Continually Adding New Languages to Multilingual Language Models
作者: Abraham Toluwase Owodunni, Sachin Kumar
分类: cs.CL
发布日期: 2025-09-14
💡 一句话要点
提出Layer-Selective LoRA,用于多语言模型持续添加新语言,避免灾难性遗忘。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 持续学习 低秩适配器 灾难性遗忘 模型适配 层选择 指令遵循 模型算术
📋 核心要点
- 现有方法在多语言模型中添加新语言时,需要从头重新训练,成本高昂且面临数据不可得的问题。
- LayRA通过在模型的特定层(初始层和最终层)引入LoRA适配器,有效减少了灾难性遗忘,同时学习新语言。
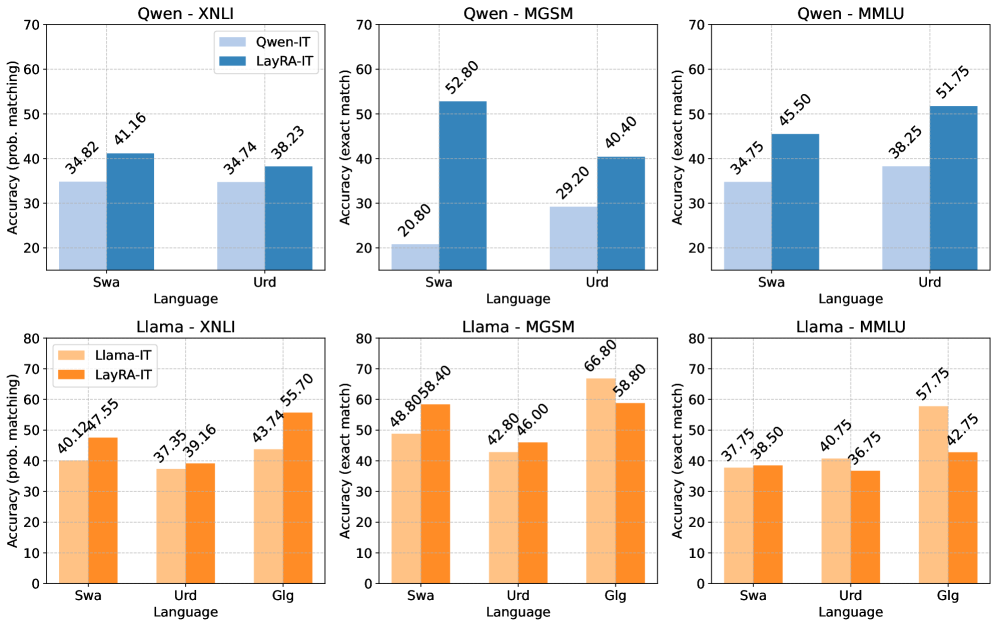
- 实验表明,LayRA在保持原有语言能力的同时,学习新语言的能力与LoRA相当,且无需目标语言的指令调优数据。
📝 摘要(中文)
多语言模型通常在固定的语言集上训练,为了支持新语言,需要从头开始重新训练模型,这既昂贵又不可行,因为模型开发者通常不会发布其预训练数据。直接进行持续预训练等朴素方法会遭受灾难性遗忘;然而,由于缺乏原始预训练数据,像经验回放这样的缓解策略无法应用。本文研究了在仅能访问目标语言的预训练数据的情况下,如何持续地向多语言模型添加新语言。我们探索了解决该问题的多种方法,并提出了层选择LoRA(LayRA),它将低秩适配器(LoRA)添加到选定的初始层和最终层,同时保持模型的其余部分冻结。LayRA基于两个洞察:(1) LoRA减少了遗忘,(2) 多语言模型在初始层中编码源语言的输入,在中间层中用英语进行推理,并在最终层中翻译回源语言。我们通过向预训练语言模型添加加利西亚语、斯瓦希里语和乌尔都语的多种组合来进行实验,并在各种多语言任务上评估每种方法。我们发现LayRA在保持模型在先前支持的语言中的能力方面提供了最佳的权衡,同时在学习新语言方面与现有的LoRA等方法具有竞争力。我们还证明,使用模型算术,经过适配的模型可以具备强大的指令遵循能力,而无需访问目标语言的任何指令调优数据。
🔬 方法详解
问题定义:论文旨在解决多语言模型在不进行完全重新训练的情况下,如何持续添加新语言的问题。现有方法,如直接持续预训练,会导致灾难性遗忘,即模型在学习新语言时会忘记之前学习的语言。此外,由于原始预训练数据通常不可用,传统的缓解灾难性遗忘的策略(如经验回放)也无法应用。
核心思路:论文的核心思路是利用LoRA(Low-Rank Adapters)来减少灾难性遗忘,并结合多语言模型内部的语言处理机制,选择性地在模型的特定层应用LoRA。作者观察到多语言模型在初始层编码源语言,中间层用英语推理,最终层翻译回源语言,因此只在初始层和最终层添加LoRA。
技术框架:LayRA方法的核心框架是在预训练的多语言模型基础上,冻结大部分模型参数,仅在选定的初始层和最终层添加LoRA适配器。具体流程包括:1) 选择目标语言的预训练数据;2) 在模型的初始层和最终层添加LoRA适配器;3) 使用目标语言的预训练数据训练LoRA适配器;4) 评估模型在原有语言和新语言上的性能。
关键创新:LayRA的关键创新在于“层选择”策略。与在所有层或随机层添加LoRA不同,LayRA基于对多语言模型内部运作机制的理解,有选择性地在初始层和最终层添加LoRA。这种策略能够更有效地学习新语言,同时减少对原有语言能力的干扰。
关键设计:LayRA的关键设计包括:1) LoRA的秩(rank)的选择,需要根据具体任务和数据集进行调整;2) 初始层和最终层的具体层数选择,需要根据模型的结构和大小进行调整;3) 使用模型算术,将适配后的模型与原始模型进行融合,以增强指令遵循能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LayRA在添加加利西亚语、斯瓦希里语和乌尔都语等新语言时,能够在保持原有语言能力的同时,达到与LoRA相当的新语言学习性能。更重要的是,LayRA无需目标语言的指令调优数据,即可通过模型算术赋予模型强大的指令遵循能力,这大大降低了模型适配的成本。
🎯 应用场景
