Judge Q: Trainable Queries for Optimized Information Retention in KV Cache Eviction
作者: Yijun Liu, Yixuan Wang, Yuzhuang Xu, Shiyu Ji, Yang Xu, Qingfu Zhu, Wanxiang Che
分类: cs.CL, cs.AI
发布日期: 2025-09-13 (更新: 2026-01-15)
备注: Accepted in AAAI 2026
💡 一句话要点
Judge Q:通过可训练查询优化KV缓存淘汰中的信息保留
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存淘汰 长序列建模 注意力机制 可训练查询 全局信息
📋 核心要点
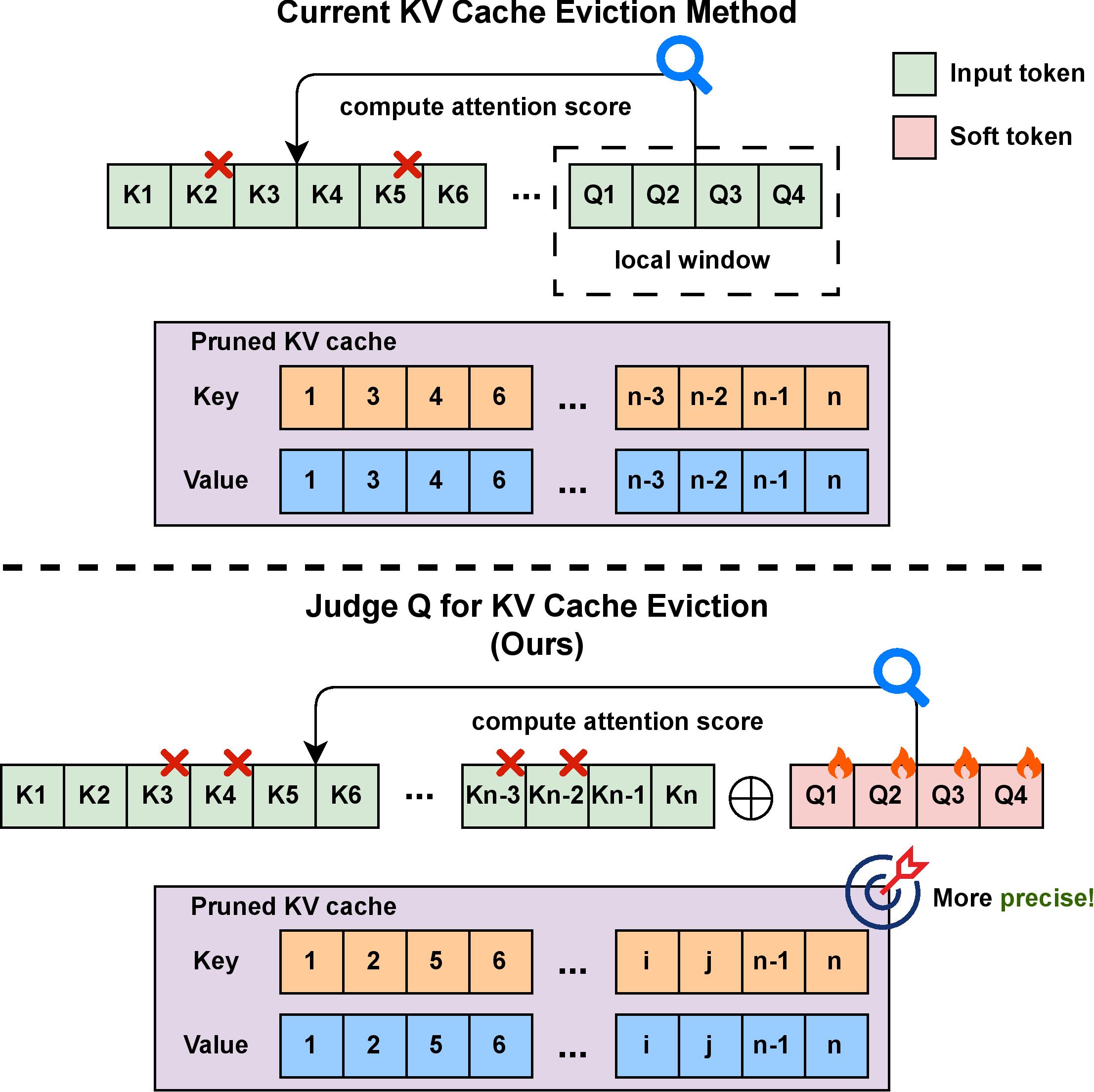
- 现有KV缓存淘汰方法侧重局部信息,忽略全局信息,导致重要信息丢失,影响解码质量。
- Judge Q通过引入可训练的软token列表,使查询能够捕获全局信息,更准确评估KV缓存的重要性。
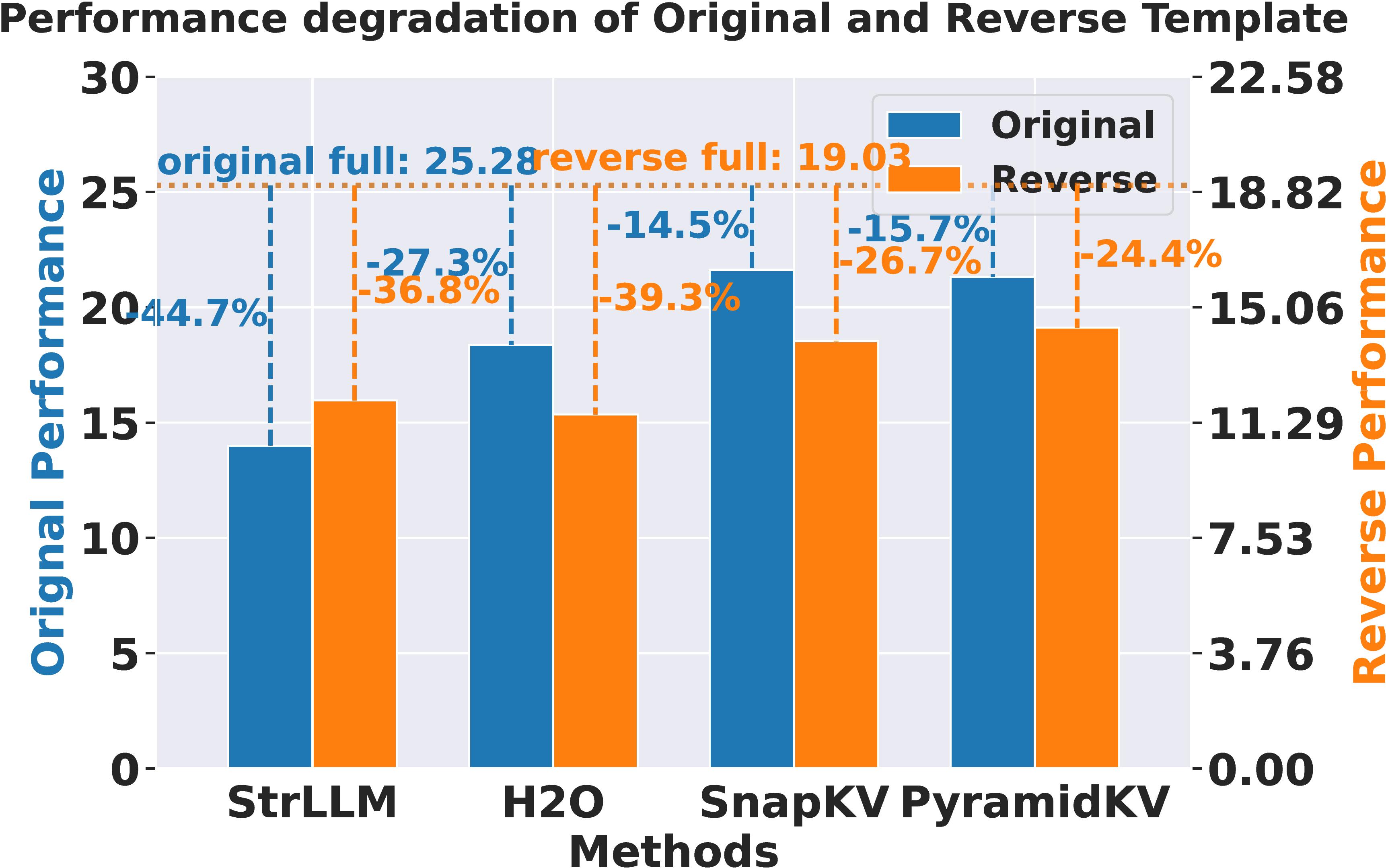
- 实验表明,Judge Q在LongBench和RULER等基准测试中,相比现有方法,性能下降更少,效果显著。
📝 摘要(中文)
大型语言模型(LLMs)利用键值(KV)缓存来存储序列处理过程中的历史信息。KV缓存的大小随着序列长度的增加而线性增长,严重影响内存使用和解码效率。现有的KV缓存淘汰方法通常使用预填充阶段的最后一个窗口作为查询,以计算KV的重要性得分进行淘汰。虽然这种方案易于实现,但它往往过度关注局部信息,可能导致忽略或遗漏关键的全局信息。为了缓解这个问题,我们提出Judge Q,一种新颖的训练方法,它结合了一个软token列表。该方法仅以较低的训练成本调整模型的嵌入层。通过将软token列表连接到输入序列的末尾,我们训练这些token的注意力图与原始输入序列的注意力图对齐,使其与实际解码token的注意力图对齐。这样,与软token对应的查询可以有效地捕获全局信息,并更好地评估KV缓存中键和值的重要性,从而在KV缓存被淘汰时保持解码质量。在相同的淘汰预算下,我们的方法比现有的淘汰方法表现出更少的性能下降。