Unsupervised Hallucination Detection by Inspecting Reasoning Processes
作者: Ponhvoan Srey, Xiaobao Wu, Anh Tuan Luu
分类: cs.CL, cs.AI
发布日期: 2025-09-12
备注: To appear in EMNLP 2025
💡 一句话要点
提出IRIS框架,通过检查LLM推理过程实现无监督幻觉检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无监督学习 幻觉检测 大型语言模型 推理过程 内部表征
📋 核心要点
- 现有无监督幻觉检测方法依赖与事实无关的代理信号,泛化能力受限。
- IRIS框架通过提示LLM验证陈述真实性,利用其内部表征和不确定性进行幻觉检测。
- 实验表明,IRIS在无监督幻觉检测任务中优于现有方法,且计算成本较低。
📝 摘要(中文)
无监督幻觉检测旨在无需标注数据的情况下,识别大型语言模型(LLM)生成的幻觉内容。尽管无监督方法因避免了耗时的人工标注而日益普及,但它们通常依赖于与事实正确性无关的代理信号。这种错位导致检测探针偏向于表面或非真值相关的方面,限制了跨数据集和场景的泛化能力。为了克服这些限制,我们提出了IRIS,一个无监督幻觉检测框架,利用事实正确性内在的内部表征。IRIS提示LLM仔细验证给定陈述的真实性,并获得其上下文嵌入作为训练的信息性特征。同时,每个响应的不确定性被认为是真实性的软伪标签。实验结果表明,IRIS始终优于现有的无监督方法。我们的方法是完全无监督的,计算成本低,即使在少量训练数据下也能很好地工作,使其适用于实时检测。
🔬 方法详解
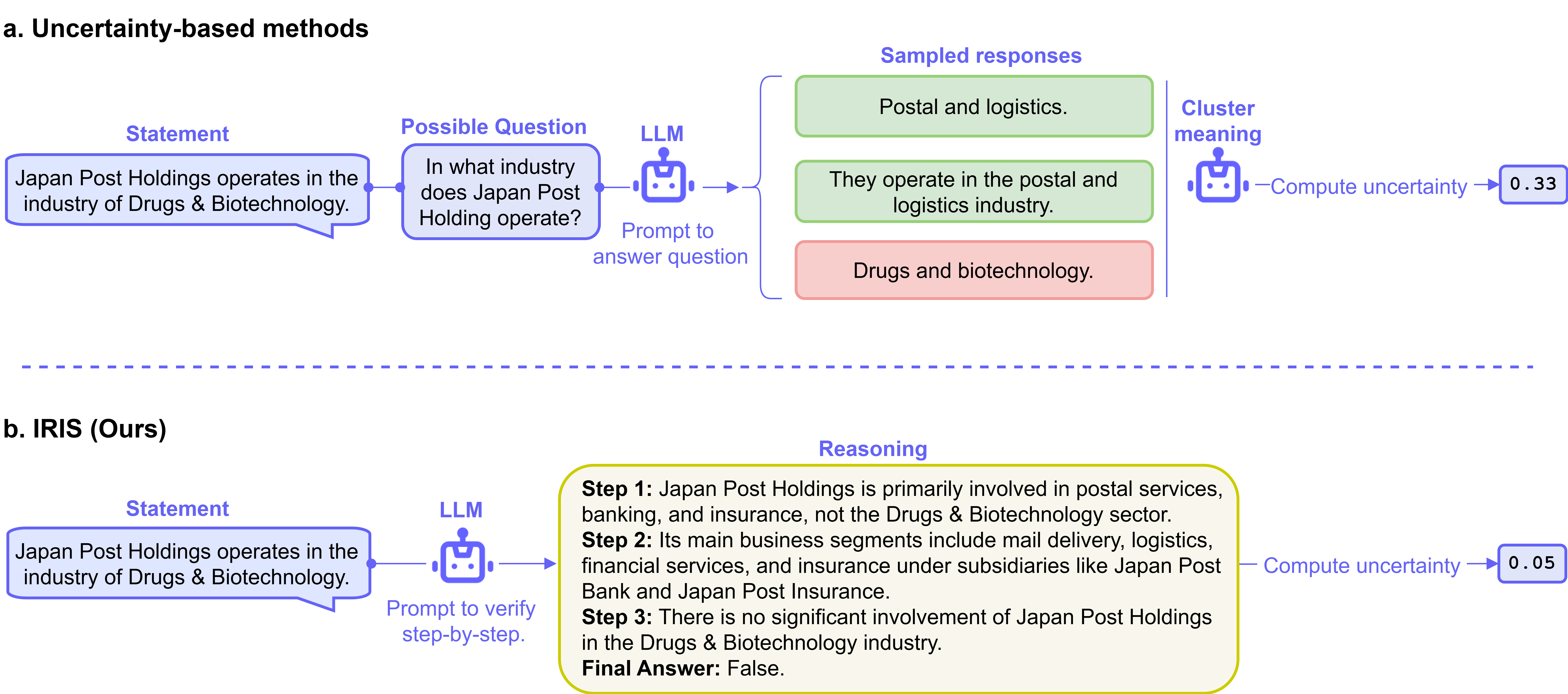
问题定义:论文旨在解决大型语言模型(LLM)中无监督幻觉检测的问题。现有无监督方法的痛点在于,它们依赖于与事实正确性无关的代理信号,导致检测器偏向于表面或非真值相关的特征,从而限制了其在不同数据集和场景下的泛化能力。这些方法无法真正理解和评估LLM生成内容的真实性,而是依赖于一些间接的指标。
核心思路:论文的核心思路是利用LLM自身在进行推理和验证过程中的内部表征,这些表征更直接地反映了LLM对事实的理解和判断。通过提示LLM仔细验证给定陈述的真实性,并提取其上下文嵌入作为特征,可以更有效地捕捉与事实正确性相关的信号。此外,论文还利用LLM响应的不确定性作为软伪标签,进一步指导模型的训练。这样设计的目的是使检测器能够学习到更本质的、与事实相关的特征,从而提高幻觉检测的准确性和泛化能力。
技术框架:IRIS框架主要包含以下几个阶段: 1. 提示LLM进行验证:给定一个陈述,使用特定的prompt提示LLM仔细验证其真实性。 2. 提取上下文嵌入:从LLM的内部提取上下文嵌入,作为信息性特征。 3. 生成软伪标签:利用LLM响应的不确定性,生成关于陈述真实性的软伪标签。 4. 训练幻觉检测器:使用提取的特征和软伪标签,训练一个无监督的幻觉检测器。
关键创新:IRIS最重要的技术创新点在于,它利用了LLM自身在推理过程中的内部表征,而不是依赖于外部的代理信号。这种方法更直接地捕捉了与事实正确性相关的信号,从而提高了幻觉检测的准确性和泛化能力。与现有方法的本质区别在于,IRIS关注的是LLM内部的推理过程,而不是外部的表面特征。