该研究成果可应用于需要不断扩展语言支持的机器翻译、跨语言信息检索、多语言对话系统等领域。通过LayRA,开发者可以更高效地为现有模型添加新语言,降低模型更新的成本,并快速适应新的语言需求。此外,该方法在资源受限的场景下具有重要意义,例如在缺乏大规模多语言预训练数据的情况下,可以利用少量目标语言数据来扩展模型能力。
📄 摘要(原文)
Multilingual language models are trained on a fixed set of languages, and to support new languages, the models need to be retrained from scratch. This is an expensive endeavor and is often infeasible, as model developers tend not to release their pre-training data. Naive approaches, such as continued pretraining, suffer from catastrophic forgetting; however, mitigation strategies like experience replay cannot be applied due to the lack of original pretraining data. In this work, we investigate the problem of continually adding new languages to a multilingual model, assuming access to pretraining data in only the target languages. We explore multiple approaches to address this problem and propose Layer-Selective LoRA (LayRA), which adds Low-Rank Adapters (LoRA) to selected initial and final layers while keeping the rest of the model frozen. LayRA builds on two insights: (1) LoRA reduces forgetting, and (2) multilingual models encode inputs in the source language in the initial layers, reason in English in intermediate layers, and translate back to the source language in final layers. We experiment with adding multiple combinations of Galician, Swahili, and Urdu to pretrained language models and evaluate each method on diverse multilingual tasks. We find that LayRA provides the overall best tradeoff between preserving models' capabilities in previously supported languages, while being competitive with existing approaches such as LoRA in learning new languages. We also demonstrate that using model arithmetic, the adapted models can be equipped with strong instruction following abilities without access to any instruction tuning data in the target languages.