LLM-JEPA: Large Language Models Meet Joint Embedding Predictive Architectures
作者: Hai Huang, Yann LeCun, Randall Balestriero
分类: cs.CL, cs.AI
发布日期: 2025-09-11 (更新: 2025-10-07)
🔗 代码/项目: GITHUB
💡 一句话要点
提出LLM-JEPA,将联合嵌入预测架构应用于LLM预训练和微调,显著提升性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 联合嵌入预测架构 预训练 微调 嵌入空间 对比学习 自然语言处理
📋 核心要点
- 现有LLM训练依赖输入空间重建,但视觉领域JEPA在嵌入空间表现更优,存在领域差异。
- LLM-JEPA将JEPA引入LLM,通过联合嵌入预测提升模型性能,适用于预训练和微调。
- 实验表明,LLM-JEPA在多个数据集和模型上显著优于标准训练目标,且更具鲁棒性。
📝 摘要(中文)
大型语言模型(LLM)的预训练、微调和评估依赖于输入空间重建和生成能力。然而,在视觉领域,基于联合嵌入预测架构(JEPA)的嵌入空间训练目标远优于其输入空间对应方法。语言和视觉在训练方式上的这种不匹配引出了一个自然的问题:语言训练方法能否从视觉方法中学习一些技巧?缺乏JEPA风格的LLM证明了为语言设计此类目标的挑战性。本文提出了LLM-JEPA,这是朝着这个方向迈出的第一步,它是一种基于JEPA的LLM解决方案,适用于微调和预训练。LLM-JEPA能够显著优于标准LLM训练目标,并且对过拟合具有鲁棒性。这些发现在多个数据集(NL-RX、GSM8K、Spider、RottenTomatoes)以及来自Llama3、OpenELM、Gemma2和Olmo系列的各种模型中得到证实。
🔬 方法详解
问题定义:现有LLM的训练主要依赖于输入空间的重建和生成能力,这种方式可能不是最优的。视觉领域的研究表明,基于联合嵌入预测架构(JEPA)的嵌入空间训练目标通常优于输入空间的方法。因此,如何将JEPA的优势引入到LLM的训练中,克服语言和视觉之间的差异,是一个亟待解决的问题。
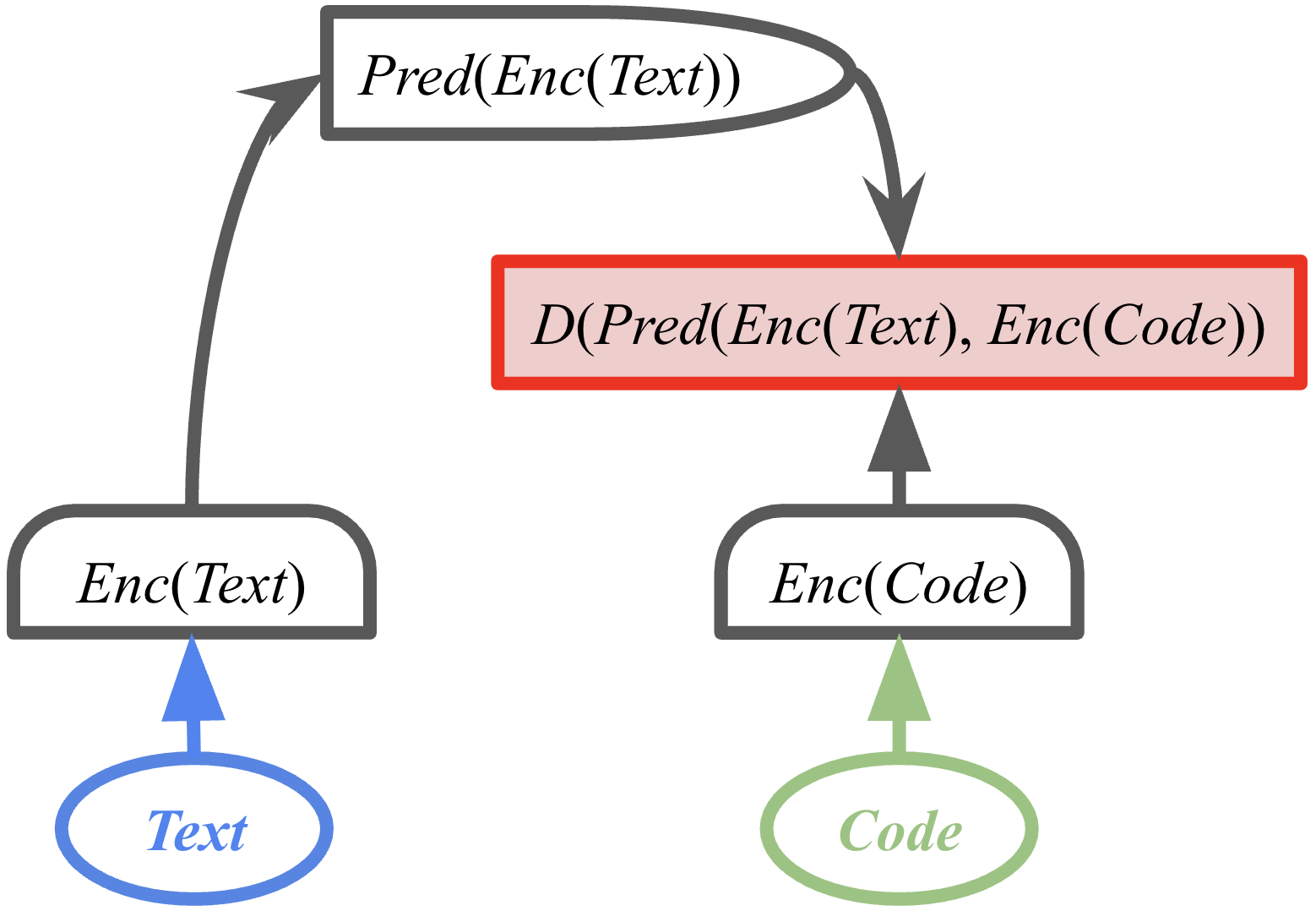
