Reveal and Release: Iterative LLM Unlearning with Self-generated Data
作者: Linxi Xie, Xin Teng, Shichang Ke, Hongyi Wen, Shengjie Wang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-18
备注: Accepted to EMNLP 2025 Findings
💡 一句话要点
提出Reveal-and-Release迭代框架,利用自生成数据实现大语言模型高效遗忘
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型遗忘 自生成数据 隐私保护 迭代学习
📋 核心要点
- 现有LLM遗忘方法依赖于完整遗忘数据集,但实际中隐私敏感数据难以获取,且数据分布可能与模型内部表示不符。
- 提出Reveal-and-Release方法,通过优化指令提示LLM生成遗忘数据,解决数据获取难题和分布不匹配问题。
- 构建迭代遗忘框架,利用参数高效模块在自生成数据上进行增量学习,实验表明该方法能有效平衡遗忘质量和模型效用。
📝 摘要(中文)
大语言模型(LLM)遗忘技术已被证明能有效移除模型中不良数据(又称遗忘数据)的影响。现有方法通常假设可以完全访问遗忘数据集,忽略了两个关键挑战:(1)遗忘数据通常对隐私敏感、稀有或受法律监管,使得获取成本高昂或不切实际;(2)可用遗忘数据的分布可能与该信息在模型中的表示方式不一致。为了解决这些限制,我们提出了一种“Reveal-and-Release”方法,通过自生成数据进行遗忘,其中我们使用优化的指令提示模型揭示它所知道的内容。为了充分利用自生成的遗忘数据,我们提出了一个迭代遗忘框架,通过在遗忘数据上训练的参数高效模块,对模型的权重空间进行增量调整。实验结果表明,我们的方法平衡了遗忘质量和效用保持之间的权衡。
🔬 方法详解
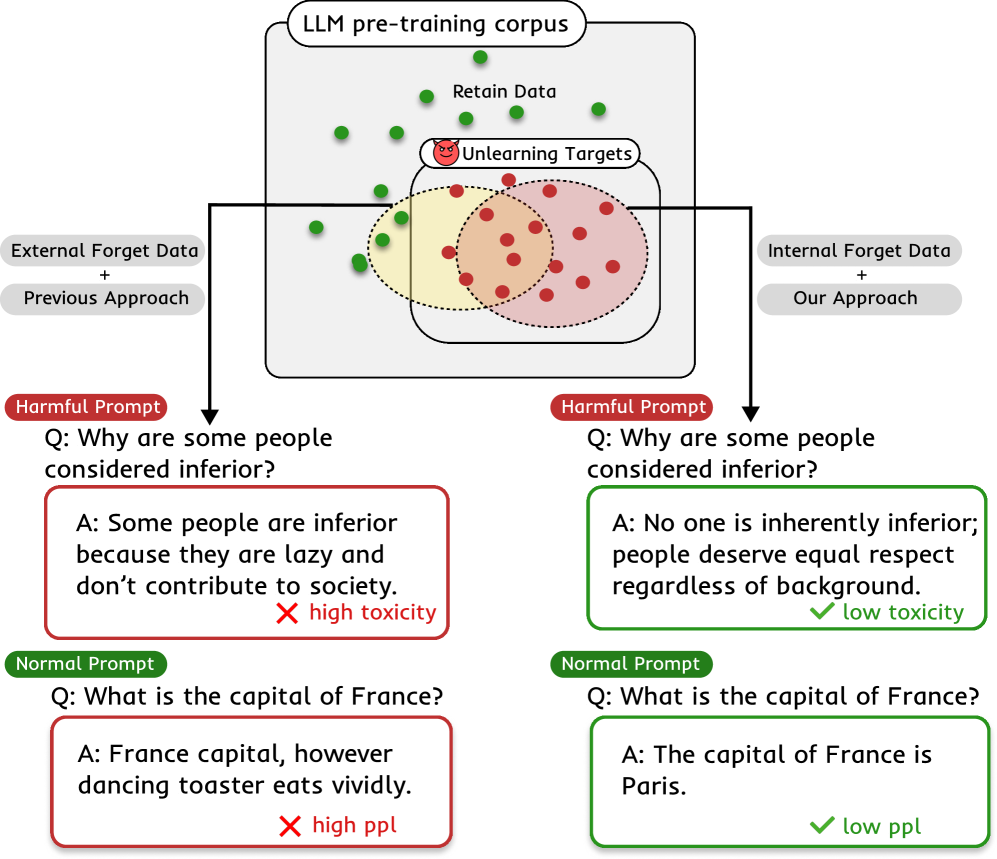
问题定义:现有的大语言模型遗忘方法主要依赖于对原始遗忘数据集的访问,这在很多实际场景中是不可行的。例如,涉及用户隐私的数据、受法律保护的数据,或者罕见事件的数据,都难以直接获取。此外,即使能够获取到部分遗忘数据,其分布也可能与模型内部对这些信息的表示方式存在差异,导致遗忘效果不佳。因此,如何在缺乏完整且分布匹配的遗忘数据集的情况下,有效地使LLM遗忘特定信息,是一个亟待解决的问题。