我们通过在Llama-3.1-8B-Instruct和Mistral-7B-Instruct-v0.3等模型上进行的实验验证了我们的方法,使用了包括LongBench、RULER和Needle-in-a-Haystack在内的基准。结果表明,LongBench上的改进约为1个点,RULER上的改进超过3个点。这种提出的方法可以无缝地集成到现有的开源模型中,只需极少的训练开销,从而提高KV缓存淘汰场景中的性能。
🔬 方法详解
问题定义:大型语言模型在处理长序列时,KV缓存线性增长,导致内存压力和解码效率降低。现有的KV缓存淘汰策略,如基于滑动窗口的方法,仅关注局部信息,无法有效识别和保留全局重要信息,从而影响模型性能。
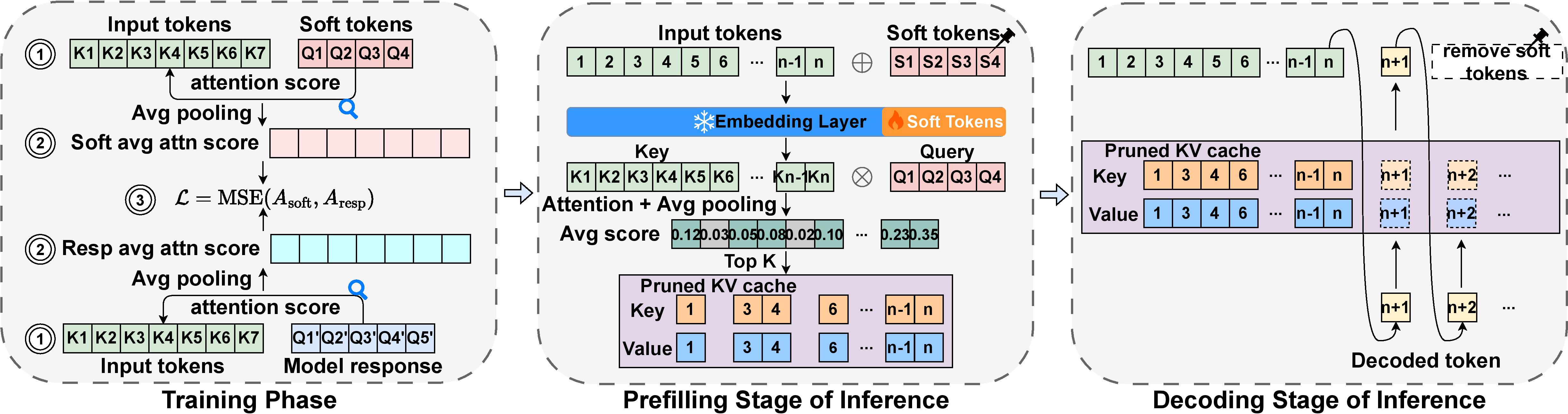
核心思路:Judge Q的核心在于引入一组可训练的“软token”作为查询,这些token通过训练学习如何关注整个输入序列,从而捕获全局信息。通过优化这些token的注意力,使其能够更好地评估KV缓存中每个键值对的重要性。
技术框架:Judge Q的训练过程包括:1) 将软token列表附加到输入序列的末尾;2) 使用语言模型处理修改后的序列;3) 计算软token对原始输入序列的注意力图;4) 使用损失函数,使软token的注意力图与实际解码token的注意力图对齐。该框架仅需调整模型的嵌入层,训练成本较低。
关键创新:Judge Q的关键创新在于使用可训练的查询(软token)来评估KV缓存的重要性,而不是依赖于固定的局部窗口。这种方法允许模型学习哪些信息对于保持解码质量至关重要,从而实现更有效的KV缓存淘汰。与现有方法相比,Judge Q能够更好地捕获全局信息,避免关键信息的遗漏。
关键设计:Judge Q的关键设计包括:1) 软token的数量:需要根据具体任务和模型大小进行调整;2) 损失函数:用于对齐软token和解码token的注意力图,可以选择KL散度等方法;3) 训练策略:采用低成本的训练方式,仅更新嵌入层参数,避免对预训练模型造成较大影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Judge Q在LongBench上取得了约1个点的性能提升,在RULER上取得了超过3个点的性能提升。与现有KV缓存淘汰方法相比,Judge Q在相同的淘汰预算下,性能下降更少。这些结果验证了Judge Q能够更有效地保留重要信息,从而提高LLM在长序列处理任务中的性能。
