Differentially-private text generation degrades output language quality
作者: Erion Çano, Ivan Habernal
分类: cs.CL, cs.AI
发布日期: 2025-09-14
备注: 20 pages, 3 figures, 35 tables
💡 一句话要点
差分隐私文本生成显著降低输出语言质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 文本生成 语言模型 隐私保护 语言质量
📋 核心要点
- 现有研究缺乏对差分隐私微调LLM后,生成文本的语言质量和下游任务效用的系统性评估。
- 该研究通过在不同隐私级别下微调多个LLM,并分析生成文本的语言特征和下游任务性能,揭示了隐私保护与语言质量之间的权衡。
- 实验结果表明,更强的隐私约束会导致生成文本的长度、语法正确性和词汇多样性显著下降,并降低下游分类任务的准确率。
📝 摘要(中文)
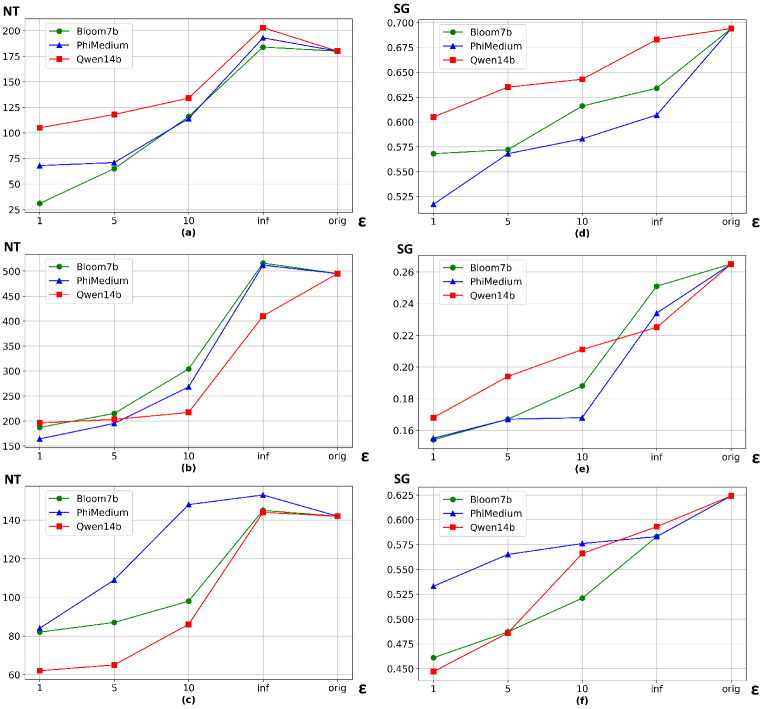
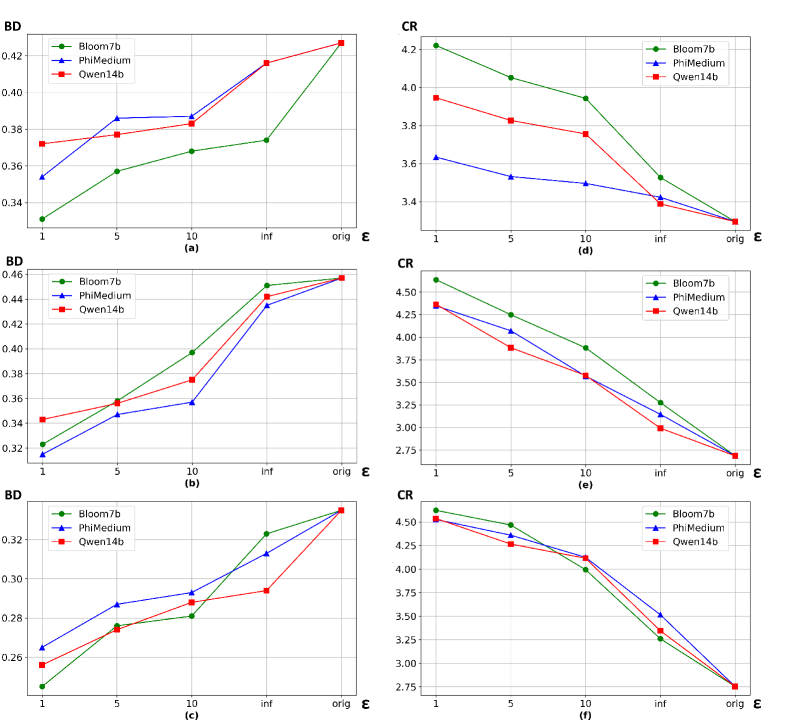
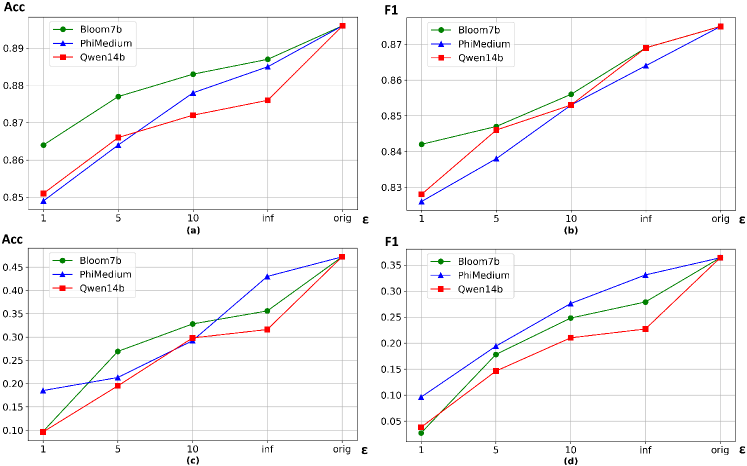
近来,通过差分隐私(DP)调整的大型语言模型(LLM)合成数据,以确保用户隐私的方法日益流行。然而,DP微调的LLM对语言质量和生成文本效用的影响尚未得到充分研究。本文通过在四个隐私级别下,使用三个语料库微调五个LLM,并评估其文本输出的长度、语法正确性和词汇多样性。此外,还通过下游分类任务(如基于书籍描述的书籍类型识别和基于口头尸检的死因识别)来探究合成输出的效用。结果表明,在更严格的隐私约束下调整的LLM生成的文本长度至少缩短77%,语法正确性至少降低9%,双字母组合多样性至少降低10%。此外,它们在下游分类任务中达到的准确率也会降低,这可能不利于生成合成数据的有用性。
🔬 方法详解
问题定义:论文旨在研究在差分隐私(DP)约束下微调大型语言模型(LLM)后,生成文本的质量下降问题。现有方法虽然关注了DP在LLM中的应用,但忽略了隐私保护对生成文本的语言质量和实用性的影响,导致合成数据可能无法有效服务于下游任务。
核心思路:核心思路是通过实验评估不同隐私级别下微调的LLM生成的文本的语言质量和下游任务性能。通过对比不同隐私级别下的生成文本的长度、语法正确性、词汇多样性以及在下游分类任务中的表现,量化隐私保护对语言质量的影响。
技术框架:整体框架包括以下步骤:1) 选择多个LLM和语料库;2) 在不同的差分隐私级别下微调这些LLM;3) 使用微调后的LLM生成文本;4) 评估生成文本的语言质量(长度、语法正确性、词汇多样性);5) 在下游分类任务中评估生成文本的效用(书籍类型识别、死因识别)。
关键创新:该研究的关键创新在于系统性地评估了差分隐私对LLM生成文本的语言质量和下游任务效用的影响,并量化了隐私保护与语言质量之间的权衡关系。以往研究主要关注DP算法本身,而忽略了其对生成文本质量的副作用。
