HetaRAG: Hybrid Deep Retrieval-Augmented Generation across Heterogeneous Data Stores
作者: Guohang Yan, Yue Zhang, Pinlong Cai, Ding Wang, Song Mao, Hongwei Zhang, Yaoze Zhang, Hairong Zhang, Xinyu Cai, Botian Shi
分类: cs.IR, cs.CL
发布日期: 2025-09-12
备注: 15 pages, 4 figures
🔗 代码/项目: GITHUB
💡 一句话要点
HetaRAG:跨异构数据存储的混合深度检索增强生成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 异构数据存储 混合检索 知识图谱 向量数据库
📋 核心要点
- 现有RAG系统通常是文本单一模态,依赖单一存储后端,如向量数据库,存在召回率、精度和上下文理解的局限性。
- HetaRAG提出了一种混合深度检索增强生成框架,旨在协同编排来自异构数据存储的跨模态证据,融合不同检索范例的优势。
- 该研究进行了初步探索,构建了一个初始RAG管道,旨在将向量索引、知识图谱、全文引擎和结构化数据库统一到一个检索平面中。
📝 摘要(中文)
检索增强生成(RAG)已成为缓解大型语言模型(LLM)知识幻觉和过时问题,同时保持数据安全性的主要范例。通过从私有的、特定领域的语料库中检索相关证据,并将其注入到精心设计的提示中,RAG 可以在不进行成本高昂的微调的情况下提供可信的响应。传统的 RAG 系统仅限于文本,并且通常依赖于单一的存储后端,最常见的是向量数据库。实际上,这种单片设计存在不可避免的权衡:向量搜索捕获语义相似性,但丢失了全局上下文;知识图谱擅长关系精确性,但在召回率方面表现不佳;全文索引快速且精确,但在语义上是盲目的;而诸如 MySQL 之类的关系引擎提供强大的事务保证,但没有语义理解。我们认为这些异构检索范例是互补的,并提出了一种原则性的融合方案来协同地协调它们,从而减轻任何单一模态的弱点。在这项工作中,我们介绍了 HetaRAG,一种混合的、深度检索增强生成框架,它协调来自异构数据存储的跨模态证据。我们计划设计一个系统,将向量索引、知识图谱、全文引擎和结构化数据库统一到一个检索平面中,动态地路由和融合证据,以最大限度地提高召回率、精确度和上下文保真度。为了实现这一设计目标,我们进行了初步探索并构建了一个初始 RAG 管道;本技术报告提供了一个简要概述。部分代码可在 https://github.com/KnowledgeXLab/HetaRAG 获取。
🔬 方法详解
问题定义:现有RAG系统在处理复杂知识检索时面临挑战。单一的向量数据库虽然能捕捉语义相似性,但缺乏全局上下文;知识图谱擅长关系推理,但召回率较低;全文索引快速但缺乏语义理解;关系数据库提供事务保证,但缺乏语义理解能力。这些局限性导致RAG系统在精度、召回率和上下文保真度方面存在瓶颈。
核心思路:HetaRAG的核心思路是将多种异构数据存储和检索方法进行融合,利用它们各自的优势来互补彼此的不足。通过将向量索引、知识图谱、全文引擎和结构化数据库整合到一个统一的检索平面中,HetaRAG旨在实现更全面、更准确的知识检索。这种混合方法能够提高召回率、精确度和上下文保真度。
技术框架:HetaRAG的整体架构包含多个模块,包括:1) 异构数据存储接口:用于连接和访问不同类型的数据库和索引;2) 检索模块:包含向量检索、知识图谱查询、全文搜索和结构化数据查询等多种检索方法;3) 证据融合模块:用于将来自不同检索源的证据进行整合和排序;4) 提示工程模块:用于构建合适的提示,将检索到的证据注入到LLM中;5) 生成模块:利用LLM生成最终的答案。整个流程是动态的,根据不同的查询和上下文,选择合适的检索方法和证据融合策略。
关键创新:HetaRAG的最重要的创新点在于其混合检索的方法。与传统的RAG系统只依赖单一的检索方法不同,HetaRAG能够根据查询的特点,动态地选择和组合不同的检索方法,从而实现更全面和准确的知识检索。这种混合方法能够有效地提高RAG系统的性能,尤其是在处理复杂的、需要多方面知识的查询时。
关键设计:目前的技术报告是初步探索,没有给出具体的参数设置、损失函数、网络结构等技术细节。未来的研究可能会涉及如何设计有效的证据融合策略,如何优化不同检索方法的权重,以及如何利用LLM进行更有效的上下文理解和答案生成。这些都是HetaRAG框架中需要进一步研究和优化的关键设计。
🖼️ 关键图片
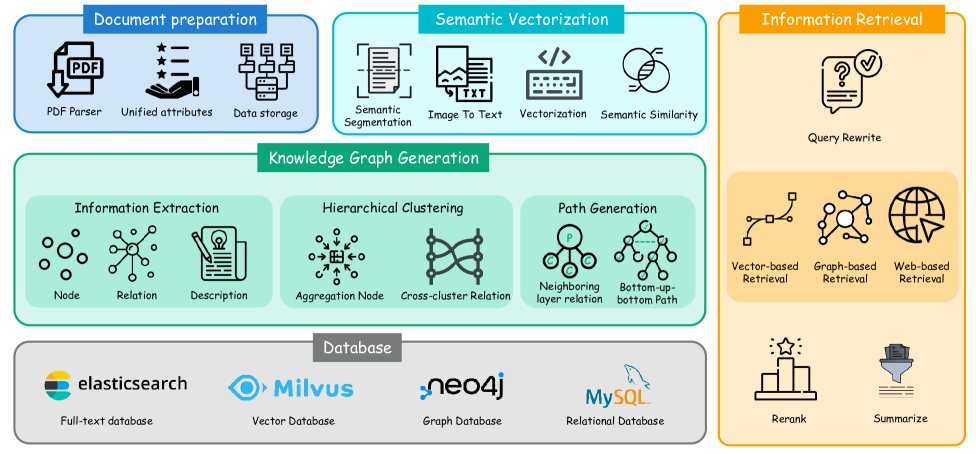
