ReFineG: Synergizing Small Supervised Models and LLMs for Low-Resource Grounded Multimodal NER
作者: Jielong Tang, Shuang Wang, Zhenxing Wang, Jianxing Yu, Jian Yin
分类: cs.IR, cs.CL
发布日期: 2025-09-13 (更新: 2025-11-12)
备注: CCKS 2025 Shared Task Paper
💡 一句话要点
ReFineG:结合小监督模型与LLM,解决低资源GMNER问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GMNER 多模态命名实体识别 低资源学习 大语言模型 知识迁移
📋 核心要点
- 现有GMNER方法依赖大量多模态标注,在低资源场景下表现欠佳,而MLLM存在领域知识冲突。
- ReFineG通过三阶段框架,结合小监督模型和冻结的MLLM,利用数据合成、不确定性机制和上下文选择。
- 在CCKS2025 GMNER共享任务中,ReFineG取得了第二名的成绩,F1值为0.6461,验证了有效性。
📝 摘要(中文)
Grounded Multimodal Named Entity Recognition (GMNER) 通过联合检测文本提及并将它们定位到视觉区域,扩展了传统的 NER。现有的监督方法虽然性能强大,但依赖于昂贵的多模态标注,并且在低资源领域表现不佳。多模态大型语言模型 (MLLM) 显示出强大的泛化能力,但存在领域知识冲突,会为特定领域的实体生成冗余或不正确的提及。为了解决这些挑战,我们提出了 ReFineG,这是一个三阶段的协作框架,它集成了小型监督模型和冻结的 MLLM,用于低资源 GMNER。在训练阶段,一种领域感知的 NER 数据合成策略将 LLM 知识转移到具有监督训练的小型模型,同时避免领域知识冲突。在细化阶段,一种基于不确定性的机制保留来自监督模型的置信预测,并将不确定的预测委托给 MLLM。在 grounding 阶段,一种多模态上下文选择算法通过类比推理增强视觉 grounding。在 CCKS2025 GMNER 共享任务中,ReFineG 在在线排行榜上排名第二,F1 得分为 0.6461,证明了其在有限标注下的有效性。
🔬 方法详解
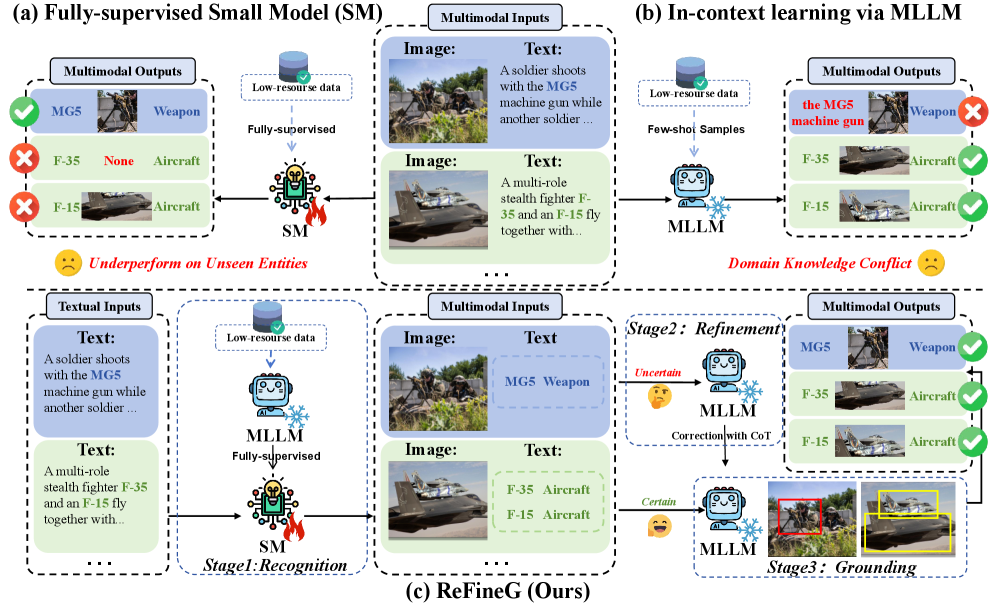
问题定义:论文旨在解决低资源场景下的Grounded Multimodal Named Entity Recognition (GMNER)问题。现有方法主要依赖大规模标注数据进行监督学习,但在标注数据稀缺的情况下,模型性能显著下降。此外,直接使用多模态大语言模型(MLLM)进行GMNER任务时,容易受到领域知识冲突的影响,产生不准确或冗余的实体提及。
核心思路:ReFineG的核心思路是结合小规模监督模型和预训练的MLLM的优势。小规模监督模型训练速度快,对特定领域数据敏感,但泛化能力有限。MLLM具有强大的知识储备和泛化能力,但可能存在领域知识冲突。ReFineG通过协同工作,利用小规模模型快速适应特定领域,并借助MLLM进行知识补充和纠正。
技术框架:ReFineG包含三个阶段:训练阶段、细化阶段和 grounding 阶段。 1. 训练阶段:利用领域感知的NER数据合成策略,将LLM的知识迁移到小规模监督模型,避免领域知识冲突。 2. 细化阶段:基于不确定性的机制,保留监督模型置信度高的预测结果,并将不确定的预测结果交给MLLM进行处理。 3. Grounding阶段:通过多模态上下文选择算法,利用类比推理增强视觉 grounding。
关键创新:ReFineG的关键创新在于协同利用小规模监督模型和MLLM,通过数据合成、不确定性机制和上下文选择,实现了低资源GMNER任务的有效解决。与现有方法相比,ReFineG不需要大规模标注数据,并且能够有效缓解MLLM的领域知识冲突问题。
