Towards Automated Error Discovery: A Study in Conversational AI
作者: Dominic Petrak, Thy Thy Tran, Iryna Gurevych
分类: cs.CL, cs.AI, cs.HC, cs.LG
发布日期: 2025-09-13
备注: Accepted to EMNLP 2025 main conference
💡 一句话要点
提出SEEED框架,用于自动化发现对话AI中的未知错误,提升鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话AI 错误检测 自动化测试 表示学习 软聚类
📋 核心要点
- 现有LLM在对话AI中难以检测未明确指定的错误,例如模型更新或用户行为变化导致的。
- SEEED框架通过软聚类扩展的编码器,结合改进的损失函数和样本选择策略来发现和定义错误。
- 实验表明,SEEED在多个数据集上优于GPT-4o和Phi-4等基线,尤其在未知错误检测方面。
📝 摘要(中文)
尽管基于LLM的对话Agent表现出很强的流畅性和连贯性,但它们仍然会产生不期望的行为(错误),这些错误很难在部署期间阻止其到达用户。最近的研究利用大型语言模型(LLM)来检测错误并指导响应生成模型改进。然而,当前的LLM难以识别未在其指令中明确指定的错误,例如由响应生成模型的更新或用户行为的变化引起的错误。本文介绍了一种自动化错误发现框架,用于检测和定义对话AI中的错误,并提出SEEED(Soft Clustering Extended Encoder-Based Error Detection)作为其实现的一种基于编码器的方法。我们通过放大负样本的距离权重来增强Soft Nearest Neighbor Loss,并引入基于标签的样本排序来选择高对比度的例子,以获得更好的表示学习。SEEED在多个错误标注的对话数据集中优于调整后的基线(包括GPT-4o和Phi-4),将检测未知错误的准确率提高了高达8个百分点,并展示了对未知意图检测的强大泛化能力。
🔬 方法详解
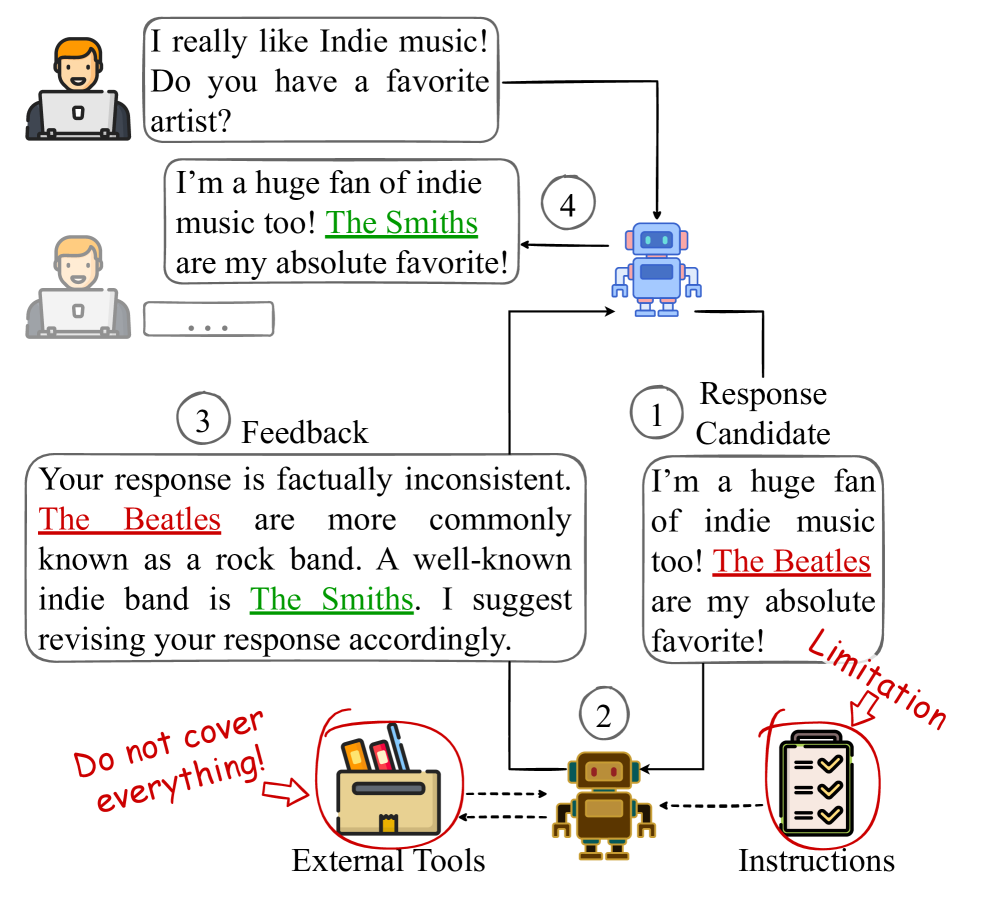
问题定义:论文旨在解决对话AI系统中自动错误发现的问题。现有方法,特别是依赖大型语言模型(LLM)的方法,在检测未明确指令指定的错误时表现不佳。这些错误可能源于响应生成模型的更新,或者用户行为模式的改变,导致系统无法有效识别和处理。