关键设计:关键设计包括:1) 使用多种LLM(具体模型名称未知)和语料库(具体名称未知),以增加实验结果的泛化性;2) 选择多个隐私级别,以研究隐私预算对语言质量的影响;3) 使用多种评估指标,包括文本长度、语法正确性(具体评估方法未知)、词汇多样性(双字母组合多样性)以及下游分类任务的准确率;4) 选择具有代表性的下游分类任务,以评估生成文本的实用性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在更强的隐私约束下调整的LLM生成的文本长度至少缩短77%,语法正确性至少降低9%,双字母组合多样性至少降低10%。此外,它们在下游分类任务中达到的准确率也会降低,这表明隐私保护对语言质量和数据效用产生了显著的负面影响。
🎯 应用场景
该研究结果对于在需要隐私保护的场景下使用LLM生成文本具有重要意义,例如医疗记录合成、金融数据匿名化等。通过了解隐私保护对语言质量的影响,可以更好地权衡隐私保护和数据效用,并设计更有效的隐私保护机制,以生成高质量的合成数据。
📄 摘要(原文)
Ensuring user privacy by synthesizing data from large language models (LLMs) tuned under differential privacy (DP) has become popular recently. However, the impact of DP fine-tuned LLMs on the quality of the language and the utility of the texts they produce has not been investigated. In this work, we tune five LLMs with three corpora under four levels of privacy and assess the length, the grammatical correctness, and the lexical diversity of the text outputs they produce. We also probe the utility of the synthetic outputs in downstream classification tasks such as book genre recognition based on book descriptions and cause of death recognition based on verbal autopsies. The results indicate that LLMs tuned under stronger privacy constrains produce texts that are shorter by at least 77 %, that are less grammatically correct by at least 9 %, and are less diverse by at least 10 % in bi-gram diversity. Furthermore, the accuracy they reach in downstream classification tasks decreases, which might be detrimental to the usefulness of the generated synthetic data.