关键设计: * 领域感知的数据合成策略:具体合成方法未知,但目的是避免LLM的领域知识冲突。 * 基于不确定性的细化机制:具体的不确定性度量方法未知,但用于判断监督模型预测的可靠性。 * 多模态上下文选择算法:利用类比推理增强视觉 grounding,具体实现方式未知。
🖼️ 关键图片


📊 实验亮点
ReFineG在CCKS2025 GMNER共享任务中取得了第二名的成绩,F1值为0.6461。该结果表明,ReFineG在低资源GMNER任务中具有显著的优势,能够有效利用有限的标注数据,并缓解MLLM的领域知识冲突问题,从而提高模型性能。
🎯 应用场景
ReFineG适用于医疗、金融、法律等低资源领域的GMNER任务。例如,在医疗领域,可以用于识别医学图像中的病灶区域,并将其与病例报告中的描述对应起来。该方法能够降低标注成本,提高模型在特定领域的性能,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
Grounded Multimodal Named Entity Recognition (GMNER) extends traditional NER by jointly detecting textual mentions and grounding them to visual regions. While existing supervised methods achieve strong performance, they rely on costly multimodal annotations and often underperform in low-resource domains. Multimodal Large Language Models (MLLMs) show strong generalization but suffer from Domain Knowledge Conflict, producing redundant or incorrect mentions for domain-specific entities. To address these challenges, we propose ReFineG, a three-stage collaborative framework that integrates small supervised models with frozen MLLMs for low-resource GMNER. In the Training Stage, a domain-aware NER data synthesis strategy transfers LLM knowledge to small models with supervised training while avoiding domain knowledge conflicts. In the Refinement Stage, an uncertainty-based mechanism retains confident predictions from supervised models and delegates uncertain ones to the MLLM. In the Grounding Stage, a multimodal context selection algorithm enhances visual grounding through analogical reasoning. In the CCKS2025 GMNER Shared Task, ReFineG ranked second with an F1 score of 0.6461 on the online leaderboard, demonstrating its effectiveness with limited annotations.