ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
作者: Robert Tjarko Lange, Yuki Imajuku, Edoardo Cetin
分类: cs.CL, cs.LG
发布日期: 2025-09-17
备注: 52 pages, 14 figures
💡 一句话要点
ShinkaEvolve:提出一种高效、开源的程序演化框架,用于解决科学发现中的样本效率问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 程序演化 大型语言模型 科学发现 样本效率 开源框架
📋 核心要点
- 现有代码演化方法样本效率低,且多为闭源,限制了其在科学发现中的应用。
- ShinkaEvolve通过父代抽样、代码新颖性拒绝抽样和bandit LLM集成选择策略,提升样本效率。
- 实验表明,ShinkaEvolve在圆形packing、数学推理、竞争性编程等任务上均有显著提升。
📝 摘要(中文)
本文介绍ShinkaEvolve,一个全新的开源框架,它利用大型语言模型(LLM)以最先进的性能和前所未有的效率来推进科学发现。LLM推理计算的最新进展显著推动了广义科学发现。这些方法依赖于进化代理框架,利用LLM作为变异算子来生成候选解决方案。然而,当前的代码演化方法存在关键限制:样本效率低,需要数千个样本才能识别有效解决方案,并且仍然是闭源的,阻碍了广泛采用和扩展。ShinkaEvolve通过引入三个关键创新来解决这些限制:一种平衡探索和利用的父代抽样技术,用于高效搜索空间探索的代码新颖性拒绝抽样,以及一种基于bandit的LLM集成选择策略。我们在各种任务中评估ShinkaEvolve,证明了样本效率和解决方案质量的持续改进。ShinkaEvolve仅使用150个样本就发现了一种新的最先进的圆形 packing 解决方案,为 AIME 数学推理任务设计了高性能代理框架,识别了 ALE-Bench 竞争性编程解决方案的改进,并发现了新的混合专家负载平衡损失函数,从而阐明了优化策略的空间。我们的结果表明,ShinkaEvolve 具有广泛的适用性和卓越的样本效率。通过提供开源可访问性和成本效益,这项工作使跨各种计算问题的开放式发现民主化。
🔬 方法详解
问题定义:论文旨在解决程序演化中样本效率低下的问题。现有的基于LLM的代码演化方法通常需要大量的样本才能找到有效的解决方案,这限制了它们在计算资源有限或评估成本高的场景中的应用。此外,许多现有方法是闭源的,阻碍了研究人员的进一步改进和扩展。
核心思路:ShinkaEvolve的核心思路是通过更智能的搜索策略来提高样本的利用率。它不是简单地随机生成和评估大量的候选解决方案,而是通过平衡探索和利用、关注新颖性以及动态选择最佳的LLM变异算子,来更有效地探索搜索空间。
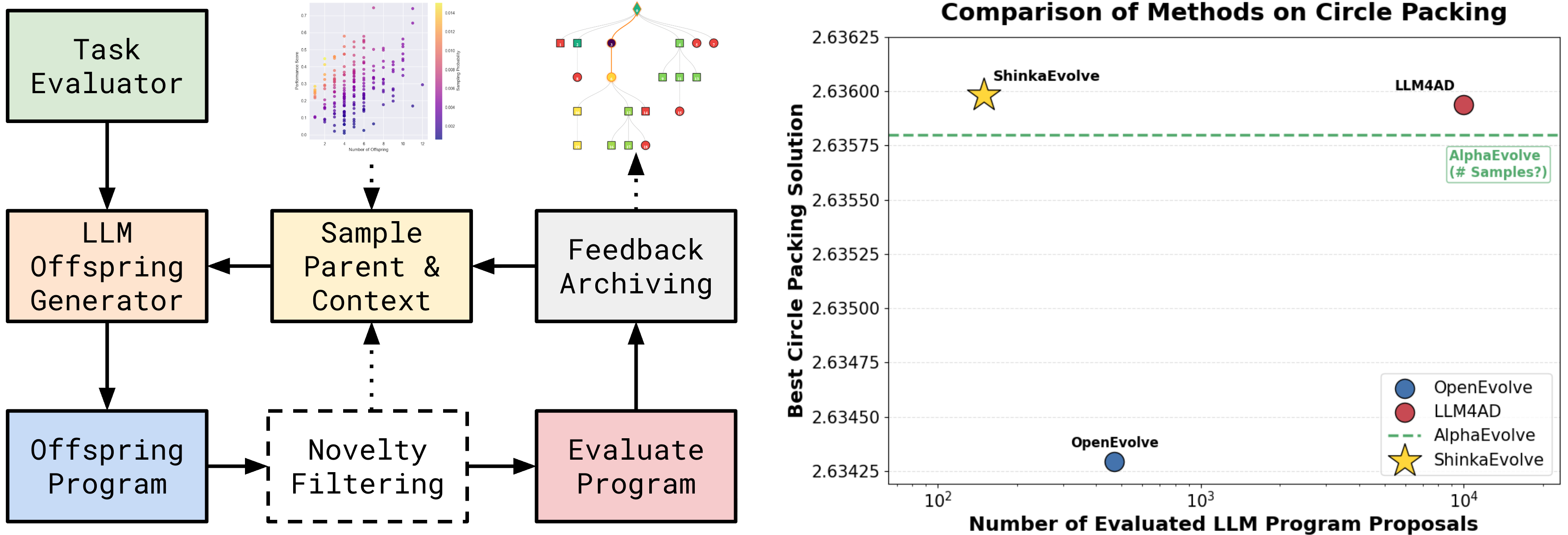
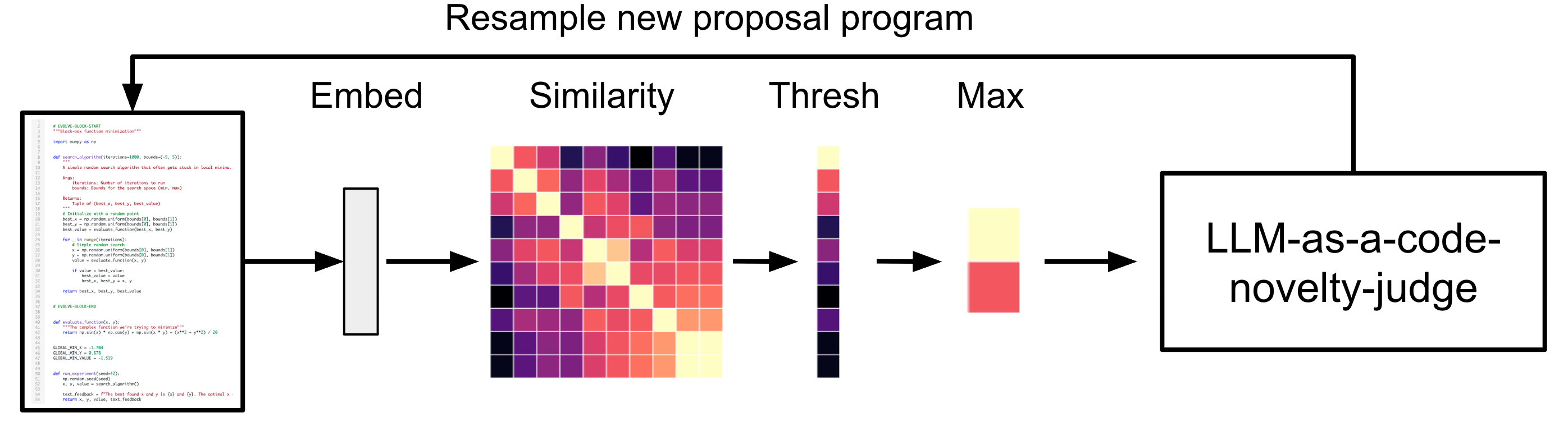
技术框架:ShinkaEvolve的整体框架包含以下几个主要模块:1) 父代抽样:根据一定的策略选择用于变异的父代程序,平衡探索(选择多样性高的父代)和利用(选择性能好的父代)。2) LLM变异:使用LLM作为变异算子,根据父代程序生成新的候选程序。3) 代码新颖性拒绝抽样:评估新生成的程序的代码新颖性,如果与已有的程序过于相似,则拒绝该样本,避免重复探索。4) 评估:评估新生成的程序的性能。5) Bandit LLM集成选择:维护一个LLM变异算子的集合,并使用bandit算法动态选择当前最优的LLM变异算子。
关键创新:ShinkaEvolve的关键创新在于其综合利用了多种策略来提高样本效率。代码新颖性拒绝抽样避免了对相似程序的重复评估,父代抽样策略平衡了探索和利用,而bandit LLM集成选择则允许根据任务的特点动态选择最合适的LLM变异算子。
关键设计:父代抽样策略使用了一种基于性能和多样性的加权选择方法。代码新颖性通过计算代码的哈希值或使用代码相似度度量来评估。Bandit LLM集成选择使用UCB(Upper Confidence Bound)算法来平衡探索和利用不同的LLM变异算子。具体参数设置(如UCB的探索系数)需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
