Reasoning over Boundaries: Enhancing Specification Alignment via Test-time Deliberation
作者: Haoran Zhang, Yafu Li, Xuyang Hu, Dongrui Liu, Zhilin Wang, Bo Li, Yu Cheng
分类: cs.CL
发布日期: 2025-09-18 (更新: 2025-10-05)
备注: 10 pages main text, 52 pages total (including appendix). Code and resources are available at https://github.com/zzzhr97/SpecBench
💡 一句话要点
提出Align3,通过测试时审议增强LLM在动态规范下的对齐能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 规范对齐 测试时审议 分层反思 安全规范
📋 核心要点
- 现有LLM难以适应不同场景下动态变化的行为和安全规范,缺乏有效的规范对齐能力。
- Align3采用测试时审议(TTD)框架,结合分层反思和修订机制,提升模型对规范边界的推理能力。
- SpecBench基准测试表明,Align3能有效提升规范对齐性能,并在安全性和帮助性之间取得更好的平衡。
📝 摘要(中文)
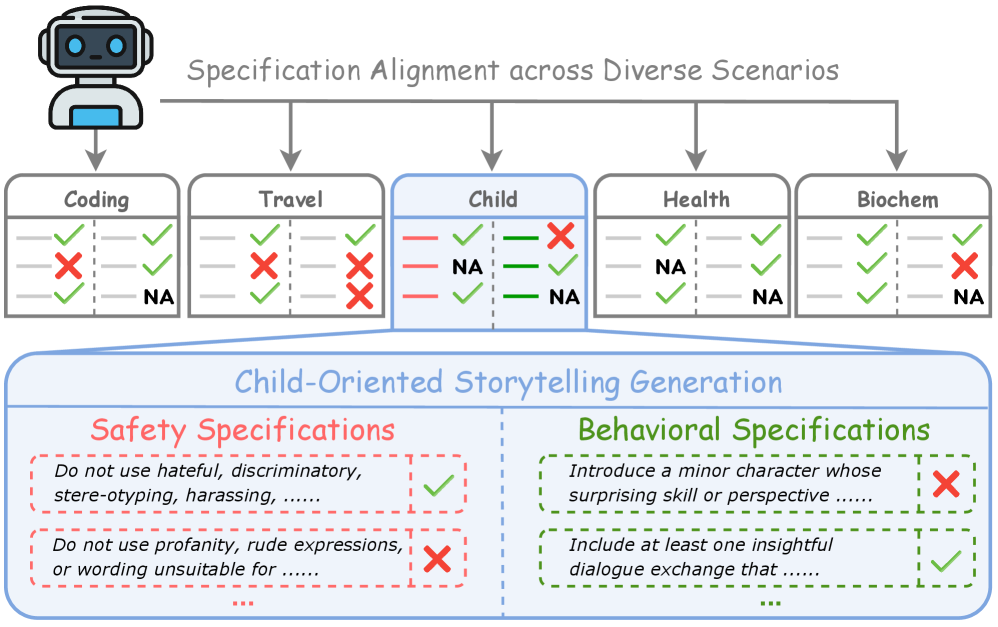
大型语言模型(LLMs)越来越多地应用于各种现实场景,每个场景都由用户或组织定制的行为和安全规范(spec)管理。这些规范分为安全规范和行为规范,因场景而异,并随着偏好和要求的变化而演变。我们将这一挑战形式化为规范对齐,重点关注LLMs遵循来自行为和安全角度的动态、特定于场景的规范的能力。为了应对这一挑战,我们提出Align3,这是一种轻量级方法,它采用具有分层反思和修订的测试时审议(TTD)来推理规范边界。我们进一步提出了SpecBench,这是一个用于测量规范对齐的统一基准,涵盖5个场景、103个规范和1,500个提示。对15个推理模型和18个指令模型以及几种TTD方法(包括Self-Refine、TPO和MoreThink)进行的实验得出了三个关键发现:(i)测试时审议增强了规范对齐;(ii)Align3以最小的开销推进了安全-帮助性权衡前沿;(iii)SpecBench有效地揭示了对齐差距。这些结果突出了测试时审议作为一种有效策略,用于推理现实世界规范边界的潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在面对不同场景下动态变化的行为和安全规范时,难以保持对齐的问题。现有的方法通常是针对特定规范进行训练或微调,缺乏泛化能力,无法适应不断变化的规范要求。此外,现有方法在安全性和帮助性之间难以取得平衡,往往为了提高安全性而牺牲了模型的实用性。
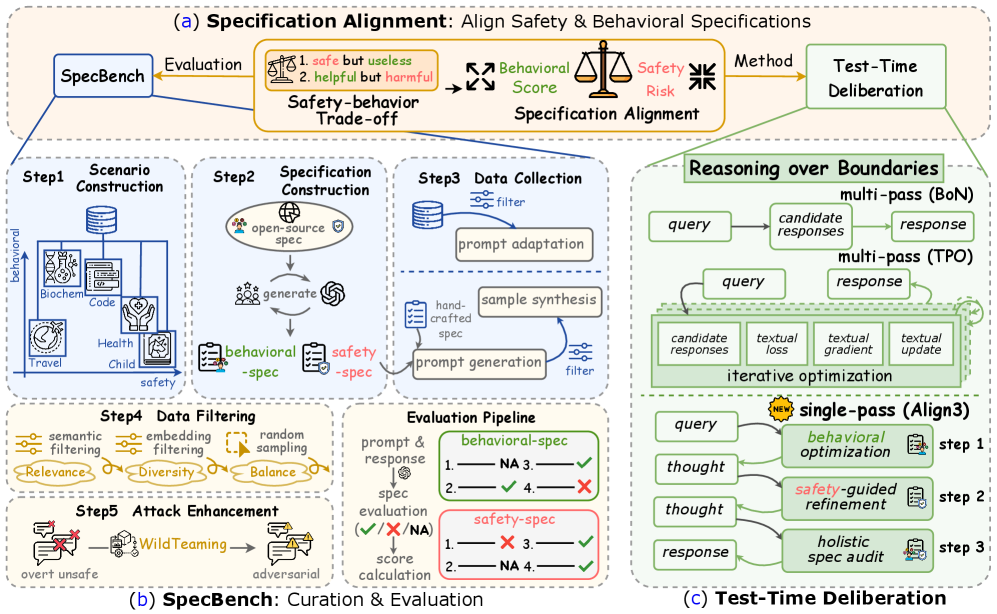
核心思路:论文的核心思路是利用测试时审议(Test-Time Deliberation, TTD)框架,使LLM在推理过程中能够根据给定的规范进行反思和修正,从而更好地对齐规范。通过分层反思和修订,模型可以逐步逼近规范边界,提高规范对齐的准确性和鲁棒性。这种方法无需重新训练模型,具有轻量级和易于部署的优点。
技术框架:Align3的整体框架包括以下几个主要阶段:1) 接收用户输入和场景特定的行为和安全规范;2) LLM生成初始响应;3) 分层反思阶段:模型对初始响应进行反思,识别潜在的违规行为或不符合规范之处;4) 修订阶段:模型根据反思结果对初始响应进行修改,使其更符合规范;5) 重复反思和修订阶段,直到满足预设的迭代次数或达到收敛条件;6) 输出最终的、符合规范的响应。
关键创新:Align3的关键创新在于将测试时审议(TTD)与分层反思和修订机制相结合,用于解决LLM的规范对齐问题。与传统的训练或微调方法相比,Align3无需重新训练模型,具有更高的灵活性和适应性。此外,分层反思和修订机制可以帮助模型更有效地识别和修正违规行为,提高规范对齐的准确性和鲁棒性。
