Correct-Detect: Balancing Performance and Ambiguity Through the Lens of Coreference Resolution in LLMs
作者: Amber Shore, Russell Scheinberg, Ameeta Agrawal, So Young Lee
分类: cs.CL, cs.AI
发布日期: 2025-09-17 (更新: 2025-10-21)
备注: Accepted at EMNLP 2025 (main)
💡 一句话要点
揭示LLM在共指消解中性能与歧义检测的权衡:Correct-Detect 框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 共指消解 歧义检测 自然语言理解 性能权衡
📋 核心要点
- 大型语言模型在处理共指消解任务时,面临着性能与歧义检测之间的内在冲突。
- 论文提出Correct-Detect框架,旨在研究和揭示LLM在共指消解中性能和歧义检测之间的权衡关系。
- 实验表明,LLM虽然具备共指消歧和歧义检测能力,但难以同时优化两者,存在性能瓶颈。
📝 摘要(中文)
大型语言模型(LLM)旨在反映人类的语言能力。但人类可以获取广泛且具象的上下文,这对于检测和解决语言歧义至关重要,即使在孤立的文本片段中也是如此。共指消解任务中存在一种基本的语义歧义:代词与先前提到的人之间的关系是什么?这种能力几乎隐含在每个下游任务中,并且此级别的歧义的存在会显着改变性能。我们表明,LLM可以通过最少的提示在共指消歧和共指歧义检测方面都取得良好的性能,但是,它们不能同时做到这两点。我们提出了 CORRECT-DETECT 权衡:尽管模型同时具有这两种能力并隐式地部署它们,但成功地平衡这两种能力仍然难以捉摸。
🔬 方法详解
问题定义:论文关注大型语言模型(LLM)在共指消解任务中的表现,特别是模型在性能(正确消解共指)和歧义检测(识别共指关系中的不确定性)之间的权衡。现有方法通常侧重于提高共指消解的准确性,而忽略了模型识别和处理歧义的能力,这可能导致模型在面对复杂或模糊的语言环境时表现不佳。
