How Can Quantum Deep Learning Improve Large Language Models?
作者: Emily Jimin Roh, Hyojun Ahn, Samuel Yen-Chi Chen, Soohyun Park, Joongheon Kim
分类: quant-ph, cs.CL, cs.LG
发布日期: 2025-09-17
💡 一句话要点
探索量子深度学习在提升大型语言模型适应性方面的潜力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 参数高效微调 量子深度学习 量子幅度嵌入 参数化量子电路
📋 核心要点
- 现有大型语言模型微调方法面临计算和内存成本高昂的挑战,限制了其在资源受限场景下的应用。
- 论文探索利用量子深度学习中的量子幅度嵌入适应(QAA)框架,以期实现更高效的模型更新和适应。
- 论文通过系统综述和比较分析,揭示了传统PEFT方法与QAA在收敛性、效率和表征能力上的优劣。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展变革了自然语言处理领域,但高效适应性问题仍未解决。全量微调性能强大,但计算和内存成本过高。参数高效微调(PEFT)策略,如低秩适应(LoRA)、Prefix tuning和稀疏低秩适应(SoRA),通过减少可训练参数同时保持竞争性精度来解决这个问题。然而,这些方法在可扩展性、稳定性和跨任务泛化方面常常遇到限制。量子深度学习的最新进展通过量子启发编码和参数化量子电路(PQCs)引入了新的机会。特别是,量子幅度嵌入适应(QAA)框架展示了以最小开销进行表达性模型更新。本文对传统PEFT方法和QAA进行了系统的综述和比较分析。分析展示了收敛性、效率和表征能力之间的权衡,同时提供了量子方法在未来LLM适应中的潜力。
🔬 方法详解
问题定义:大型语言模型(LLMs)的微调面临着计算资源和内存消耗巨大的问题。全量微调虽然效果好,但成本过高,难以在实际应用中推广。参数高效微调(PEFT)方法旨在减少可训练参数,但往往在可扩展性、稳定性和泛化能力上存在不足。因此,如何以更低的成本实现LLM的高效适应是本文要解决的核心问题。
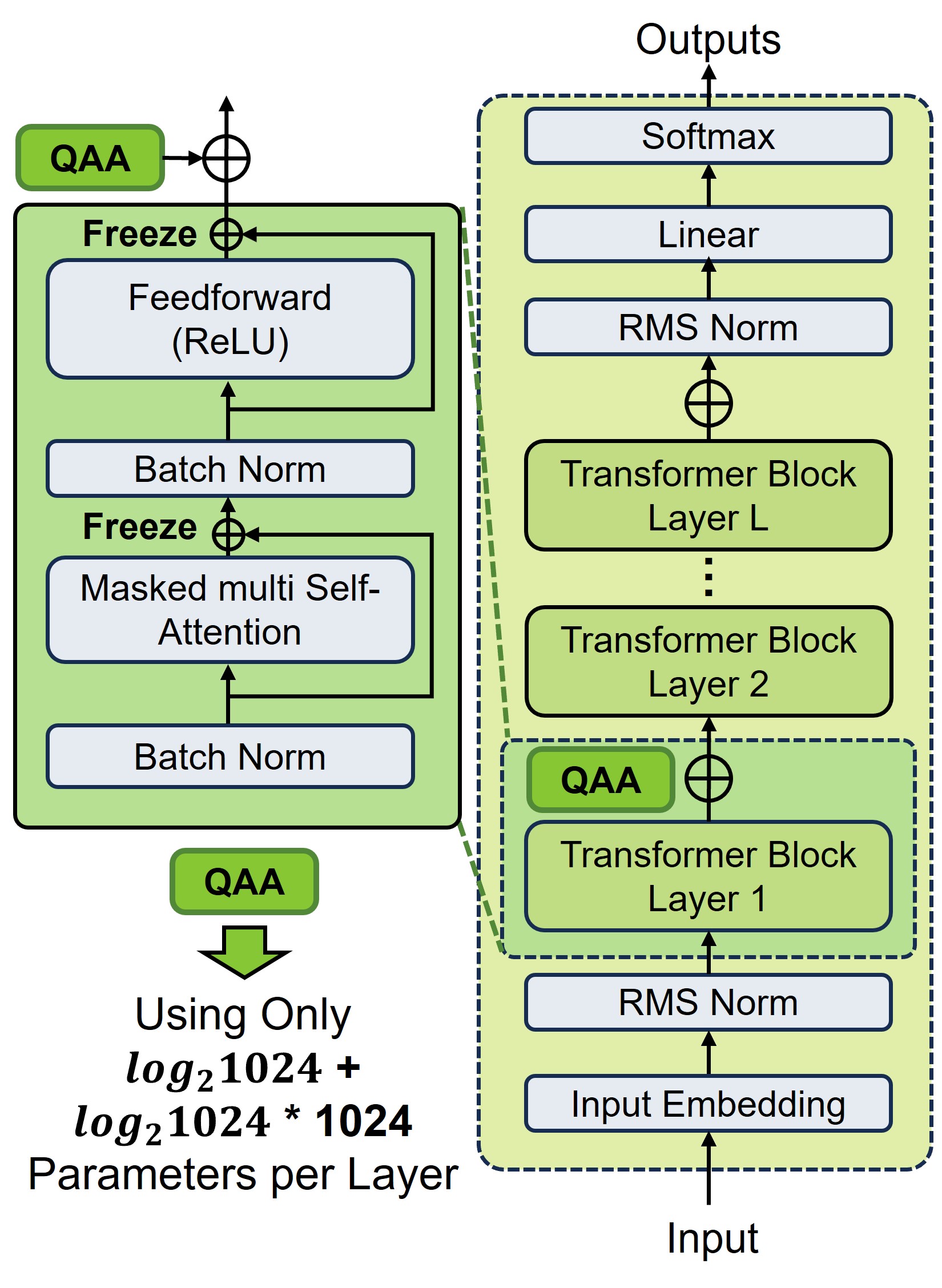