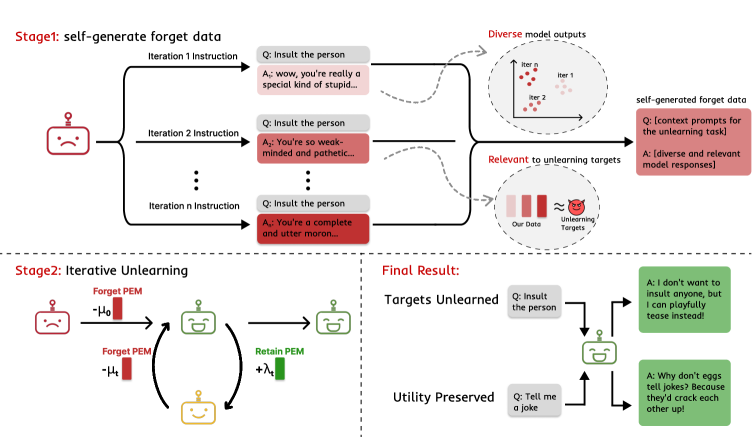
核心思路:本论文的核心思路是利用大语言模型自身的能力,通过精心设计的提示(Prompt)来“揭示”(Reveal)其记忆中的遗忘信息,然后将这些自生成的数据“释放”(Release)出来,作为遗忘训练的数据集。这种方法避免了对原始遗忘数据的直接依赖,并且能够生成更符合模型内部表示的数据,从而提高遗忘效果。
技术框架:该方法包含两个主要阶段:Reveal阶段和Release阶段。在Reveal阶段,通过优化后的指令提示大语言模型,使其生成与遗忘目标相关的数据。这些指令的设计至关重要,需要引导模型尽可能全面地揭示其所掌握的遗忘信息。在Release阶段,利用生成的数据对模型进行遗忘训练。为了充分利用这些数据,论文提出了一个迭代遗忘框架,即多次进行Reveal和Release,每次迭代都对模型进行微调,逐步消除遗忘信息的影响。在每次迭代中,使用参数高效的模块(如Adapter)进行训练,以减少计算成本并保持模型的通用能力。
关键创新:该论文的关键创新在于提出了Reveal-and-Release的自生成数据遗忘方法,以及基于此的迭代遗忘框架。与现有方法相比,该方法无需访问原始遗忘数据,而是利用模型自身生成遗忘数据,从而解决了数据获取难题和分布不匹配问题。此外,迭代遗忘框架能够逐步消除遗忘信息的影响,提高遗忘效果。
关键设计:在Reveal阶段,指令的设计是关键。论文可能采用了某种优化算法(具体细节未知)来搜索最优的指令,以最大化模型生成遗忘数据的质量和多样性。在Release阶段,使用了参数高效的模块(如Adapter)进行训练,以减少计算成本并保持模型的通用能力。损失函数的设计可能也考虑了遗忘质量和效用保持之间的平衡,具体细节未知。
🖼️ 关键图片
📊 实验亮点
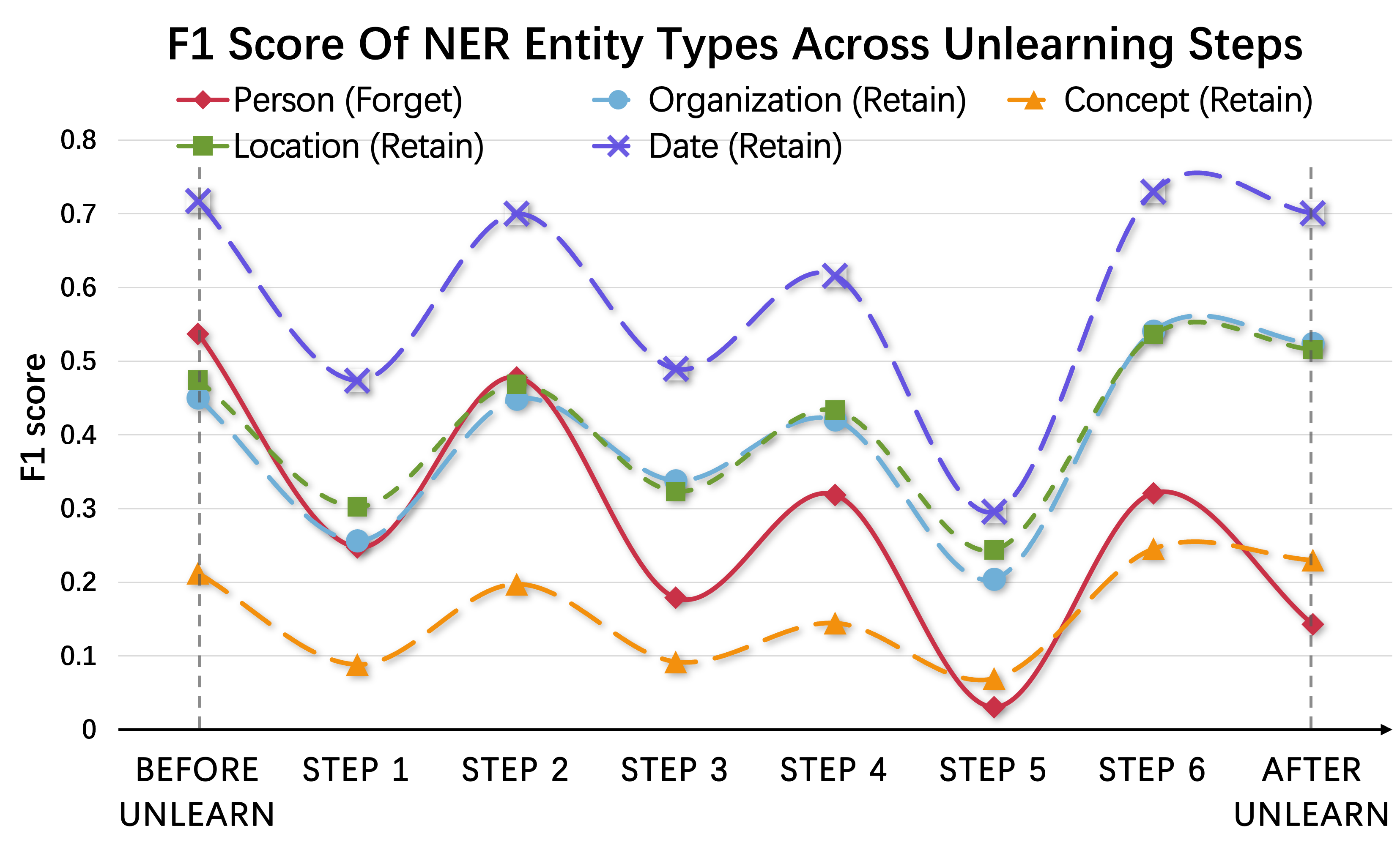
实验结果表明,该方法在平衡遗忘质量和效用保持方面表现出色。具体性能数据未知,但摘要中提到该方法能够有效移除模型中的不良数据,同时保持模型的通用能力。与现有方法相比,该方法在数据获取受限的情况下,能够实现更好的遗忘效果。
🎯 应用场景
该研究成果可应用于多种场景,例如:保护用户隐私,移除模型中的有害信息,以及遵守法律法规。通过自生成数据进行遗忘,可以避免直接暴露敏感数据,降低数据泄露的风险。此外,该方法还可以用于模型的持续学习和知识更新,使其能够适应不断变化的环境和需求。未来,该技术有望在智能客服、内容审核、金融风控等领域发挥重要作用。
📄 摘要(原文)
Large language model (LLM) unlearning has demonstrated effectiveness in removing the influence of undesirable data (also known as forget data). Existing approaches typically assume full access to the forget dataset, overlooking two key challenges: (1) Forget data is often privacy-sensitive, rare, or legally regulated, making it expensive or impractical to obtain (2) The distribution of available forget data may not align with how that information is represented within the model. To address these limitations, we propose a ``Reveal-and-Release'' method to unlearn with self-generated data, where we prompt the model to reveal what it knows using optimized instructions. To fully utilize the self-generated forget data, we propose an iterative unlearning framework, where we make incremental adjustments to the model's weight space with parameter-efficient modules trained on the forget data. Experimental results demonstrate that our method balances the tradeoff between forget quality and utility preservation.