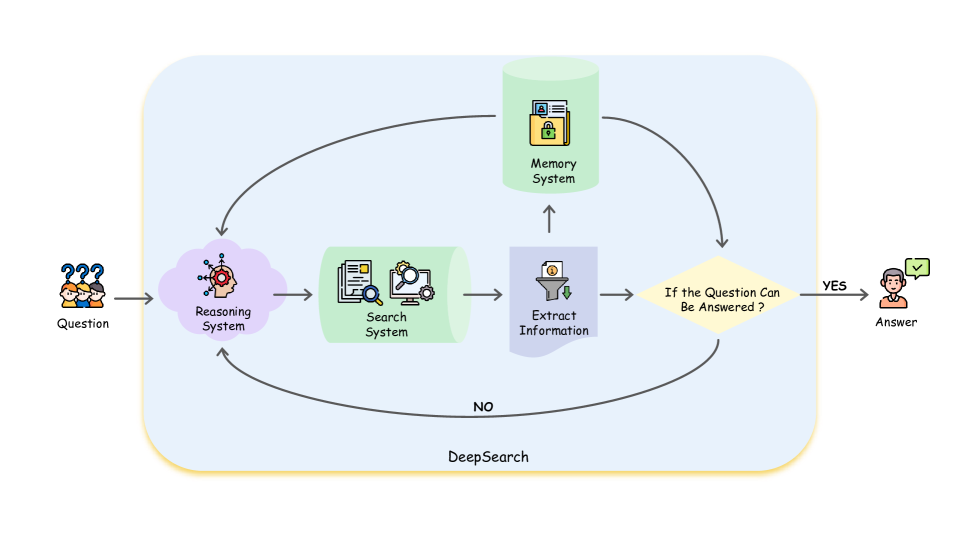

📊 实验亮点
该技术报告介绍了HetaRAG的初步探索和设计理念,旨在构建一个能够融合异构数据源的RAG系统。虽然目前没有具体的实验结果,但其提出的混合检索方法具有很大的潜力,有望在未来的研究中取得显著的性能提升。代码已开源,为后续研究提供了基础。
🎯 应用场景
HetaRAG具有广泛的应用前景,例如智能客服、金融分析、医疗诊断等领域。它可以帮助企业构建更智能、更可靠的知识库系统,提高工作效率和服务质量。未来,HetaRAG有望成为企业级RAG系统的核心技术,推动人工智能在各行业的应用。
📄 摘要(原文)
Retrieval-augmented generation (RAG) has become a dominant paradigm for mitigating knowledge hallucination and staleness in large language models (LLMs) while preserving data security. By retrieving relevant evidence from private, domain-specific corpora and injecting it into carefully engineered prompts, RAG delivers trustworthy responses without the prohibitive cost of fine-tuning. Traditional retrieval-augmented generation (RAG) systems are text-only and often rely on a single storage backend, most commonly a vector database. In practice, this monolithic design suffers from unavoidable trade-offs: vector search captures semantic similarity yet loses global context; knowledge graphs excel at relational precision but struggle with recall; full-text indexes are fast and exact yet semantically blind; and relational engines such as MySQL provide strong transactional guarantees but no semantic understanding. We argue that these heterogeneous retrieval paradigms are complementary, and propose a principled fusion scheme to orchestrate them synergistically, mitigating the weaknesses of any single modality. In this work we introduce HetaRAG, a hybrid, deep-retrieval augmented generation framework that orchestrates cross-modal evidence from heterogeneous data stores. We plan to design a system that unifies vector indices, knowledge graphs, full-text engines, and structured databases into a single retrieval plane, dynamically routing and fusing evidence to maximize recall, precision, and contextual fidelity. To achieve this design goal, we carried out preliminary explorations and constructed an initial RAG pipeline; this technical report provides a brief overview. The partial code is available at https://github.com/KnowledgeXLab/HetaRAG.