TableDART: Dynamic Adaptive Multi-Modal Routing for Table Understanding
作者: Xiaobo Xing, Wei Yuan, Tong Chen, Quoc Viet Hung Nguyen, Xiangliang Zhang, Hongzhi Yin
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-18
💡 一句话要点
TableDART:动态自适应多模态路由用于表格理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格理解 多模态学习 动态路由 知识集成 自然语言处理
📋 核心要点
- 现有表格理解方法在处理表格数据的语义和结构信息时存在不足,例如Table-as-Text丢失结构信息,Table-as-Image语义理解不足。
- TableDART通过动态选择文本、图像或融合路径,并利用agent进行跨模态知识集成,从而更有效地利用多模态信息。
- 实验结果表明,TableDART在多个基准测试中取得了显著的性能提升,超越了现有最佳开源模型。
📝 摘要(中文)
表格数据的语义和结构信息建模是有效表格理解的核心挑战。现有的Table-as-Text方法将表格扁平化以供大型语言模型(LLMs)使用,但丢失了关键的结构线索;而Table-as-Image方法保留了结构,但在细粒度语义方面表现不佳。最近的Table-as-Multimodality策略试图结合文本和视觉视图,但它们(1)静态地处理每个查询-表格对的两种模态,不可避免地引入冗余甚至冲突,并且(2)依赖于对MLLM进行昂贵的微调。鉴于此,我们提出了TableDART,一个训练高效的框架,通过重用预训练的单模态模型来集成多模态视图。TableDART引入了一个轻量级的259万参数的MLP门控网络,可以为每个表格-查询对动态选择最佳路径(仅文本、仅图像或融合),从而有效地减少了来自两种模态的冗余和冲突。此外,我们提出了一个新的agent来协调跨模态知识集成,通过分析来自基于文本和基于图像的模型的输出,选择最佳结果或通过推理综合新的答案。这种设计避免了完全MLLM微调的过高成本。在七个基准上的大量实验表明,TableDART在开源模型中建立了新的最先进性能,平均超过最强的基线4.02%。代码可在https://anonymous.4open.science/r/TableDART-C52B获得。
🔬 方法详解
问题定义:现有表格理解方法,如Table-as-Text和Table-as-Image,分别存在丢失结构信息和语义理解不足的问题。多模态方法虽然尝试结合两者,但静态处理所有模态引入冗余和冲突,且依赖昂贵的MLLM微调。
核心思路:TableDART的核心思路是动态地为每个表格-查询对选择最佳模态路径(文本、图像或融合),并利用一个agent来协调跨模态知识集成。这样可以避免冗余计算,减少模态冲突,并降低训练成本。
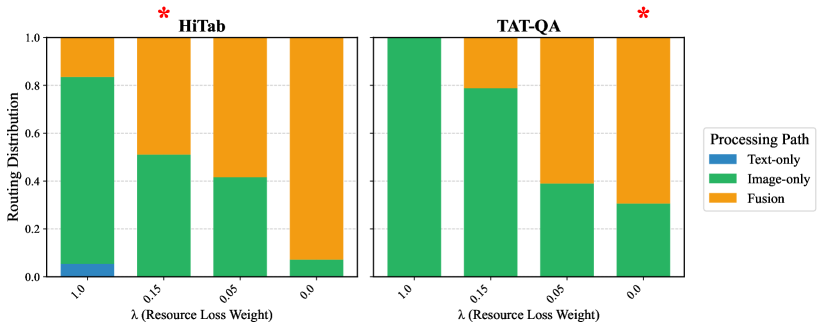
技术框架:TableDART包含三个主要模块:文本模型、图像模型和一个门控网络。文本模型和图像模型分别处理表格的文本和图像表示。门控网络根据表格-查询对的特征,动态选择最佳路径。如果选择融合路径,则文本和图像模型的输出会传递给一个agent,该agent负责选择最佳结果或通过推理生成新的答案。
关键创新:TableDART的关键创新在于动态自适应多模态路由和跨模态知识集成agent。动态路由允许模型根据输入自适应地选择最佳模态路径,避免了静态处理所有模态的冗余和冲突。跨模态知识集成agent则负责协调不同模态的信息,从而提高最终的预测准确性。
关键设计:TableDART使用一个轻量级的2.59M参数的MLP作为门控网络,以降低计算成本。Agent的设计基于对文本和图像模型输出的分析,并使用简单的规则或学习到的策略来选择最佳结果或生成新的答案。损失函数的设计旨在优化门控网络的路由决策和agent的知识集成能力。
🖼️ 关键图片


📊 实验亮点
TableDART在七个基准测试中取得了新的state-of-the-art性能,平均超过最强的基线4.02%。这一显著的性能提升表明TableDART在表格理解方面具有很强的竞争力。值得注意的是,TableDART在训练效率方面也具有优势,避免了对大型多模态语言模型进行昂贵的微调。
🎯 应用场景
TableDART可应用于各种需要理解表格数据的场景,例如智能问答、数据分析、报告生成等。该研究成果有助于提升机器对表格数据的理解能力,从而提高相关应用的智能化水平和效率。未来,该方法可以进一步扩展到处理更复杂的表格结构和多语言表格数据。
📄 摘要(原文)
Modeling semantic and structural information from tabular data remains a core challenge for effective table understanding. Existing Table-as-Text approaches flatten tables for large language models (LLMs), but lose crucial structural cues, while Table-as-Image methods preserve structure yet struggle with fine-grained semantics. Recent Table-as-Multimodality strategies attempt to combine textual and visual views, but they (1) statically process both modalities for every query-table pair within a large multimodal LLMs (MLLMs), inevitably introducing redundancy and even conflicts, and (2) depend on costly fine-tuning of MLLMs. In light of this, we propose TableDART, a training-efficient framework that integrates multimodal views by reusing pretrained single-modality models. TableDART introduces a lightweight 2.59M-parameter MLP gating network that dynamically selects the optimal path (either Text-only, Image-only, or Fusion) for each table-query pair, effectively reducing redundancy and conflicts from both modalities. In addition, we propose a novel agent to mediate cross-modal knowledge integration by analyzing outputs from text- and image-based models, either selecting the best result or synthesizing a new answer through reasoning. This design avoids the prohibitive costs of full MLLM fine-tuning. Extensive experiments on seven benchmarks show that TableDART establishes new state-of-the-art performance among open-source models, surpassing the strongest baseline by an average of 4.02%. The code is available at: https://anonymous.4open.science/r/TableDART-C52B