核心思路:论文的核心思路是利用基于编码器的模型,通过学习对话样本的表示,并结合软聚类的方法,自动发现和定义错误。通过增强负样本的距离权重,并选择具有高对比度的样本进行训练,提高模型对错误样本的区分能力。
技术框架:SEEED框架主要包含以下几个模块:1) 编码器:用于将对话样本编码成向量表示;2) 软聚类:利用Soft Nearest Neighbor Loss,将相似的样本聚类在一起;3) 距离加权:通过放大负样本的距离权重,增强模型对错误样本的区分能力;4) 样本排序:使用Label-Based Sample Ranking选择高对比度的样本,用于更好的表示学习。
关键创新:SEEED的关键创新在于其自动化错误发现的能力,无需预先定义具体的错误类型。它通过学习数据中的模式,自动识别和定义错误,从而能够适应模型更新和用户行为变化带来的新错误。此外,通过改进的损失函数和样本选择策略,提高了模型对错误样本的表示学习能力。
关键设计:SEEED使用了Soft Nearest Neighbor Loss,并对其进行了改进,通过引入距离权重因子来放大负样本的距离。具体来说,对于每个样本,模型会计算其与所有其他样本的距离,并根据距离权重来调整损失函数。此外,Label-Based Sample Ranking用于选择具有高对比度的样本,这些样本能够提供更多的信息,有助于模型学习更好的表示。具体的网络结构和参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片

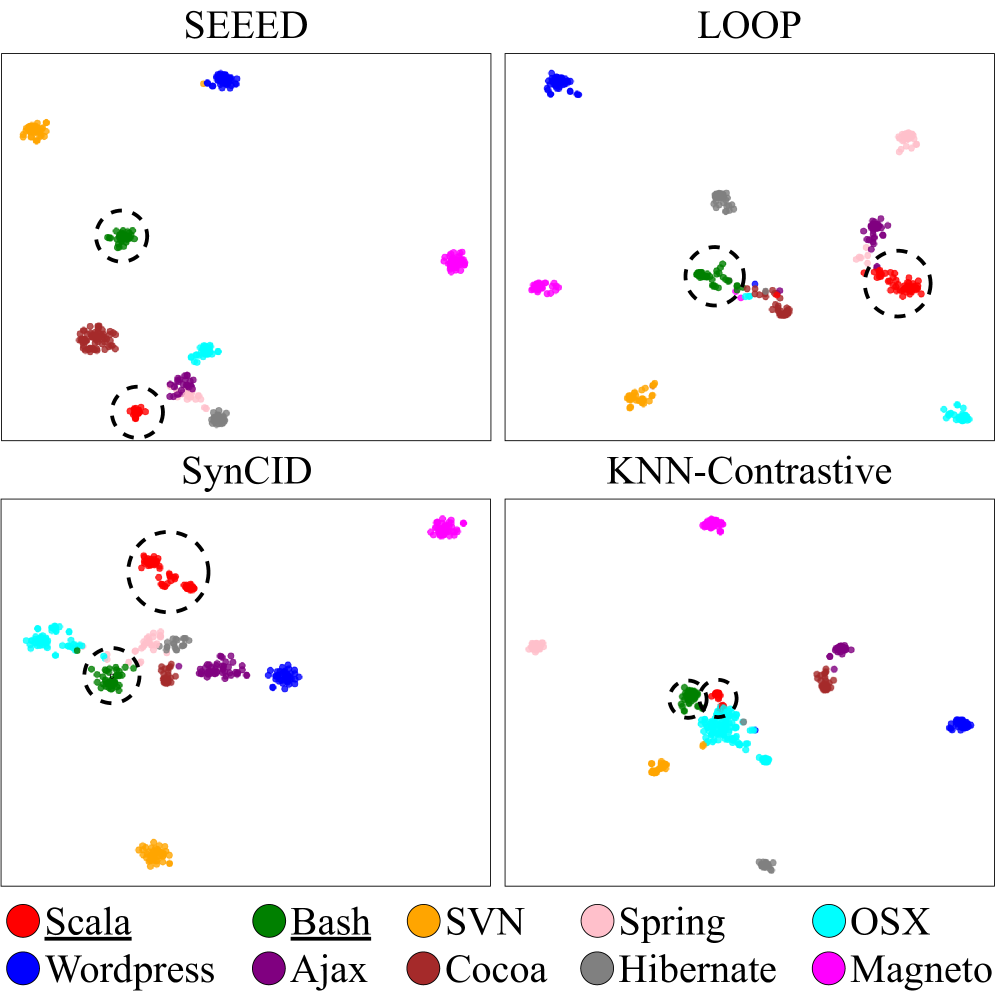
📊 实验亮点
SEEED在多个错误标注的对话数据集上进行了评估,实验结果表明,SEEED优于包括GPT-4o和Phi-4在内的基线模型。在检测未知错误方面,SEEED的准确率提高了高达8个百分点,并且展示了对未知意图检测的强大泛化能力。这些结果表明,SEEED能够有效地发现和定义对话AI系统中的未知错误。
🎯 应用场景
该研究成果可应用于对话AI系统的自动化测试和质量评估,帮助开发者快速发现和修复潜在错误,提高系统的鲁棒性和用户体验。此外,该方法还可以用于监控用户行为变化,及时发现新的错误模式,并根据用户反馈进行持续改进。该技术在智能客服、聊天机器人等领域具有广泛的应用前景。
📄 摘要(原文)
Although LLM-based conversational agents demonstrate strong fluency and coherence, they still produce undesirable behaviors (errors) that are challenging to prevent from reaching users during deployment. Recent research leverages large language models (LLMs) to detect errors and guide response-generation models toward improvement. However, current LLMs struggle to identify errors not explicitly specified in their instructions, such as those arising from updates to the response-generation model or shifts in user behavior. In this work, we introduce Automated Error Discovery, a framework for detecting and defining errors in conversational AI, and propose SEEED (Soft Clustering Extended Encoder-Based Error Detection), as an encoder-based approach to its implementation. We enhance the Soft Nearest Neighbor Loss by amplifying distance weighting for negative samples and introduce Label-Based Sample Ranking to select highly contrastive examples for better representation learning. SEEED outperforms adapted baselines -- including GPT-4o and Phi-4 -- across multiple error-annotated dialogue datasets, improving the accuracy for detecting unknown errors by up to 8 points and demonstrating strong generalization to unknown intent detection.