DSPC: Dual-Stage Progressive Compression Framework for Efficient Long-Context Reasoning
作者: Yaxin Gao, Yao Lu, Zongfei Zhang, Jiaqi Nie, Shanqing Yu, Qi Xuan
分类: cs.CL
发布日期: 2025-09-17 (更新: 2025-09-18)
💡 一句话要点
提出DSPC双阶段渐进压缩框架,无需训练即可高效压缩长文本上下文。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本压缩 提示压缩 免训练 双阶段压缩 语言模型 TF-IDF 注意力机制
📋 核心要点
- 现有长文本压缩方法依赖于训练辅助模型,引入了额外的计算负担,限制了其应用。
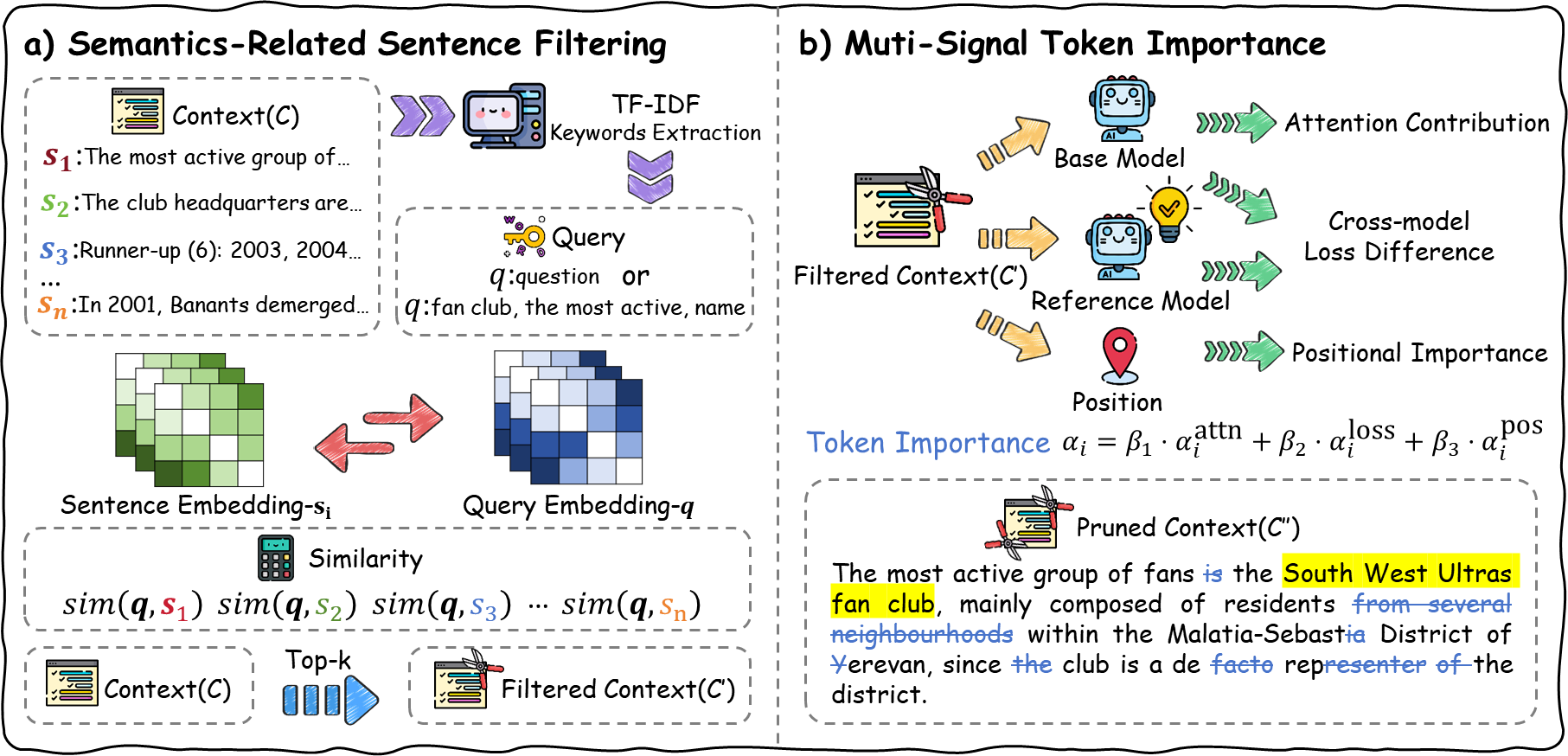
- DSPC框架通过粗粒度的句子过滤和细粒度的token修剪,在不训练的情况下实现高效压缩。
- 实验表明,DSPC在长文本任务中,显著优于现有方法,同时降低了计算成本。
📝 摘要(中文)
大型语言模型(LLMs)在许多自然语言处理(NLP)任务中取得了显著成功。为了获得更准确的输出,驱动LLM的提示变得越来越长,导致更高的计算成本。为了解决这个提示膨胀问题,提出了提示压缩。然而,大多数现有方法需要训练一个小型辅助模型进行压缩,从而产生大量的额外计算。为了避免这种情况,我们提出了一种两阶段、免训练的方法,称为双阶段渐进压缩(DSPC)。在粗粒度阶段,语义相关的句子过滤基于TF-IDF删除语义价值低的句子。在细粒度阶段,使用注意力贡献、跨模型损失差异和位置重要性来评估token重要性,从而能够在保留语义的同时修剪低效用的token。我们在LLaMA-3.1-8B-Instruct和GPT-3.5-Turbo上,在受限的token预算下验证了DSPC,并观察到了一致的改进。例如,在Longbench数据集的FewShot任务中,DSPC仅使用少3倍的token就实现了49.17的性能,优于最佳的state-of-the-art基线LongLLMLingua 7.76。
🔬 方法详解
问题定义:论文旨在解决大型语言模型处理长文本时,由于提示过长导致的计算成本高昂问题。现有提示压缩方法通常需要训练额外的辅助模型,增加了计算负担,并且可能引入额外的误差。这些方法在实际应用中存在一定的局限性。
核心思路:论文的核心思路是提出一种无需训练的、双阶段渐进压缩框架DSPC。该框架通过粗粒度的句子过滤和细粒度的token修剪,逐步减少输入文本的长度,同时尽可能保留关键语义信息,从而降低计算成本。
技术框架:DSPC框架包含两个主要阶段:粗粒度句子过滤和细粒度token修剪。在粗粒度阶段,使用TF-IDF算法评估每个句子的语义价值,并移除语义价值低的句子。在细粒度阶段,通过注意力贡献、跨模型损失差异和位置重要性等指标评估每个token的重要性,并修剪重要性低的token。这两个阶段协同工作,逐步压缩输入文本。
关键创新:DSPC的关键创新在于其免训练的特性。与需要训练辅助模型的现有方法不同,DSPC直接利用预训练语言模型的现有知识,通过简单的计算和评估来确定句子和token的重要性,从而避免了额外的训练成本和潜在的误差。此外,双阶段渐进压缩策略能够更有效地保留关键语义信息。