ShinkaEvolve在多个任务上取得了显著的性能提升。例如,在圆形 packing 问题中,仅使用150个样本就找到了新的state-of-the-art解决方案。在AIME数学推理任务和ALE-Bench竞争性编程任务中,也发现了性能优于现有方法的解决方案。此外,ShinkaEvolve还发现了新的混合专家负载平衡损失函数。
🎯 应用场景
ShinkaEvolve可应用于各种科学发现和优化问题,例如新算法设计、自动化程序修复、药物发现、材料设计等。其高样本效率使其在计算资源受限或评估成本高的场景中具有优势。开源特性促进了社区参与和进一步发展,有望加速相关领域的研究进展。
📄 摘要(原文)
We introduce ShinkaEvolve: a new open-source framework leveraging large language models (LLMs) to advance scientific discovery with state-of-the-art performance and unprecedented efficiency. Recent advances in scaling inference time compute of LLMs have enabled significant progress in generalized scientific discovery. These approaches rely on evolutionary agentic harnesses that leverage LLMs as mutation operators to generate candidate solutions. However, current code evolution methods suffer from critical limitations: they are sample inefficient, requiring thousands of samples to identify effective solutions, and remain closed-source, hindering broad adoption and extension. ShinkaEvolve addresses these limitations, introducing three key innovations: a parent sampling technique balancing exploration and exploitation, code novelty rejection-sampling for efficient search space exploration, and a bandit-based LLM ensemble selection strategy. We evaluate ShinkaEvolve across diverse tasks, demonstrating consistent improvements in sample efficiency and solution quality. ShinkaEvolve discovers a new state-of-the-art circle packing solution using only 150 samples, designs high-performing agentic harnesses for AIME mathematical reasoning tasks, identifies improvements to ALE-Bench competitive programming solutions, and discovers novel mixture-of-expert load balancing loss functions that illuminate the space of optimization strategies. Our results demonstrate that ShinkaEvolve achieves broad applicability with exceptional sample efficiency. By providing open-source accessibility and cost-efficiency, this work democratizes open-ended discovery across diverse computational problems.