核心思路:论文的核心思路是揭示LLM在共指消解任务中,正确消解共指关系(Correct)和检测共指关系中的歧义(Detect)之间存在一种内在的权衡关系。模型在优化其中一个目标时,往往会牺牲另一个目标的性能。这种权衡反映了人类在处理语言歧义时的认知过程,即在理解文本时,需要同时考虑多种可能的解释,并根据上下文选择最合理的解释。
技术框架:论文没有提出一个全新的技术框架,而是通过实验分析来研究LLM在共指消解任务中的表现。实验流程主要包括:1) 构建包含歧义共指关系的测试数据集;2) 使用不同的提示策略来引导LLM进行共指消解和歧义检测;3) 评估LLM在两个任务上的性能,并分析它们之间的关系。
关键创新:论文的关键创新在于发现了LLM在共指消解任务中存在的“CORRECT-DETECT”权衡现象。这表明,即使LLM具有强大的语言理解能力,它们在处理歧义时仍然面临挑战。与现有方法不同,论文没有试图提高共指消解的准确性,而是关注模型在处理歧义时的行为,并揭示了模型在性能和歧义检测之间的内在冲突。
关键设计:论文的关键设计在于精心设计的实验和评估指标。通过构建包含不同类型歧义的测试数据集,并使用不同的提示策略,论文能够系统地评估LLM在共指消解和歧义检测方面的能力。此外,论文还设计了专门的评估指标来衡量模型在两个任务上的性能,从而能够定量地分析它们之间的权衡关系。
🖼️ 关键图片

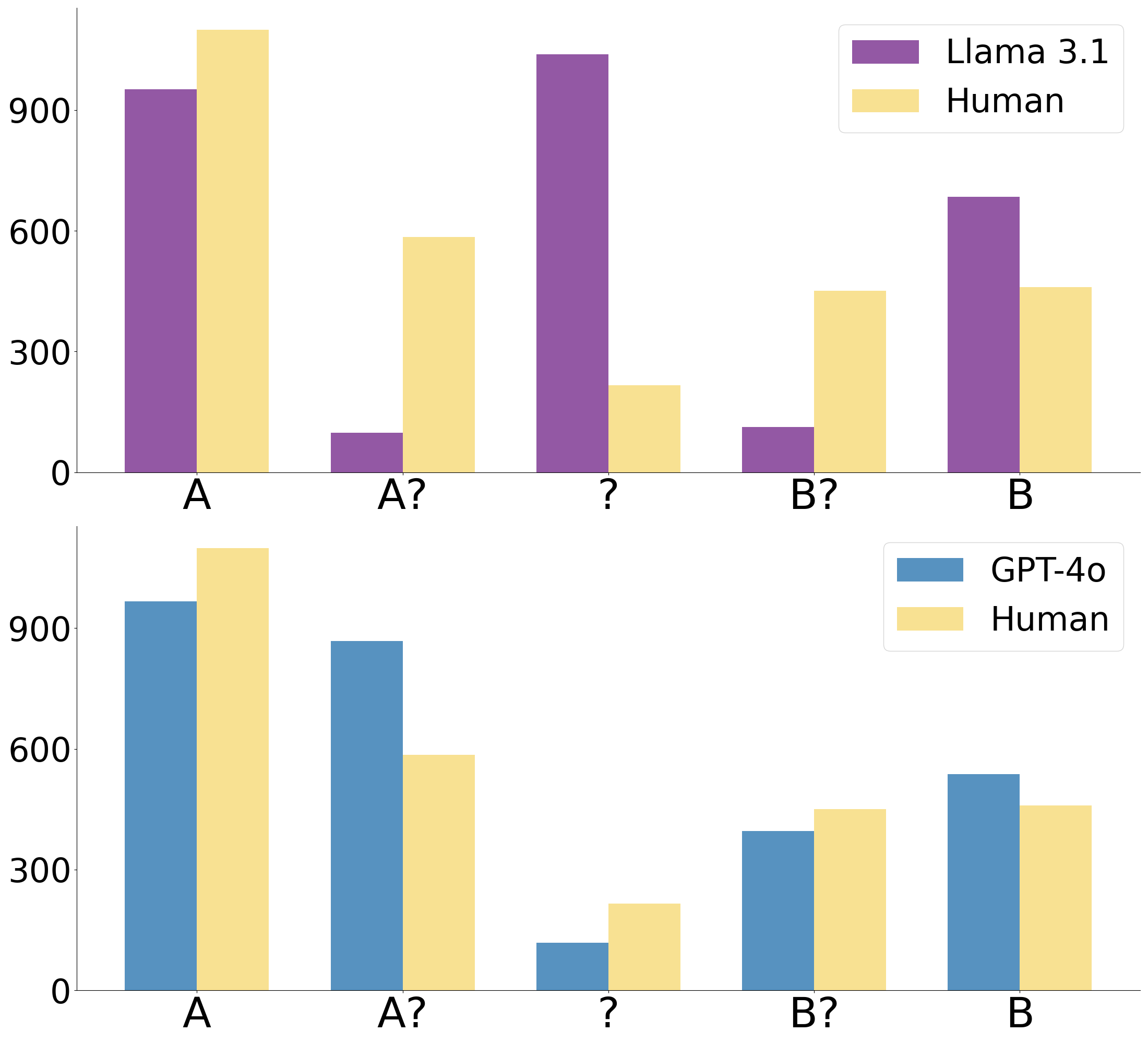
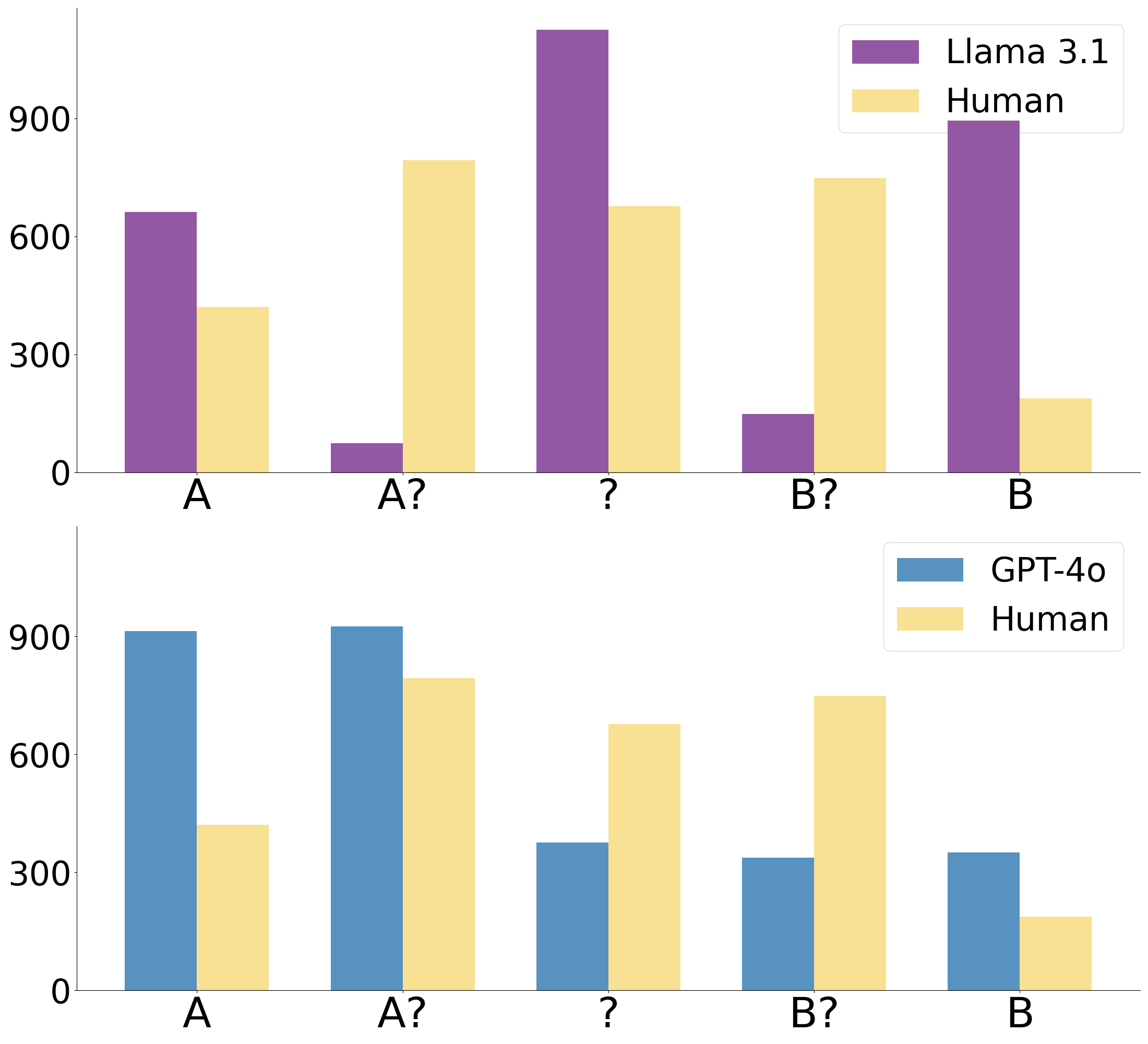
📊 实验亮点
论文通过实验证明,LLM在共指消解任务中存在性能与歧义检测的权衡。虽然模型在单独执行共指消歧或歧义检测时表现良好,但同时优化两者仍然具有挑战性。这一发现为未来研究LLM在处理语言歧义方面的能力提供了新的视角。
🎯 应用场景
该研究成果可应用于提升LLM在自然语言理解和生成任务中的鲁棒性和可靠性。通过更好地理解和解决LLM在处理歧义时的局限性,可以开发更智能、更人性化的AI系统,例如在对话系统中,能够更准确地理解用户的意图,并生成更自然、更清晰的回复。此外,该研究还可以促进对人类语言认知过程的理解。
📄 摘要(原文)
Large Language Models (LLMs) are intended to reflect human linguistic competencies. But humans have access to a broad and embodied context, which is key in detecting and resolving linguistic ambiguities, even in isolated text spans. A foundational case of semantic ambiguity is found in the task of coreference resolution: how is a pronoun related to an earlier person mention? This capability is implicit in nearly every downstream task, and the presence of ambiguity at this level can alter performance significantly. We show that LLMs can achieve good performance with minimal prompting in both coreference disambiguation and the detection of ambiguity in coreference, however, they cannot do both at the same time. We present the CORRECT-DETECT trade-off: though models have both capabilities and deploy them implicitly, successful performance balancing these two abilities remains elusive.