关键设计:论文的关键设计包括: * Prompt设计:设计特定的prompt,引导LLM进行有效的真实性验证。 * 不确定性度量:使用适当的方法度量LLM响应的不确定性,例如通过softmax输出的熵。 * 软伪标签生成:将不确定性转化为软伪标签,用于指导模型的训练。 * 特征提取位置:选择合适的LLM内部层提取上下文嵌入,以获得最有效的特征表示。
🖼️ 关键图片

📊 实验亮点
实验结果表明,IRIS在无监督幻觉检测任务中始终优于现有的无监督方法。具体性能数据在论文中给出,但摘要中未明确提及具体的提升幅度。该方法在计算成本较低的情况下,即使在少量训练数据下也能很好地工作,使其适用于实时检测。
🎯 应用场景
该研究成果可广泛应用于各种需要大型语言模型生成内容的场景,例如智能客服、新闻生成、内容创作等。通过实时检测和过滤LLM生成的幻觉内容,可以提高生成内容的质量和可信度,避免错误信息的传播,从而提升用户体验和降低潜在风险。未来,该技术有望与LLM更好地集成,实现更智能、更可靠的内容生成。
📄 摘要(原文)
Unsupervised hallucination detection aims to identify hallucinated content generated by large language models (LLMs) without relying on labeled data. While unsupervised methods have gained popularity by eliminating labor-intensive human annotations, they frequently rely on proxy signals unrelated to factual correctness. This misalignment biases detection probes toward superficial or non-truth-related aspects, limiting generalizability across datasets and scenarios. To overcome these limitations, we propose IRIS, an unsupervised hallucination detection framework, leveraging internal representations intrinsic to factual correctness. IRIS prompts the LLM to carefully verify the truthfulness of a given statement, and obtain its contextualized embedding as informative features for training. Meanwhile, the uncertainty of each response is considered a soft pseudolabel for truthfulness. Experimental results demonstrate that IRIS consistently outperforms existing unsupervised methods. Our approach is fully unsupervised, computationally low cost, and works well even with few training data, making it suitable for real-time detection.