AssoCiAm: A Benchmark for Evaluating Association Thinking while Circumventing Ambiguity
作者: Yifan Liu, Wenkuan Zhao, Shanshan Zhong, Jinghui Qin, Mingfu Liang, Zhongzhan Huang, Wushao Wen
分类: cs.CL
发布日期: 2025-09-17 (更新: 2025-09-18)
备注: Accepted by EMNLP 2025 main track
💡 一句话要点
AssoCiAm:提出一个用于评估联想思维并规避歧义的基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联想思维 多模态大语言模型 基准测试 歧义规避 创造力评估
📋 核心要点
- 现有联想能力评估框架忽略了联想任务中固有的歧义性,导致评估结果的可靠性降低。
- 论文提出AssoCiAm基准,通过混合计算方法规避内部和外部歧义,从而更准确地评估联想能力。
- 实验表明,认知能力与联想能力之间存在正相关,且歧义会使MLLM的行为更具随机性,验证了方法有效性。
📝 摘要(中文)
多模态大型语言模型(MLLM)的最新进展备受关注,为实现通用人工智能(AGI)提供了一条有希望的途径。在AGI所需的关键能力中,创造力已成为MLLM的一项重要特征,而联想是其基础。联想反映了模型进行创造性思考的能力,因此评估和理解联想能力至关重要。虽然已经提出了几个评估联想能力的框架,但它们通常忽略了联想任务中固有的歧义,这种歧义源于联想的发散性,并损害了评估的可靠性。为了解决这个问题,我们将歧义分解为两种类型——内部歧义和外部歧义——并引入AssoCiAm,这是一个旨在评估联想能力,同时通过混合计算方法规避歧义的基准。然后,我们对MLLM进行了广泛的实验,揭示了认知和联想之间存在很强的正相关关系。此外,我们观察到评估过程中歧义的存在会导致MLLM的行为变得更加随机。最后,我们验证了我们的方法在确保更准确和可靠的评估方面的有效性。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)联想能力评估中存在的歧义性问题。现有的评估框架未能充分考虑联想任务中固有的歧义,导致评估结果不够可靠,无法准确反映模型的真实联想能力。这种歧义主要体现在两个方面:内部歧义(联想本身的多样性)和外部歧义(评估标准的不明确)。
核心思路:论文的核心思路是通过设计一个能够规避歧义的基准(AssoCiAm),从而实现对MLLM联想能力的更准确评估。具体而言,该基准采用混合计算方法,结合了人工设计的规则和自动化的评估流程,以减少歧义对评估结果的影响。通过控制歧义变量,可以更清晰地观察和分析MLLM的联想行为。
技术框架:AssoCiAm基准的整体框架包含以下几个主要模块:1) 歧义分解模块:将歧义分解为内部歧义和外部歧义,并针对不同类型的歧义设计相应的规避策略。2) 混合计算模块:结合人工设计的规则和自动化的评估流程,以减少歧义对评估结果的影响。3) 评估指标模块:设计了一系列评估指标,用于衡量MLLM的联想能力,同时考虑了歧义的影响。4) 实验验证模块:通过对多个MLLM进行实验,验证AssoCiAm基准的有效性和可靠性。
关键创新:该论文最重要的技术创新点在于提出了一个能够规避歧义的联想能力评估基准。与现有方法相比,AssoCiAm更加注重对歧义的控制,从而能够更准确地评估MLLM的联想能力。此外,该论文还提出了歧义分解的概念,并针对不同类型的歧义设计了相应的规避策略,为联想能力评估领域的研究提供了新的思路。
关键设计:AssoCiAm基准的关键设计包括:1) 歧义控制策略:针对内部歧义,采用人工设计的规则来限制联想的范围;针对外部歧义,采用自动化的评估流程来减少评估标准的不确定性。2) 评估指标设计:设计了一系列评估指标,包括联想的流畅性、独特性和相关性等,并对这些指标进行加权,以反映不同方面的联想能力。3) 数据集构建:构建了一个包含多种类型联想任务的数据集,用于评估MLLM在不同场景下的联想能力。
🖼️ 关键图片


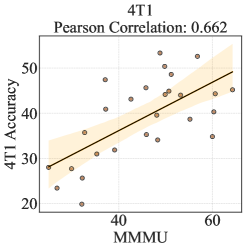
📊 实验亮点
实验结果表明,使用AssoCiAm基准评估时,认知能力与联想能力之间存在显著的正相关关系。同时,实验还发现,在存在歧义的评估环境中,MLLM的行为更趋向于随机性。这些结果验证了AssoCiAm基准在规避歧义、提高评估准确性方面的有效性。项目主页提供了数据和代码。
🎯 应用场景
该研究成果可应用于多模态大型语言模型的创造力评估、智能对话系统、内容生成、以及辅助创意设计等领域。通过更准确地评估模型的联想能力,可以提升模型在这些应用中的表现,并推动通用人工智能的发展。未来,该研究可以扩展到其他认知能力的评估,为构建更智能、更可靠的人工智能系统提供支持。
📄 摘要(原文)
Recent advancements in multimodal large language models (MLLMs) have garnered significant attention, offering a promising pathway toward artificial general intelligence (AGI). Among the essential capabilities required for AGI, creativity has emerged as a critical trait for MLLMs, with association serving as its foundation. Association reflects a model' s ability to think creatively, making it vital to evaluate and understand. While several frameworks have been proposed to assess associative ability, they often overlook the inherent ambiguity in association tasks, which arises from the divergent nature of associations and undermines the reliability of evaluations. To address this issue, we decompose ambiguity into two types-internal ambiguity and external ambiguity-and introduce AssoCiAm, a benchmark designed to evaluate associative ability while circumventing the ambiguity through a hybrid computational method. We then conduct extensive experiments on MLLMs, revealing a strong positive correlation between cognition and association. Additionally, we observe that the presence of ambiguity in the evaluation process causes MLLMs' behavior to become more random-like. Finally, we validate the effectiveness of our method in ensuring more accurate and reliable evaluations. See Project Page for the data and codes.