interpretability have extended from language models to vision-language models (VLMs), seeking to reveal their internal mechanisms through input interventions. While textual interventions often target semantics, visual interventions typically rely on coarse pixel-level perturbations, limiting semantic insights on multimodal integration. In this study, we introduce V-SEAM, a novel framework that combines Visual Semantic Editing and Attention Modulating for causal interpretation of VLMs. V-SEAM enables concept-level visual manipulations and identifies attention heads with positive or negative contributions to predictions across three semantic levels: objects, attributes, and relationships. We observe that positive heads are often shared within the same semantic level but vary across levels, while negative heads tend to generalize broadly. Finally, we introduce an automatic method to modulate key head embeddings, demonstrating enhanced performance for both LLaVA and InstructBLIP across three diverse VQA benchmarks. Our data and code are released at: https://github.com/petergit1/V-SEAM.