On LLM-Based Scientific Inductive Reasoning Beyond Equations
作者: Brian S. Lin, Jiaxin Yuan, Zihan Zhou, Shouli Wang, Shuo Wang, Cunliang Kong, Qi Shi, Yuxuan Li, Liner Yang, Zhiyuan Liu, Maosong Sun
分类: cs.CL, cs.AI
发布日期: 2025-09-12
备注: 24 pages
💡 一句话要点
提出SIRBench-V1基准,评估LLM在科学场景下超越方程的归纳推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 归纳推理 科学发现 基准测试 LLM SIRBench-V1 非方程规则 科学推理
📋 核心要点
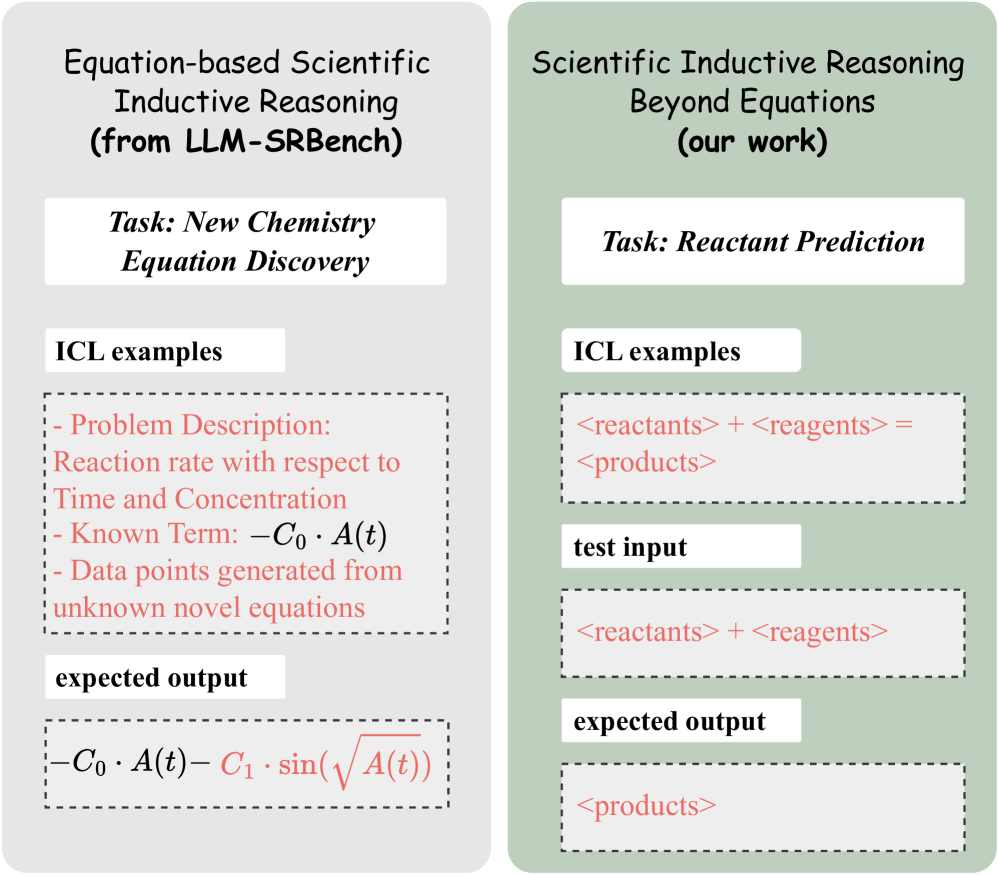
- 现有LLM归纳推理研究主要关注数学方程,缺乏对科学场景下非方程规则的探索。
- 论文提出基于LLM的科学归纳推理任务,模拟人类科学发现过程,更贴近实际应用。
- 构建SIRBench-V1基准,实验表明现有LLM在此任务上表现不佳,有待进一步提升。
📝 摘要(中文)
随着大型语言模型(LLM)日益展现出类人能力,一个根本性问题浮出水面:我们如何使LLM能够在全新的环境中,从有限的示例中学习潜在的模式并有效地应用它们?这个问题是LLM归纳推理能力的核心。现有的基于LLM的归纳推理研究可以根据底层规则是否可以通过显式数学方程表达来大致分类。然而,许多最近的“超越方程”类别研究强调规则设计,而没有将其置于特定场景中。受到归纳推理与人类科学发现之间相似性的启发,我们提出了基于LLM的科学归纳推理(LLM-Based Scientific Inductive Reasoning Beyond Equations)任务,并引入了一个新的基准SIRBench-V1,以评估LLM在科学环境中的归纳推理能力。我们的实验结果表明,当前的LLM仍然难以胜任这项任务,突显了其难度以及该领域进一步发展的必要性。
🔬 方法详解
问题定义:论文旨在解决LLM在科学领域中进行超越方程的归纳推理的问题。现有方法主要集中在可以通过数学方程表达的规则上,忽略了科学研究中大量无法用简单方程描述的复杂关系和模式。这限制了LLM在实际科学发现中的应用潜力。
核心思路:论文的核心思路是将LLM的归纳推理能力与人类的科学发现过程联系起来。通过模拟科学家从实验数据中推导出科学规律的过程,来评估LLM在科学场景下的归纳推理能力。这种方法更贴近实际科研场景,能够更有效地评估LLM的泛化能力。
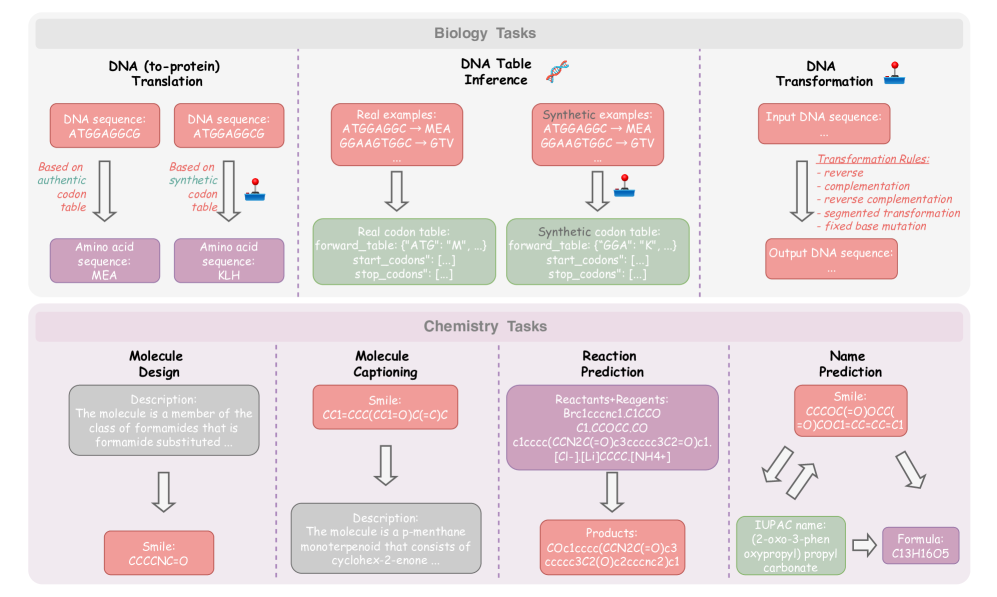
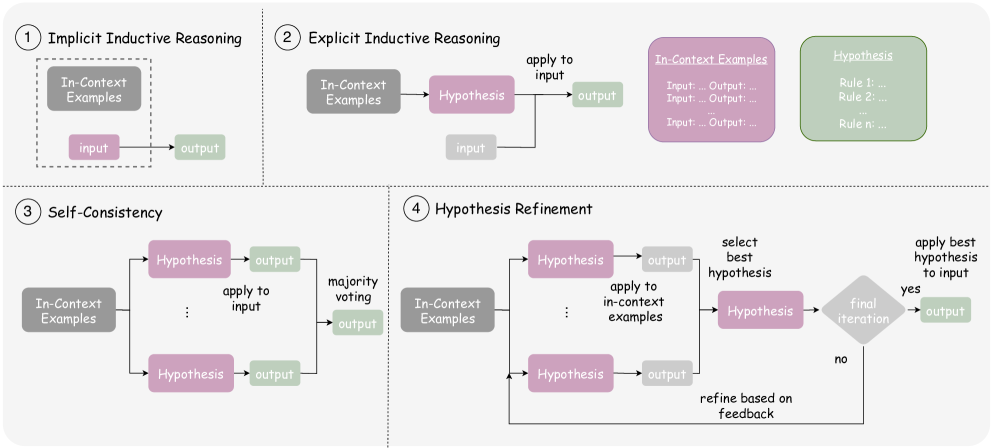
技术框架:论文构建了一个新的基准测试SIRBench-V1,用于评估LLM在科学归纳推理任务上的表现。该基准包含多个科学场景,每个场景都包含一组输入-输出示例,LLM需要根据这些示例推导出潜在的科学规律。整体流程包括:1) 定义科学场景和规则;2) 生成输入-输出示例;3) 使用LLM进行推理;4) 评估LLM的推理结果。
关键创新:该论文的关键创新在于提出了一个更贴近实际科学研究的归纳推理任务,并构建了相应的基准测试。与以往的研究相比,该任务更加关注非方程规则的推理,能够更全面地评估LLM在科学领域的应用潜力。