核心思路:LLM-JEPA的核心思路是将JEPA的思想应用于LLM的训练中。具体来说,它不再直接在输入空间进行重建,而是在嵌入空间学习数据的表示,并通过预测不同上下文的嵌入向量来训练模型。这种方式可以更好地捕捉数据之间的语义关系,并提高模型的泛化能力。
技术框架:LLM-JEPA的整体框架包括以下几个主要模块:1) 输入编码器:将输入文本编码为嵌入向量。2) 上下文编码器:根据不同的上下文信息,生成不同的上下文嵌入向量。3) 预测器:根据上下文嵌入向量,预测目标嵌入向量。4) 损失函数:用于衡量预测结果与目标嵌入向量之间的差异,并指导模型的训练。整个流程可以用于预训练和微调阶段。
关键创新:LLM-JEPA最重要的技术创新点是将JEPA的思想成功地应用于LLM的训练中。与传统的LLM训练方法相比,LLM-JEPA不再依赖于输入空间的重建,而是在嵌入空间学习数据的表示,并通过预测不同上下文的嵌入向量来训练模型。这种方式可以更好地捕捉数据之间的语义关系,并提高模型的泛化能力。
关键设计:LLM-JEPA的关键设计包括:1) 如何选择合适的上下文信息,例如,可以使用滑动窗口或注意力机制来选择上下文。2) 如何设计预测器,例如,可以使用多层感知机或Transformer结构。3) 如何设计损失函数,例如,可以使用对比损失或InfoNCE损失。具体的参数设置、网络结构和损失函数需要根据具体的任务和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
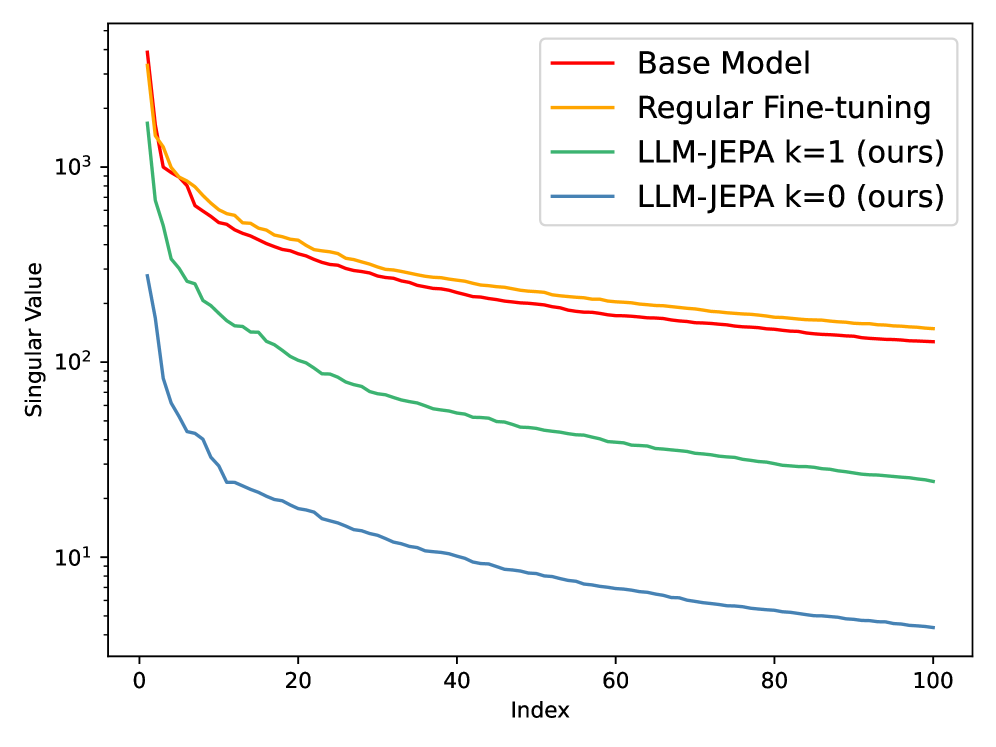
实验结果表明,LLM-JEPA在多个数据集(NL-RX、GSM8K、Spider、RottenTomatoes)以及来自Llama3、OpenELM、Gemma2和Olmo系列的各种模型上,均显著优于标准LLM训练目标。例如,在某些任务上,LLM-JEPA的性能提升超过10%。此外,LLM-JEPA还表现出更强的鲁棒性,不易过拟合。
🎯 应用场景
LLM-JEPA具有广泛的应用前景,可以应用于各种自然语言处理任务,例如文本分类、文本生成、机器翻译等。通过提高LLM的性能和泛化能力,LLM-JEPA可以为这些任务带来显著的改进。此外,LLM-JEPA还可以用于开发更智能的对话系统和更强大的知识图谱,从而推动人工智能技术的发展。
📄 摘要(原文)
Large Language Model (LLM) pretraining, finetuning, and evaluation rely on input-space reconstruction and generative capabilities. Yet, it has been observed in vision that embedding-space training objectives, e.g., with Joint Embedding Predictive Architectures (JEPAs), are far superior to their input-space counterpart. That mismatch in how training is achieved between language and vision opens up a natural question: {\em can language training methods learn a few tricks from the vision ones?} The lack of JEPA-style LLM is a testimony of the challenge in designing such objectives for language. In this work, we propose a first step in that direction where we develop LLM-JEPA, a JEPA based solution for LLMs applicable both to finetuning and pretraining. Thus far, LLM-JEPA is able to outperform the standard LLM training objectives by a significant margin across models, all while being robust to overfiting. Those findings are observed across numerous datasets (NL-RX, GSM8K, Spider, RottenTomatoes) and various models from the Llama3, OpenELM, Gemma2 and Olmo families. Code: https://github.com/rbalestr-lab/llm-jepa.