🎯 应用场景
Judge Q可应用于各种需要处理长序列的大型语言模型,尤其是在资源受限的环境中,如移动设备或边缘计算设备。通过优化KV缓存淘汰策略,Judge Q可以显著降低内存占用,提高解码效率,从而使LLM能够在更广泛的场景中部署和应用。该方法还有助于提升LLM在长文本理解、信息检索和对话生成等任务中的性能。
📄 摘要(原文)
Large language models (LLMs) utilize key-value (KV) cache to store historical information during sequence processing. The size of KV cache grows linearly as the length of the sequence extends, which seriously affects memory usage and decoding efficiency. Current methods for KV cache eviction typically utilize the last window from the pre-filling phase as queries to compute the KV importance scores for eviction. Although this scheme is simple to implement, it tends to overly focus on local information, potentially leading to the neglect or omission of crucial global information. To mitigate this issue, we propose Judge Q, a novel training method which incorporates a soft token list. This method only tunes the model's embedding layer at a low training cost. By concatenating the soft token list at the end of the input sequence, we train these tokens' attention map to the original input sequence to align with that of the actual decoded tokens. In this way, the queries corresponding to the soft tokens can effectively capture global information and better evaluate the importance of the keys and values within the KV cache, thus maintaining decoding quality when KV cache is evicted. Under the same eviction budget, our method exhibits less performance degradation compared to existing eviction approaches. We validate our approach through experiments conducted on models such as Llama-3.1-8B-Instruct and Mistral-7B-Instruct-v0.3, using benchmarks including LongBench, RULER, and Needle-in-a-Haystack. Results indicate an improvement of approximately 1 point on the LongBench and over 3 points on RULER. This proposed methodology can be seamlessly integrated into existing open-source models with minimal training overhead, thereby enhancing performance in KV cache eviction scenarios.