Transformer Enhanced Relation Classification: A Comparative Analysis of Contextuality, Data Efficiency and Sequence Complexity
作者: Bowen Jing, Yang Cui, Tianpeng Huang
分类: cs.CL, cs.AI
发布日期: 2025-09-14
💡 一句话要点
对比Transformer与非Transformer模型在关系分类任务中的性能差异。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 关系分类 Transformer模型 非Transformer模型 信息抽取 深度学习
📋 核心要点
- 现有关系分类方法在处理复杂上下文和长序列时存在局限性,性能有待提升。
- 通过对比Transformer与非Transformer模型,分析其在关系分类任务中的优劣。
- 实验结果表明,Transformer模型在多个数据集上显著优于非Transformer模型,F1值提升明显。
📝 摘要(中文)
在大语言模型时代,关系抽取(RE)通过将非结构化原始文本转换为结构化数据,在信息抽取中扮演着重要角色。本文系统地比较了有Transformer和没有Transformer的深度监督学习方法的性能。我们使用了一系列非Transformer架构,如PA-LSTM、C-GCN和AGGCN,以及一系列Transformer架构,如BERT、RoBERTa和R-BERT。我们的比较包括传统的micro F1指标,以及在不同场景、不同句子长度和不同比例的训练数据集上的评估。我们的实验在TACRED、TACREV和RE-TACRED数据集上进行。结果表明,基于Transformer的模型优于非Transformer模型,micro F1得分达到80-90%,而非Transformer模型为64-67%。此外,我们简要回顾了监督关系分类的研究历程,并讨论了大型语言模型(LLM)在关系抽取中的作用和现状。
🔬 方法详解
问题定义:论文旨在解决关系分类任务中,现有非Transformer模型在处理复杂上下文和长序列时性能不足的问题。现有方法的痛点在于无法有效捕捉长距离依赖关系和上下文信息,导致分类精度较低。
