Quantifier Scope Interpretation in Language Learners and LLMs
作者: Shaohua Fang, Yue Li, Yan Cong
分类: cs.CL
发布日期: 2025-09-13
💡 一句话要点
研究LLM在英语和中文中量词辖域歧义的理解能力,揭示其与人类的相似性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量词辖域 自然语言理解 大型语言模型 跨语言研究 人类相似性 歧义消解 计算语言学
📋 核心要点
- 多量词语句的歧义性是自然语言理解的难点,现有方法难以准确模拟人类的理解。
- 本研究通过概率评估LLM对英语和中文量词辖域的解释,并与人类表现进行对比。
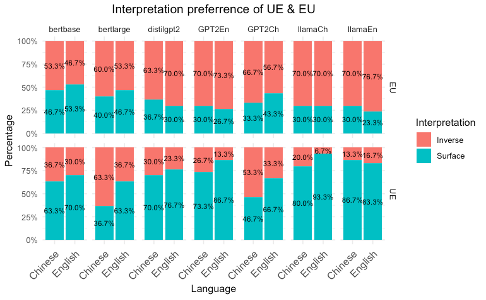
- 实验表明,LLM在表层辖域解释上与人类相似,部分模型能区分英汉逆辖域偏好。
📝 摘要(中文)
多量词语句常常导致歧义,且不同语言间存在差异。本研究采用跨语言方法,考察大型语言模型(LLM)如何处理英语和中文中的量词辖域解释,使用概率评估解释的可能性。利用人类相似性(HS)分数量化LLM在不同语言群体中模拟人类表现的程度。结果表明,大多数LLM倾向于表层辖域解释,与人类的倾向一致,而只有部分模型在逆辖域偏好上区分英语和中文,反映了与人类相似的模式。HS分数突出了LLM在逼近人类行为方面的差异,但它们与人类对齐的总体潜力值得关注。模型架构、规模,特别是模型的预训练数据语言背景,显著影响LLM逼近人类量词辖域解释的程度。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在处理包含多个量词的句子时,对量词辖域的理解能力。现有的自然语言处理方法在处理这种歧义性时,往往难以准确模拟人类的理解和偏好,尤其是在跨语言的场景下,不同语言的量词辖域解释习惯存在差异。
核心思路:论文的核心思路是通过概率评估的方式,量化LLM对不同辖域解释的偏好程度,并将其与人类的理解进行对比。通过计算人类相似性(HS)分数,来评估LLM在多大程度上能够模拟人类在量词辖域解释上的行为。这种方法能够更细致地分析LLM的理解能力,并揭示其与人类理解之间的差距。
技术框架:研究的技术框架主要包括以下几个步骤:1)构建包含多量词的英语和中文句子数据集;2)使用LLM对每个句子进行处理,并获取不同辖域解释的概率;3)收集人类对这些句子的辖域解释偏好数据;4)计算LLM和人类之间的HS分数,评估LLM的性能;5)分析不同模型架构、规模和预训练数据对LLM性能的影响。
关键创新:论文的关键创新在于采用了一种跨语言的视角,研究LLM在英语和中文两种语言中对量词辖域的理解能力。此外,使用概率评估和HS分数能够更精细地量化LLM的理解能力,并与人类行为进行对比。这种方法能够更深入地了解LLM在处理复杂语言现象时的优势和不足。
关键设计:研究中,关键的设计包括:1)精心设计的包含多量词的英语和中文句子,以覆盖不同的辖域歧义类型;2)选择具有代表性的LLM,包括不同架构、规模和预训练数据的模型;3)采用合适的方法收集人类的辖域解释偏好数据,例如问卷调查;4)使用合适的HS分数计算方法,以准确评估LLM和人类之间的相似性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,大多数LLM倾向于表层辖域解释,与人类的倾向一致。部分模型在逆辖域偏好上能够区分英语和中文,反映出与人类相似的模式。人类相似性(HS)分数突出了LLM在逼近人类行为方面的差异,但总体上LLM具有与人类对齐的潜力。模型架构、规模和预训练数据语言背景对LLM的性能有显著影响。
🎯 应用场景
该研究成果可应用于提升自然语言处理系统的理解能力,尤其是在处理复杂语句和跨语言场景时。通过了解LLM在量词辖域解释上的局限性,可以改进模型设计和训练方法,使其更准确地理解人类语言,从而提高机器翻译、智能问答等应用的性能。
📄 摘要(原文)
Sentences with multiple quantifiers often lead to interpretive ambiguities, which can vary across languages. This study adopts a cross-linguistic approach to examine how large language models (LLMs) handle quantifier scope interpretation in English and Chinese, using probabilities to assess interpretive likelihood. Human similarity (HS) scores were used to quantify the extent to which LLMs emulate human performance across language groups. Results reveal that most LLMs prefer the surface scope interpretations, aligning with human tendencies, while only some differentiate between English and Chinese in the inverse scope preferences, reflecting human-similar patterns. HS scores highlight variability in LLMs' approximation of human behavior, but their overall potential to align with humans is notable. Differences in model architecture, scale, and particularly models' pre-training data language background, significantly influence how closely LLMs approximate human quantifier scope interpretations.