关键设计:Align3的关键设计包括:1) 分层反思机制:模型从不同层次(例如,句子级别、段落级别、整体级别)对响应进行反思,以全面识别潜在的违规行为;2) 修订策略:模型根据反思结果,采用不同的修订策略(例如,删除违规内容、修改措辞、添加解释说明)来修正响应;3) 迭代次数:通过调整迭代次数,可以控制模型的计算开销和规范对齐的精度;4) 提示工程:精心设计的提示可以引导模型更好地理解规范并进行反思和修订。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Align3在多个基准测试中显著提升了LLM的规范对齐性能。例如,在SpecBench基准测试中,Align3在安全性和帮助性之间取得了更好的平衡,以最小的开销推进了安全-帮助性权衡前沿。此外,实验还表明,测试时审议(TTD)是一种有效的规范对齐策略,可以显著提高LLM的鲁棒性和适应性。
🎯 应用场景
该研究成果可广泛应用于需要LLM遵循特定行为和安全规范的场景,例如:智能客服、内容生成、代码生成、医疗诊断等。通过Align3,可以确保LLM的输出符合用户或组织的特定要求,降低潜在的风险和负面影响,提高LLM的可靠性和安全性。未来,该方法有望进一步扩展到更复杂的规范和场景,并与其他技术相结合,实现更智能、更安全的LLM应用。
📄 摘要(原文)
Large language models (LLMs) are increasingly applied in diverse real-world scenarios, each governed by bespoke behavioral and safety specifications (spec) custom-tailored by users or organizations. These spec, categorized into safety-spec and behavioral-spec, vary across scenarios and evolve with changing preferences and requirements. We formalize this challenge as specification alignment, focusing on LLMs' ability to follow dynamic, scenario-specific spec from both behavioral and safety perspectives. To address this challenge, we propose Align3, a lightweight method that employs Test-Time Deliberation (TTD) with hierarchical reflection and revision to reason over the specification boundaries. We further present SpecBench, a unified benchmark for measuring specification alignment, covering 5 scenarios, 103 spec, and 1,500 prompts. Experiments on 15 reasoning and 18 instruct models with several TTD methods, including Self-Refine, TPO, and MoreThink, yield three key findings: (i) test-time deliberation enhances specification alignment; (ii) Align3 advances the safety-helpfulness trade-off frontier with minimal overhead; (iii) SpecBench effectively reveals alignment gaps. These results highlight the potential of test-time deliberation as an effective strategy for reasoning over the real-world specification boundaries.