核心思路:论文的核心思路是通过对比Transformer模型和非Transformer模型在关系分类任务上的性能,来验证Transformer模型在捕捉上下文信息和处理长序列方面的优势。通过实验分析,找出Transformer模型在关系分类任务中优于传统模型的关键因素。
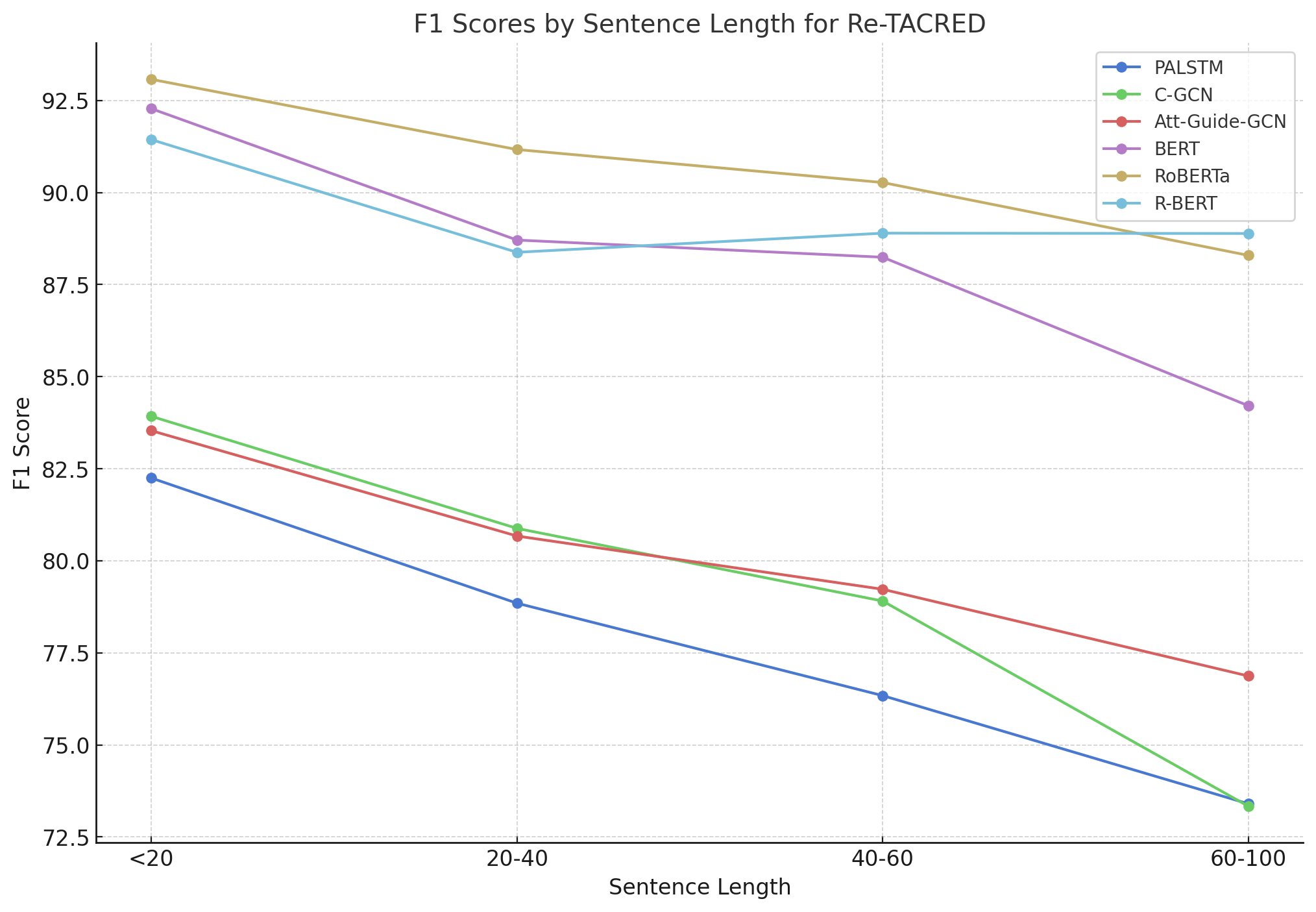
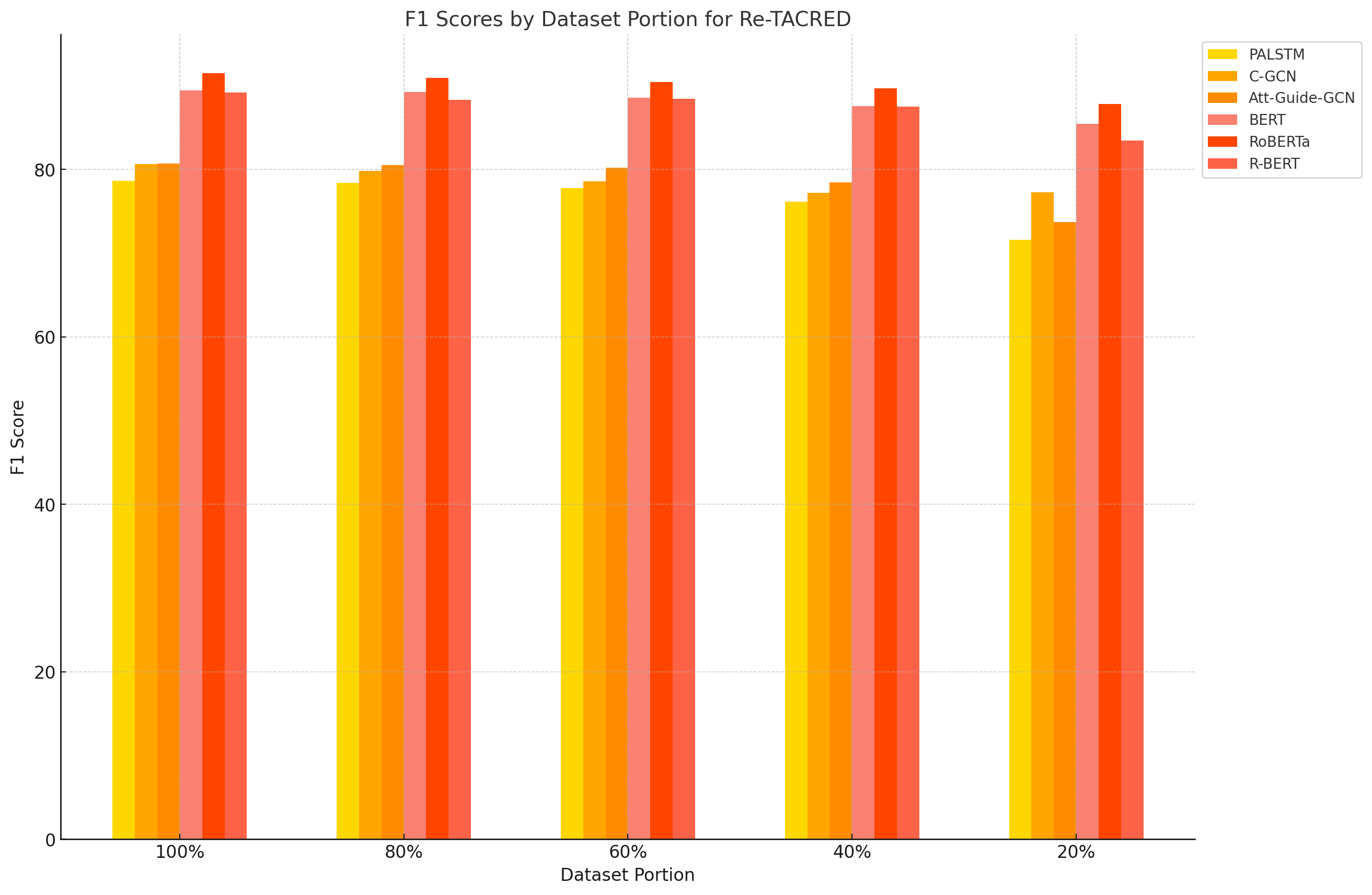
技术框架:论文采用对比实验的方法,分别使用一系列非Transformer模型(PA-LSTM、C-GCN、AGGCN)和Transformer模型(BERT、RoBERTa、R-BERT)在三个关系分类数据集(TACRED、TACREV、RE-TACRED)上进行训练和测试。评估指标包括micro F1值,并针对不同句子长度和不同训练数据比例进行分析。
关键创新:论文的关键创新在于系统性地对比了Transformer模型和非Transformer模型在关系分类任务中的性能差异,并分析了Transformer模型在上下文建模和序列处理方面的优势。通过实验数据,量化了Transformer模型相对于传统模型的提升效果。
关键设计:论文的关键设计在于选取了具有代表性的非Transformer模型和Transformer模型,并在多个数据集上进行了充分的实验。同时,论文还考虑了不同句子长度和不同训练数据比例对模型性能的影响,从而更全面地评估了模型的性能。
🖼️ 关键图片

📊 实验亮点
实验结果显示,Transformer模型在TACRED、TACREV和RE-TACRED数据集上均显著优于非Transformer模型。Transformer模型的micro F1值达到80-90%,而非Transformer模型仅为64-67%。这表明Transformer模型在关系分类任务中具有更强的上下文建模能力和序列处理能力。
🎯 应用场景
该研究成果可应用于信息抽取、知识图谱构建、问答系统等领域。通过使用Transformer模型,可以提高关系分类的准确率,从而提升信息抽取的质量,构建更准确、更全面的知识图谱,并改善问答系统的性能。未来的研究可以探索如何进一步优化Transformer模型在关系分类任务中的应用,例如通过引入领域知识或使用更先进的预训练模型。
📄 摘要(原文)
In the era of large language model, relation extraction (RE) plays an important role in information extraction through the transformation of unstructured raw text into structured data (Wadhwa et al., 2023). In this paper, we systematically compare the performance of deep supervised learning approaches without transformers and those with transformers. We used a series of non-transformer architectures such as PA-LSTM(Zhang et al., 2017), C-GCN(Zhang et al., 2018), and AGGCN(attention guide GCN)(Guo et al., 2019), and a series of transformer architectures such as BERT, RoBERTa, and R-BERT(Wu and He, 2019). Our comparison included traditional metrics like micro F1, as well as evaluations in different scenarios, varying sentence lengths, and different percentages of the dataset for training. Our experiments were conducted on TACRED, TACREV, and RE-TACRED. The results show that transformer-based models outperform non-transformer models, achieving micro F1 scores of 80-90% compared to 64-67% for non-transformer models. Additionally, we briefly review the research journey in supervised relation classification and discuss the role and current status of large language models (LLMs) in relation extraction.