关键设计:SIRBench-V1基准的设计考虑了多个因素,包括场景的多样性、规则的复杂性和评估的准确性。具体来说,场景涵盖了物理、化学、生物等多个学科,规则既包括简单的线性关系,也包括复杂的非线性关系。评估指标包括准确率、召回率和F1值等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,当前主流LLM在SIRBench-V1基准上的表现远低于人类水平,表明在科学归纳推理方面仍存在显著差距。例如,在某些复杂场景下,LLM的准确率仅为个位数,与随机猜测相差无几。这突显了该任务的挑战性,并为未来的研究指明了方向。
🎯 应用场景
该研究成果可应用于辅助科学发现、自动化实验设计、以及科学知识图谱构建等领域。通过提升LLM在科学场景下的归纳推理能力,可以加速科研进程,降低科研成本,并为科学家提供更强大的研究工具。未来,该研究有望推动人工智能在科学领域的更广泛应用。
📄 摘要(原文)
As large language models (LLMs) increasingly exhibit human-like capabilities, a fundamental question emerges: How can we enable LLMs to learn the underlying patterns from limited examples in entirely novel environments and apply them effectively? This question is central to the ability of LLMs in inductive reasoning. Existing research on LLM-based inductive reasoning can be broadly categorized based on whether the underlying rules are expressible via explicit mathematical equations. However, many recent studies in the beyond-equations category have emphasized rule design without grounding them in specific scenarios. Inspired by the parallels between inductive reasoning and human scientific discovery, we propose the task of LLM-Based Scientific Inductive Reasoning Beyond Equations and introduce a new benchmark, SIRBench-V1, to evaluate the inductive reasoning abilities of LLMs in scientific settings. Our experimental results show that current LLMs still struggle with this task, underscoring its difficulty and the need for further advancement in this area.