关键设计:在粗粒度阶段,TF-IDF阈值的选择会影响句子过滤的程度。在细粒度阶段,注意力贡献、跨模型损失差异和位置重要性这三个指标的权重需要根据具体任务进行调整。论文中可能还涉及一些超参数的设置,例如token修剪的比例等。这些参数的选择会影响压缩效果和性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DSPC在Longbench数据集的FewShot任务中,仅使用少3倍的token就实现了49.17的性能,优于最佳的state-of-the-art基线LongLLMLingua 7.76。这表明DSPC在压缩长文本的同时,能够有效地保留关键语义信息,从而提高模型的性能。此外,DSPC在LLaMA-3.1-8B-Instruct和GPT-3.5-Turbo上都取得了显著的改进,验证了其通用性和有效性。
🎯 应用场景
DSPC框架可应用于各种需要处理长文本输入的场景,例如长文档摘要、问答系统、信息检索等。通过降低输入文本的长度,DSPC可以显著降低计算成本,提高处理效率,使得大型语言模型能够更好地应用于资源受限的环境中。该研究对于推动大型语言模型在实际应用中的普及具有重要意义。
📄 摘要(原文)
Large language models (LLMs) have achieved remarkable success in many natural language processing (NLP) tasks. To achieve more accurate output, the prompts used to drive LLMs have become increasingly longer, which incurs higher computational costs. To address this prompt inflation problem, prompt compression has been proposed. However, most existing methods require training a small auxiliary model for compression, incurring a significant amount of additional computation. To avoid this, we propose a two-stage, training-free approach, called Dual-Stage Progressive Compression (DSPC). In the coarse-grained stage, semantic-related sentence filtering removes sentences with low semantic value based on TF-IDF. In the fine-grained stage, token importance is assessed using attention contribution, cross-model loss difference, and positional importance, enabling the pruning of low-utility tokens while preserving semantics. We validate DSPC on LLaMA-3.1-8B-Instruct and GPT-3.5-Turbo under a constrained token budget and observe consistent improvements. For instance, in the FewShot task of the Longbench dataset, DSPC achieves a performance of 49.17 by using only 3x fewer tokens, outperforming the best state-of-the-art baseline LongLLMLingua by 7.76.