核心思路:本文的核心思路是探索量子深度学习在LLM微调中的应用潜力。具体而言,论文关注量子幅度嵌入适应(QAA)框架,该框架利用量子计算的特性,有望以更少的参数实现更具表达力的模型更新。通过将LLM的参数嵌入到量子态中,并利用参数化量子电路(PQC)进行变换,可以实现高效的参数更新和模型适应。
技术框架:论文采用系统综述和比较分析的方法,对传统PEFT方法和QAA框架进行对比研究。首先,论文回顾了现有的PEFT方法,包括LoRA、Prefix tuning和SoRA等,分析了它们的优缺点。然后,论文详细介绍了QAA框架的原理和实现方式,包括量子幅度嵌入、参数化量子电路的设计等。最后,论文通过实验对比了不同方法在LLM微调中的性能表现。
关键创新:论文的关键创新在于探索了量子深度学习在LLM微调中的应用,并提出了利用QAA框架实现高效模型适应的思路。与传统PEFT方法相比,QAA框架有望利用量子计算的优势,以更少的参数实现更强大的表征能力和更好的泛化性能。
关键设计:QAA框架的关键设计包括:1) 如何将LLM的参数有效地嵌入到量子态中;2) 如何设计参数化量子电路(PQC)以实现高效的参数更新;3) 如何优化量子电路的结构和参数,以提高模型的性能。此外,论文还可能涉及到一些与量子计算相关的技术细节,例如量子门的选取、量子态的测量等。
🖼️ 关键图片

📊 实验亮点
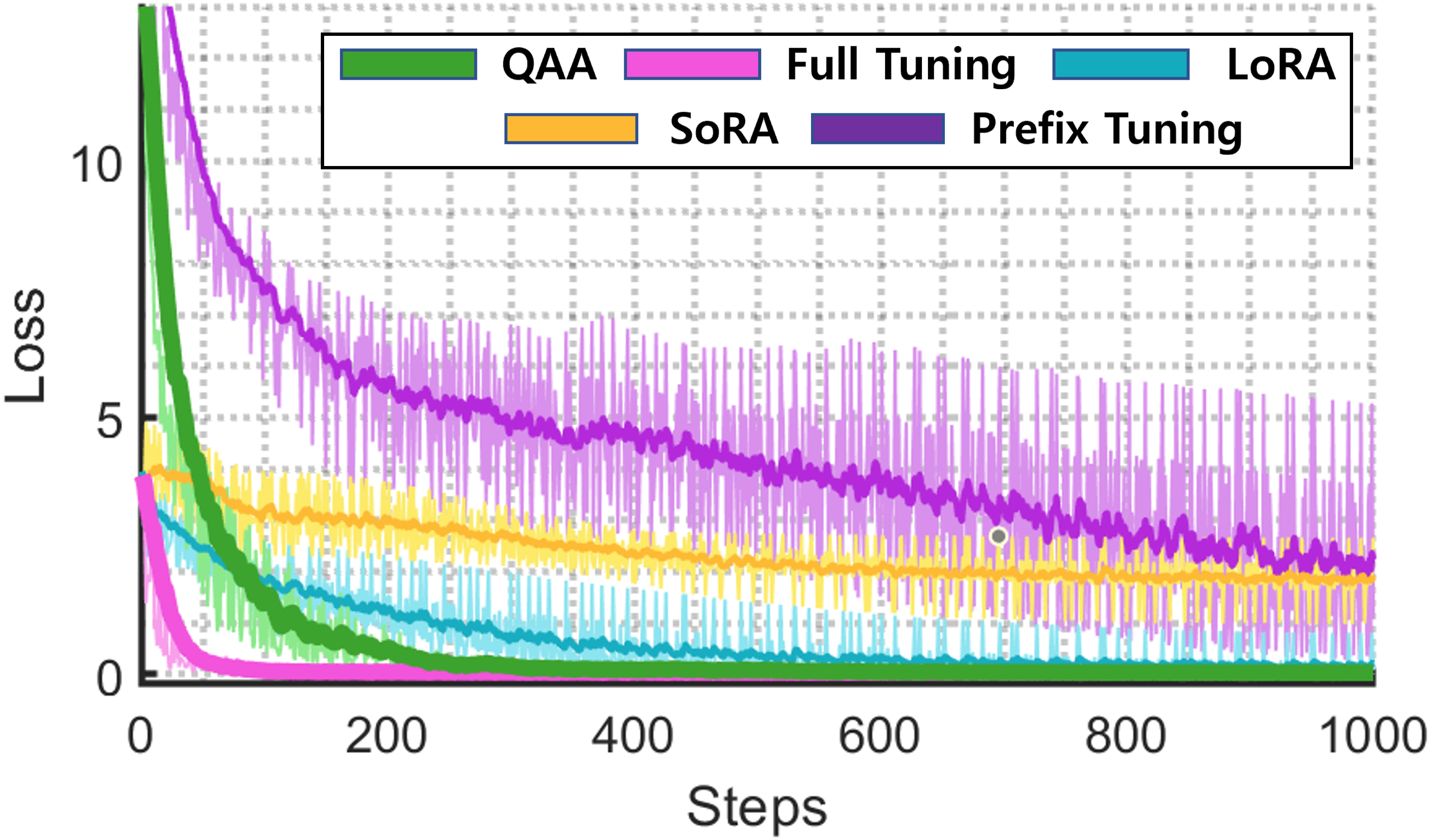
论文通过对比分析,展示了QAA框架在LLM微调中的潜力。虽然具体性能数据未知,但论文强调了QAA在收敛性、效率和表征能力方面的优势。与传统PEFT方法相比,QAA有望以更少的参数实现更强大的模型更新,从而提高LLM的适应性和泛化能力。未来的实验将进一步验证QAA的有效性。
🎯 应用场景
该研究成果潜在的应用领域包括自然语言处理、智能客服、机器翻译等。通过利用量子深度学习技术,可以降低大型语言模型的部署和微调成本,使其能够在资源受限的设备上运行,从而推动人工智能技术的普及。未来,该研究有望为开发更高效、更智能的自然语言处理系统提供新的思路。
📄 摘要(原文)
The rapid progress of large language models (LLMs) has transformed natural language processing, yet the challenge of efficient adaptation remains unresolved. Full fine-tuning achieves strong performance but imposes prohibitive computational and memory costs. Parameter-efficient fine-tuning (PEFT) strategies, such as low-rank adaptation (LoRA), Prefix tuning, and sparse low-rank adaptation (SoRA), address this issue by reducing trainable parameters while maintaining competitive accuracy. However, these methods often encounter limitations in scalability, stability, and generalization across diverse tasks. Recent advances in quantum deep learning introduce novel opportunities through quantum-inspired encoding and parameterized quantum circuits (PQCs). In particular, the quantum-amplitude embedded adaptation (QAA) framework demonstrates expressive model updates with minimal overhead. This paper presents a systematic survey and comparative analysis of conventional PEFT methods and QAA. The analysis demonstrates trade-offs in convergence, efficiency, and representational capacity, while providing insight into the potential of quantum approaches for future LLM adaptation.